
Om du vill skapa komplexa statistiska eller tekniska analyser kan du spara både tid och kraft genom att använda Analysis ToolPak. Du anger bara informationen och parametrarna för varje analys så används lämpliga statistiska eller tekniska makrofunktioner automatiskt för att beräkna och visa resultatet i en utdatatabell. Med vissa verktyg kan du förutom utdatatabellerna skapa diagram.
Dataanalysfunktionerna kan användas endast i ett kalkylblad i taget. När du utför dataanalyser i grupperade kalkylblad visas resultatet i det första kalkylbladet och tomma formaterade tabeller visas i de andra kalkylbladen. Använd analysverktyget i varje kalkylblad om du vill utföra dataanalyser i alla kalkylblad.
Analysis ToolPak innehåller de verktyg som beskrivs i följande avsnitt. Om du vill få åtkomst till dessa verktyg klickar du på Dataanalys i gruppen Analys på fliken Data. Om kommandot Dataanalys inte är tillgängligt måste du läsa in tilläggsprogrammet Analysis ToolPak.
-
Klicka på fliken Arkiv, klicka på Alternativ och klicka sedan på kategorinTillägg.
-
I rutan Hantera väljer du Excel-tillägg och klickar sedan på OK.
Om du använder Excel för Mac öppnar du Arkiv-menyn och går till Verktyg > Excel-tillägg.
-
I Tillägg markerar du kryssrutan Analysis ToolPak och klickar sedan på OK.
-
Om Analysis ToolPak inte visas i rutan Tillgängliga tilläggsmakron klickar du på Bläddra och letar upp tillägget.
-
Om ett meddelande visas som anger att Analysis ToolPak inte är installerat på datorn klickar du på Ja för att installera tillägget.
-
Obs!: Om du vill inkludera VBA-funktioner (Visual Basic for Application) för Analysis ToolPak kan du läsa in tilläggsprogrammet Analysis ToolPak - VBA på samma sätt som du läser in Analysis ToolPak. Markera kryssrutan Analysis ToolPak - VBA i rutan Tillgängliga tilläggsmakron.
Med Anova-analysverktygen kan du utföra olika typer av variansanalyser. Vilket verktyg du bör använda beror på antalet faktorer och antalet befintliga observationer för de populationer som du vill undersöka.
Anova: En faktor
Det här verktyget utför en enkel analys av variansen för data för två eller fler exempel. Analysen ger ett test av hypotesen att varje urval hämtas från samma underliggande sannolikhetsfördelning mot den alternativa hypotesen att underliggande sannolikhetsfördelningar inte är desamma för alla prover. Om det bara finns två exempel kan du använda kalkylbladsfunktionen T.TEST. Med fler än två prover finns det ingen bekväm generalisering av T.TEST, och Single Factor Anova-modellen kan anropas istället.
Anova: Två faktorer med reproducering
Det här analysverktyget är användbart när data kan klassificeras längs två olika dimensioner. I ett experiment för att mäta höjden på växter kan växterna till exempel få olika typer av växtnäring (t.ex. A, B, C) och kan också förvaras vid olika temperaturer (till exempel vid låg, hög). För vart och ett av de sex möjliga paren {växtnäring, temperatur} har vi lika många observationer av växthöjd. Med det här Anova-verktyget kan vi testa:
-
Om växtens höjd för olika typer av växtnäring kommer från samma underliggande population. Temperaturfaktorn ignoreras vid den här analysen.
-
Om höjden på växter som odlats vid olika temperaturnivåer kommer från samma underliggande population. Växtnäringsfaktorn ignoreras vid den här analysen.
Om, med beaktande av de effekter som kan härledas från olika typer av växtnäring i den första punkten och från olika temperaturer i den andra punkten, de sex sampel som representerar alla möjliga värdepar {växtnäring, temperatur} kommer från samma population. Den alternativa hypotesen antar att det finns kombinationseffekter av {växtnäring, temperatur} som dominerar över skillnader som beror på enbart växtnäring eller enbart temperatur.
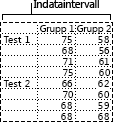
Anova: Två faktorer utan reproducering
Det här analysverktyget är praktiskt om informationen kan klassificeras i två dimensioner, precis som vid två faktorer med reproducering. För det här verktyget antas det emellertid att det bara finns en observation för varje par av mätdata (t.ex. varje {växtnäring, temperatur} i exemplet ovan).
Du kan använda funktionerna KORREL och PEARSON om du vill beräkna korrelationskoefficienten mellan två mätvariabler när det finns N observationer för varje variabel. (Om någon av observationerna för en individ i populationen saknas ignoreras individen.) Analysverktyget för korrelation är särskilt användbart när det finns mer än två mätvariabler för samtliga N individer. Verktygets utdata är en tabell, en korrelationsmatris, som visar värdet för KORREL (eller PEARSON) för varje möjligt par av mätvariabler.
Korrelationskoefficienten är, liksom kovariansen, ett mått på hur två variabler "varierar tillsammans". Till skillnad från kovariansen är korrelationskoefficienten normaliserad så att värdet inte beror på vilka enheter som de två mätvariablerna uttrycks i. (Om två mätvariabler exempelvis är vikt och höjd, påverkas inte korrelationskoefficienten om höjdenheten ändras från tum till centimeter.) Korrelationskoefficientens värde ligger alltid inom intervallet -1 till +1.
Du kan använda analysverktyget för korrelation om du vill undersöka varje par av mätvariabler och avgöra om de två variablerna har ett samband, d.v.s. om stora värden för den ena variabeln vanligtvis associeras med stora värden för den andra (positiv korrelation), om små värden för den ena variabeln motsvaras av stora värden för den andra (negativ korrelation) eller om det inte finns något samband mellan värdena för de båda variablerna (korrelation nära 0 (noll)).
Analysverktygen för kovarians och korrelation kan användas i samma beräkning, om det finns N skilda mätvariabler för observationer av en mängd individer. Båda verktygen returnerar en utdatatabell, en matris, som visar korrelationen eller kovariansen mellan varje par av mätvariabler. Skillnaden är att korrelationskoefficienten är normaliserad så att värdet alltid ligger inom intervallet -1 och +1. Motsvarande kovarianser är inte normaliserade. Både korrelationskoefficienten och kovariansen är mått på hur två variabler \ldblquote varierar tillsammans".
Kovariansverktyget beräknar värdet för kalkylbladsfunktionen KOVARIANS. P för varje par av mätvariabler. (Direkt användning av KOVARIANS. P snarare än kovariansverktyget är ett rimligt alternativ när det bara finns två mätvariabler, det vill: N=2.) Posten på diagonalen i kovariansverktygets utdatatabell på rad i, kolumn i är kovariansen för den i:te mätvariabeln med sig själv. Det här är bara populationsvariansen för variabeln, som beräknas av kalkylbladsfunktionen VARIANS.P.
Du kan använda analysverktyget för kovarians om du vill undersöka varje par av mätvariabler och avgöra om de två mätvariablerna har ett samband, d.v.s. om stora värden för den ena variabeln vanligtvis associeras med stora värden för den andra (positiv korrelation), om små värden för den ena variabeln motsvaras av stora värden för den andra (negativ korrelation) eller om det inte finns något samband mellan värdena för de båda variablerna (korrelation nära 0 (noll)).
Analysverktyget för beskrivande statistik genererar en rapport med endimensionell statistik för data i indataområdet och ger information om datas centrala tendens och variabilitet.
Med analysverktyget för exponentiell utjämning kan du förutsäga ett värde som baseras på en prognos från den föregående perioden (prognosen justeras för fel i föregående prognos). Metoden använder en utjämnande konstant, a, vars storlek bestämmer hur väl prognoser svarar mot fel i föregående prognoser.
Obs!: Värden mellan 0,2 och 0,3 är rimliga utjämningskonstanter. Dessa värden anger att den aktuella prognosen ska justeras med mellan 20 och 30 procent för fel i föregående prognos. Större konstanter ger snabbare gensvar men kan ge upphov till felaktiga projektioner. Mindre konstanter kan resultera i stora glapp mellan prognosvärden.
Analysverktyget F-test: Två sampel antar olika varianser utför ett två-sampel F-test som jämför två populationsvarianser.
Du kan exempelvis använda verktyget F-test för tidsvärden från en simtävling mellan två lag. Verktyget testar hypotesen att de båda samplen kommer från populationer med samma varianser mot den alternativa hypotesen som antar att varianserna inte är samma i de underliggande populationerna.
Verktyget används för att beräkna värdet f av en F-statistik (eller F-kvot). Om värdet för f ligger nära 1 tyder det på att varianserna i de underliggande populationerna är lika. Om f < 1 i utdatatabellen, returnerar "P(F <= f) ensidig" sannolikheten att observera ett värde i F-statistiken som är mindre än f när populationsvarianserna är lika, och "F-kritisk ensidig" anger det kritiska värdet som är mindre än 1 för angiven signifikansnivå (alfa). Om f > 1, returnerar "P(F <= f) ensidig" sannolikheten att observera ett värde i en F-statistik som är större än f när populationsvarianserna är lika, och "F-kritisk ensidig" anger det kritiska värdet som är större än 1 för alfa.
Verktyget Fourier Analysis löser problem i linjära system och analyserar periodiska data med hjälp av FFT-metoden (Fast Fourier Transform) för att omvandla data. Det här verktyget har också stöd för inverterade transformationer där inversen av transformerade data returnerar de ursprungliga data.
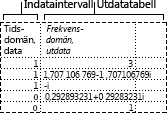
Analysverktyget för histogram beräknar individuella och kumulativa frekvenser för ett cellområde med data och datafack. Verktyget genererar data för antalet förekomster av ett värde i en datamängd.
Du kan exempelvis bestämma betygsfördelningen i bokstavskategorier för en klass med 20 elever. Ett histogram illustrerar gränserna för betygsgraderna och antalet betyg mellan den lägsta och den aktuella gränsen. Det vanligast förekommande betyget utgör typläget.
Analysverktyget för glidande medelvärden förutsäger värden i prognosperioden, baserat på variabelns medelvärde över ett visst antal föregående perioder. Ett glidande medelvärde ger trendinformation som inte skulle upptäckas i ett enkelt medelvärde. Använd det här verktyget för att förutsäga försäljning, lagerhållning och andra trender. Varje prognosvärde baseras på följande formel:
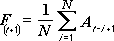
där:
-
N är antalet tidigare perioder som ska tas med i det glidande medelvärdet
-
A j är det sanna värdet vid tiden j
-
F j är det förutsagda värdet vid tiden j
Med analysverktyget för slumptalsgenerering kan du fylla ett område med oberoende slumptal från en av flera fördelningar. Du kan använda det här verktyget om du vill beskriva individer i en population med hjälp av en sannolikhetsfördelning. Du kan exempelvis använda en normalfördelning för att beskriva individernas längd i en population eller använda en Bernoulli-fördelning med två möjliga resultat för att beskriva populationen av resultat från slantsingling.
Analysverktyget Rangordning och Percentil skapar en tabell som innehåller rangordningen och procentrangen för varje värde i en datamängd. Du kan analysera värdenas relativa position i en datamängd. Det här verktyget använder kalkylbladsfunktionerna RANG. EKV och PROCENTRANG. INC. Om du vill redovisa kopplade värden använder du RANG. Funktionen EKV , som behandlar bundna värden som att de har samma rangordning, eller använder RANG.Funktionen MEDEL, som returnerar genomsnittlig rangordning för de bundna värdena.
Med regressionsanalysverktyget kan du utföra en linjär regressionsanalys baserat på "minsta kvadrat"-metoden för att anpassa en linje genom en observationsmängd. Du kan använda det här verktyget om du vill analysera hur en enstaka beroende variabel påverkas av värdet i en eller flera oberoende variabler. Du kan exempelvis analysera hur en idrottsmans prestationsförmåga påverkas av faktorer som ålder, längd och vikt. Du kan fördela måttet på prestationsförmågan till var och en av de fyra faktorerna baserat på en mängd prestationsdata, och sedan använda regressionsresultatet för att förutsäga en ny, otestad idrottsmans prestationsförmåga.
Verktyget Regression använder kalkylbladsfunktionen REGR.
Analysverktyget för sampling används för att skapa ett sampel från en population genom att indataområdet behandlas som en population. Om populationen är för stor för att behandlas eller illustreras i ett diagram kan du använda ett representativt sampel. Du kan även skapa ett sampel som bara innehåller värden från en del av cykeln om du tror att indata är periodiska. Om indataområdet exempelvis innehåller kvartalsförsäljningssiffror, kan sampling med en periodicitet på fyra placera värden från samma kvartal i utdataområdet.
Med dessa analysverktyg kan du testa om populationsmedelvärdena för samplen är lika. De tre verktygen gör olika antaganden: att populationsvarianserna är lika, att populationsvarianserna inte är lika, samt att båda värdena representerar mätdata från samma individ, men före och efter behandling.
Alla tre verktygen nedan används för att beräkna värdet på en t-statistik, t, som visas som "t-stat" i utdatatabellerna. Beroende på vilka data som används kan t vara större eller mindre än noll. Om t < 0, och under antagandet att de underliggande populationerna har samma medelvärde, returnerar "P(T <= t) ensidig" sannolikheten att observera ett värde i t-statistiken som är mer negativt än t. Om t >=0 returnerar "P(T <= t) ensidig" sannolikheten att observera ett värde i t-statistiken som är mer positivt än t. "t kritiskt ensidig" anger brytpunkten där sannolikheten att observera ett värde i t-statistiken som större än eller lika med "t kritiskt ensidig" är alfa.
"P(T <= t) tvåsidig" returnerar sannolikheten att observera ett värde i t-statistiken med ett absolutvärde som är större än t. "P kritiskt tvåsidig" anger brytpunkten där sannolikheten att observera ett värde i t-statistiken med ett absolutvärde som är större än "P kritiskt tvåsidig" är alfa.
t-test: Parat två-sampel för medelvärde
Du kan använda ett parat test när det finns naturliga par för observationerna i samplen, t.ex. när en sampelgrupp testas två gånger , före och efter ett experiment. Det här analysverktyget och dess formel utför ett t-test av typen parat två-sampel för att avgöra om observationer före och efter en behandling kan antas komma från populationer med samma populationsmedelvärde. Den här typen av t-test antar inte att de båda populationernas varians är lika.
Obs!: Det här verktyget kan bland annat returnera resultat av typen "parad varians", som är ett ackumulerat mått på spridningen runt medelvärdet, härlett från följande formel.
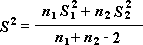
t-test: Två sampel antar lika varians
Det här analysverktyget utför en elevs t-test med två prov. Det här t-Test-formuläret förutsätter att de två datauppsättningarna kom från distributioner med samma varianser. Det kallas ett homoscedastic t-test. Du kan använda det här t-testet för att avgöra om de två exemplen troligen kommer från fördelningar med samma populationsmedelvärden.
t-test: Två sampel antar olika varianser
Det här analysverktyget utför en elevs t-test med två prov. Det här t-Test-formuläret förutsätter att de två datauppsättningarna kom från fördelningar med olika varianser. Det kallas för ett heteroscedastic t-test. Som med föregående lika variansfall kan du använda det här t-testet för att avgöra om de två exemplen kan antas komma från fördelningar med samma populationsmedelvärden. Använd det här testet när det finns distinkta försökspersoner i de två exemplen. Använd det kopplade testet, som beskrivs i exemplet nedan, när det finns en enda uppsättning försökspersoner och de två proverna representerar mätningar för varje försöksperson före och efter en behandling.
Använd nedanstående formel när du vill bestämma det statistiska värdet för testet t.
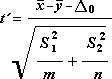
Följande formel används för att beräkna frihetsgrader, df. Eftersom resultatet av beräkningen vanligtvis inte är ett heltal avrundas värdet på df till närmaste heltal för att erhålla ett kritiskt värde från t-tabellen. Excel-kalkylbladsfunktionen T.TEST använder det beräknade df-värdet utan avrundning, eftersom det är möjligt att beräkna ett värde för T.TEST med en icke-integerar df. På grund av dessa olika metoder för att bestämma graden av frihet, resultaten av T.TEST och det här t-testverktyget skiljer sig åt i fallet Differensvariationer.
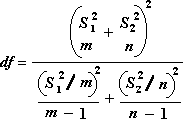
Z-Test: Two Sample for Means analysis tool utför ett Z-test med två sampel för medel med kända varianser. Det här verktyget används för att testa nullhypotesen att det inte finns någon skillnad mellan två populationsmedelvärden mot antingen ensidiga eller dubbelsidiga alternativa hypoteser. Om varianserna inte är kända kan kalkylbladsfunktionen Z.TEST ska användas i stället.
Var noga med att förstå resultatet när du använder verktyget z-Test. "P(Z <= z) ensidig" är egentligen P(Z >= ABS(z)), sannolikheten för ett z-värde längre från 0 i samma riktning som det observerade z-värdet när det inte finns någon skillnad mellan populationsmedelvärdet. "P(Z <= z) tvåsidig" är egentligen P(Z >= ABS(z) eller Z <= -ABS(z)), sannolikheten för ett z-värde längre från 0 i endera riktningen än det observerade z-värdet när det inte finns någon skillnad mellan populationsmedelvärdet. Det tvåsidiga resultatet är bara det ensidiga resultatet multiplicerat med 2. Verktyget z-Test kan också användas för fall där nullhypotesen är att det finns ett specifikt nollvärde för skillnaden mellan de två populationsmedelvärdena. Du kan till exempel använda det här testet för att fastställa skillnader mellan prestanda för två bilmodeller.
Behöver du mer hjälp?
Du kan alltid fråga en expert i Excel Tech Community eller få support i Communities.
Se även
Skapa ett histogram i Excel 2016
Skapa ett paretodiagram i Excel 2016
Läsa in Analysis ToolPak i Excel
ENGINEERING-funktioner (referens)
Hur du undviker felaktiga formler
Hitta och korrigera fel i formler
Kortkommandon och funktionstangenter i Excel









