
När du har migrerat dina data från Access till SQL Server har du en klient/server-databas, som kan vara en lokal lösning eller en hybridlösning med Azure Cloud. I vilket fall som helst är Access nu presentationslagret och SQL Server är datalagret. Nu kan det vara dags att gå igenom olika aspekter av din lösning, särskilt frågeprestanda, säkerhet och affärskontinuitet, så att du kan förbättra och skala din databaslösning.
En Access-användares första möte med dokumentationen för SQL Server och Azure kan kännas överväldigande. Då kan du behöva en guidad tur genom de punkter som intresserar dig mest. När du har slutfört den här turen är du redo att börja utforska utvecklingen inom databasteknik och få en mer ingående tur.
Artikelinnehåll
|
Databashantering |
Frågor och relaterade ämnen |
Datatyper |
Diverse |
Stimulera affärskontinuitet
Du vill ha en Access-lösning som du kan köra utan onödiga avbrott, men med en Access back-end-databas är möjligheterna begränsade. Säkerhetskopiering av din Access-databas är viktigt för att skydda dina data men det kräver att användarna är offline. Det förekommer även oplanerade driftsavbrott som orsakas av uppgraderingar av maskinvara och programvara, nätverks- eller strömavbrott, maskinvarufel, säkerhetsluckor eller till och med cyberattacker. Du kan säkerhetskopiera en SQL Server-databas medan den används för att minimera driftstörningar och påverkan på ditt företag. Dessutom tillhandahåller SQL Server även strategier för hög tillgänglighet (HA) och katastrofåterställning (DR). Dessa två kombinerade tekniker kallas för HADR. Mer information finns i artiklarna Business continuity and database recovery och Drive business continuity with SQL Server (e-bok).
Säkerhetskopiera medan den används
SQL Server använder en process för säkerhetskopiering online som kan inträffa medan databasen körs. Du kan göra en fullständig eller partiell säkerhetskopiering, eller en filsäkerhetskopiering. Säkerhetskopieringen kopierar data och transaktionsloggar för att säkerställa en fullständig återställning. Särskilt i en lokal lösning måste du vara medveten om skillnaderna mellan enkla och fullständiga återställningsalternativ och hur de påverkar ökningen av transaktionsloggar. Mer information finns i Recovery models.
De flesta säkerhetskopieringar uppstår direkt, förutom filhantering och åtgärder för databaskrympning. Däremot går det inte att skapa eller ta bort en databasfil när en säkerhetskopieringsåtgärd pågår. Mer information finns i Backup Overview.
HADR
De två vanligaste teknikerna för att uppnå hög tillgänglighet och företagskontinuitet är spegling och klustring. I SQL Server integreras speglings- och klustringsteknik med "Alltid på instanser av redundanskluster" och "Alltid på tillgänglighetsgrupper".
Spegling är en kontinuitetslösning på databasnivå som har stöd för omedelbar failover genom att ha en standby-databas, en fullständig kopia eller spegling av den aktiva databasen på separat maskinvara. Det kan fungera i ett synkront läge (hög säkerhetsnivå), där inkommande transaktioner allokeras till alla servrar samtidigt, eller i ett asynkront (högpresterande) läge, där en inkommande transaktion allokeras till den aktiva databasen och sedan vid en förutbestämd punkt kopieras till spegeln. Spegling är en lösning på databasnivå och fungerar bara med databaser som använder den fullständiga återställningsmodellen.
Klustring är en lösning på servernivå som kombinerar servrar till ett enda datalagringsutrymme som för användaren ser ut som en enda instans. Användare ansluter till instansen och behöver aldrig veta vilken server i instansen som för närvarande är aktiv. Om en server inte fungerar eller behöver tas offline för underhåll ändras inte användarupplevelsen. Varje server i klustret övervakas av klusterhanteraren med hjälp av ett pulsslag, så att den identifierar när den aktiva servern i klustret går offline och försöker att smidigt växla till nästa server i klustret. Dock medför det en viss tidsfördröjning när växlingen sker.
Mer information finns i Always On Failover Cluster Instances och Always On availability groups: a high-availability and disaster-recovery solution.
SQL Server-säkerhet
Även om du kan skydda Access-databasen genom att använda Säkerhetscenter och genom att kryptera databasen så finns det mer avancerade säkerhetsfunktioner i SQL Server. Nu ska vi titta på tre framträdande funktioner för användare av Access. Mer information finns i Securing SQL Server.
Databasautentisering
Det finns fyra metoder för databasautentisering i SQL Server, som var och en kan anges i en ODBC-anslutningssträng. Mer information finns i Länka till eller importera data från en Azure SQL Server-databas. Varje metod har sina fördelar.
Integrerad Windows-autentisering Använd Windows-autentiseringsuppgifter för validering av användare, säkerhetsroller och begränsning av användare till funktioner och data. Du kan använda domänautentiseringsuppgifter och enkelt hantera användarrättigheter i programmet. Alternativt kan du ange ett Service Principal Names (SPNs). Mer information finns i Choose an Authentication Mode.
SQL Server-autentisering Användare måste ansluta med autentiseringsuppgifter som har konfigurerats i databasen genom att ange inloggnings-ID och lösenord första gången de får tillgång till databasen i en session. Mer information finns i Choose an Authentication Mode.
Azure Active Directory-integrerad autentisering Anslut till Azure SQL Server-databasen med hjälp av Azure Active Directory. När du har konfigurerat Azure Active Directory-autentisering krävs ingen ytterligare inloggning eller lösenord. Mer information finns i Ansluta till SQL-databas med hjälp av Azure Active Directory-autentisering.
Lösenordsautentisering i Active Directory Anslut med autentiseringsuppgifter som har konfigurerats i Azure Active Directory genom att ange inloggningsnamn och lösenord. Mer information finns i Ansluta till SQL-databas med hjälp av Azure Active Directory-autentisering.
Tips Använd identifiering av hot för att få aviseringar om avvikelser i databasaktivitet som anger potentiella säkerhetshot för en Azure SQL Server-databas. Mer information finns i SQL Database Threat Detection.
Programsäkerhet
SQL Server har två säkerhetsfunktioner på programnivå som du kan dra nytta av med Access.
Dynamisk datamaskning Dölj känslig information genom att maskera den från användare som inte är behöriga. Du kan t. ex. antingen delvis eller helt maskera personnummer.
 En partiell datamask |
 En fullständig datamask |
Det finns flera sätt att definiera en datamask och du kan använda dem för olika datatyper. Datamaskering är principbaserad på tabell-och kolumnnivån för en viss uppsättning användare och används i realtid till frågor. Mer information finns i Dynamic Data Masking.
Säkerhet på radnivå Du kan kontrollera åtkomsten till vissa databasrader med känslig information baserat på användaregenskaper genom att använda säkerhet på radnivå. Databassystemet tillämpar dessa åtkomstbegränsningar och detta gör att säkerhetssystemet blir mer tillförlitligt och robust.

Det finns två typer av säkerhetspredikat:
-
Ett filterpredikat filtrerar rader från en fråga. Filtret är transparent och slutanvändaren vet inte om filtreringen.
-
Ett block-predikat hindrar otillåten aktivitet och genererar ett undantag om det inte går att utföra aktiviteten.
Mer information finns i Row level security.
Skydda data med kryptering
Skydda data som är vilande, i transit och medan de används, utan att påverka databasens prestanda. Mer information finns i SQL Server Encryption.
Kryptering i vila Skydda personuppgifter mot offline-angrepp på det fysiska lagringsutrymmet genom att använda encryption-at-rest, som även kallas Transparent Data Encryption (TDE). Detta innebär att dina uppgifter är skyddade även om de fysiska medierna stjäls eller används felaktigt. TDE utför kryptering och dekryptering av databaser, säkerhetskopiering och transaktionsloggar i realtid, utan att du behöver ändra programmen.
Kryptering under överföring Du kan kryptera data som överförs via nätverket för att skydda dig mot snooping och man-i-mitten-attacker. SQL Server har stöd för TLS (Transport Layer Security) 1.2 för kommunikation med hög säkerhetsnivå. TDS-protokollet (tabelldataström) används också för att skydda kommunikationen mellan icke-betrodda nätverk.
Kryptering som används på klienten Om du vill skydda personliga data medan de används är "Always Encrypted" den funktion du vill använda. Personliga data krypteras och dekrypteras med en drivrutin på klientdatorn utan att du avslöjar krypteringsnycklarna till databasmotorn. Som ett resultat av detta visas krypterade data endast för de personer som ansvarar för att hantera dessa data och inte för andra användare med hög behörighet, vilka inte bör ha någon åtkomst. Beroende på vilken typ av kryptering som har valts kan Always Encrypted begränsa vissa databasfunktioner, till exempel att söka, gruppera och indexera krypterade kolumner.
Hantera sekretessproblem
Sekretessproblemen är så omfattande att EU har definierat juridiska krav via dataskyddsförordningen General Data Protection Regulation (GDPR). Som tur är är det väldigt lämpligt att använda SQL Server backend för att möta dessa behov. Tänk dig att implementeringen av GDPR utförs i ett ramverk i tre steg.

Steg 1: Utvärdera och hantera efterlevnadsrisker
GDPR kräver att du identifierar och inventerar de personuppgifter du har i tabeller och filer. Den här informationen kan vara allt från ett namn, ett foto, en e-postadress, bankuppgifter, inlägg på webbplatser för sociala nätverk, medicinsk information eller till och med en IP-adress.
Ett nytt verktyg, SQL Data Discovery and Classification är inbyggt i SQL Server Management Studio och hjälper dig att upptäcka, klassificera, etikettera och rapportera om känsliga data genom att tillämpa två metadataattribut i kolumner:
-
Etiketter För att definiera datakänslighet.
-
Informationstyper Ge ytterligare detaljerad information om de typer av data som lagras i en kolumn.
En annan identifieringsfunktion som du kan använda är fulltextsökning, som inkluderar användningen av CONTAINS-och FREETEXT-predikat och raduppsättningsfunktioner, t. ex. CONTAINSTABLE och FREETEXTTABLE som används tillsammans med SELECT-satsen. Genom att använda textsökning kan du söka i tabeller och hitta ord, ordkombinationer eller varianter av ett ord, till exempel synonymer eller böjningsformer. Mer information finns i Full-Text Search.
Steg 2: Skydda personlig information
GDPR kräver att du skyddar personlig information och begränsar åtkomsten till den. Förutom standardstegen för att hantera åtkomsten till ditt nätverk och dina resurser, som till exempel brandväggsinställningar, kan du använda säkerhetsfunktionerna i SQL Server för att styra åtkomsten till data:
-
SQL Server-autentisering för att hantera användaridentitet och förhindra obehörig åtkomst.
-
Säkerhet på radnivå för att begränsa åtkomsten till rader i en tabell baserat på relationen mellan användare och data.
-
Dynamisk datamaskning för att begränsa exponering av personuppgifter genom att maskera dem från användare som inte är behöriga.
-
Kryptering för att säkerställa att personuppgifter skyddas vid överföring och lagring och skyddas mot intrång, även från serversidan.
Mer information finns i SQL Server Security.
Steg 3: Svara effektivt på förfrågningar
GDPR kräver att du för register över behandlingen av personliga data och att posterna vid begäran görs tillgängliga för dataskyddsmyndigheten. Om det uppstår problem i form av oavsiktligt dataläckage kan du reagera snabbt tack vare skyddskontroller. Data måste snabbt göras tillgängliga när rapporter krävs. Exempel: GDPR kräver att personuppgiftsbrott rapporteras till dataskyddsmyndigheten "senast 72 timmar efter att det har upptäckts".
Med SQL Server 2017 går det att genomföra rapportering på flera olika sätt:
-
SQL Server Audit får du hjälp med att se till att beständiga poster för databasåtkomst och behandlingsaktiviteter finns. Den genomför en detaljerad granskning som spåra databasaktiviteter för att hjälpa dig att förstå och identifiera potentiella hot, misstänkt missbruk eller säkerhetsöverträdelser. Du kan enkelt utföra en forensisk dataundersökning.
-
Temporala tabeller i SQL Server är systemversioner av användartabeller som har utformats för att hålla en fullständig historik av dataändringar. Du kan använda dessa för enkel rapportering och tidpunktsanalys.
-
SQL Vulnerability Assessment hjälper dig att identifiera säkerhets- och behörighetsproblem. När ett problem upptäcks kan du även gå igenom genomsökningsrapporterna för databasen på djupet för att hitta åtgärder för problemlösning.
Mer information finns i Create a platform of trust (e-bok) och Journey to GDPR Compliance.
Skapa ögonblicksbilder av databaser
En ögonblicksbild av en databas är en skrivskyddad, statisk vy av en SQL Server-databas tagen vid en viss tidpunkt. Även om du kan kopiera en Access-databasfil som effektivt skapar en ögonblicksbild av en databas, har Access ingen inbyggd metod som SQL Server. Du kan använda en ögonblicksbild av en databas för att skriva rapporter utifrån de data som fanns vid tiden för skapandet av ögonblicksbilden. Du kan också använda ögonblicksbilden av databasen för att upprätthålla registreringshistorik av data, t. ex. en för varje budgetkvartal som du använder för rapportering vid periodslut. Vi rekommenderar följande tillvägagångssätt:
-
Namnge ögonblicksbilden Varje databas-ögonblicksbild kräver ett unikt databasnamn. Lägg till syftet med ögonblicksbilden och tidsramen i namnet för att lättare kunna identifiera den. Om du till exempel vill göra en ögonblicksbild av AdventureWorks-databasen tre gånger om dagen med sex timmars intervall mellan kl. 06.00 och 18.00 baserat på en 24-timmarsklocka, namnge dem AdventureWorks_snapshot_0600, AdventureWorks_snapshot_1200 och AdventureWorks_snapshot_1800.
-
Begränsa antalet ögonblicksbilder Varje databas-ögonblicksbild finns kvar tills den uttryckligen tas bort. Eftersom varje ögonblicksbild fortsätter att växa kanske du vill spara diskutrymme genom att ta bort äldre ögonblicksbilder när du har skapat en ny. Om du exempelvis gör dagliga rapporter kan du behålla databasens ögonblicksbild i 24 timmar och sedan släppa den och ersätta den med en ny.
-
Ansluta till rätt ögonblicksbild Om Access front-end vill använda en ögonblicksbild av en databas måste den ha tillgång till rätt plats. När du ersätter en ny ögonblicksbild med en befintlig bild måste du omdirigera Access till den nya ögonblicksbilden. Tillsätt logik till Access front-end för att vara säker på att du ansluter till rätt databas-ögonblicksbild.
Så här skapar du en databas-ögonblicksbild:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Mer information finns i Ögonblicksbilder av databaser (SQL Server).
Samtidighetskontroll
När flera användare försöker ändra data i en databas samtidigt, behövs ett system med kontroller så att ändringar som görs av en person inte påverkar någon annans ändringar. Detta kallas för samtidighetskontroll och det finns två grundläggande låsningsstrategier,en pessimistisk och en optimistisk. Låsning kan förhindra att användare ändrar data på ett sätt som påverkar andra användare. Låsning medverkar även till att säkerställa databasintegritet, särskilt med frågor som annars skulle kunna leda till oväntade resultat. Det finns viktiga skillnader i hur Access och SQL Server använder de här strategierna för samtidighetskontroll.
I Access är standardstrategin för låsning optimistisk och ger ägarskapet till låset till den första personen som försöker skriva till en post. I Access visas dialogrutan Skrivkonflikt för den andra personen som försöker skriva till samma post samtidigt. Konflikten kan lösas genom den andra personen sparar posten, kopierar den till Urklipp eller släpper ändringarna.
Du kan också använda egenskapen RecordLocks för att ändra strategin för samtidighetskontroll. Denna egenskap påverkar formulär, rapporter och frågor och har tre inställningar:
-
Inga lås I ett formulär kan användare försöka redigera samma post samtidigt, men dialogrutan Skrivkonflikt kan dyka upp. I rapporter är poster inte låsta medan rapporten förhandsgranskas eller skrivs ut. I frågor är poster inte låsta medan frågan körs. Det här är Access metod för att implementera optimistisk låsning.
-
Alla poster Alla poster i den underliggande tabellen eller frågan är låsta medan formuläret är öppet i vyerna Formulär eller Datablad, om rapporten för tillfället förhandsgranskas eller skrivs ut eller frågan körs. Användare kan läsa posterna under låsning.
-
Redigerad post För formulär och frågor låses en sida med poster så snart en användare börjar redigera något fält i posten och förblir låst tills användaren går vidare till en annan post. En post kan därmed bara redigeras av en användare i taget. Det här är Access metod för att implementera pessimistisk låsning.
Mer information finns i Dialogrutan Skrivkonflikt och RecordLocks Property.
I SQL Server fungerar samtidighetskontrollen på följande sätt:
-
Pessimistisk När en användare utför en åtgärd som gör att låset tillämpas kan andra användare inte utföra åtgärder som skulle vara i konflikt med låset tills ägaren släpper den. Denna samtidighetskontroll används huvudsakligen i miljöer där det finns hög datakonkurrens.
-
Optimistisk I optimistisk samtidighetskontroll låser inte användarna data när de läser dem. När en användare uppdaterar data kontrollerar systemet om någon annan användare har ändrat dessa data efter att de lästs. Om en annan användare har uppdaterat data utlöses ett fel. Vanligtvis får den användare som mottar felet återställa transaktionen och börja om. Denna samtidighetskontroll används huvudsakligen i miljöer där det finns låg datakonkurrens.
Du kan ange typen av samtidighetskontroll genom att markera flera nivåer av transaktionsisolering, som definierar skyddsnivån för transaktionen utifrån ändringar som gjorts av andra transaktioner genom att använda satsen SET TRANSACTION:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Isoleringsnivå |
Beskrivning |
|
Ogenomförd läsning |
Transaktioner är bara isolerade i sådan mån att fysiskt korrupta data inte läses. |
|
Genomförd läsning |
Transaktioner kan läsa data som lästs tidigare av en annan transaktion utan att vänta på att den första transaktionen slutförs. |
|
Repeterbar läsning |
Läs- och skrivlås uppstår för markerade data fram till slutet av transaktionen, men fiktiva läsningar kan uppstå. |
|
Ögonblicksbild |
Använder radversionen för att tillhandahålla läskonsekvens på transaktionsnivå. |
|
Serialiserbar |
Transaktioner är helt isolerade från varandra. |
För mer information gå till Transaction Locking and Row Versioning Guide.
Optimera frågeprestanda
När du väl har fått en fungerande Access-direktfråga, dra då nytta av de avancerade sätt som en SQL Server kan få den att köras på mer effektivt.
Till skillnad från en Access-databas tillhandahåller SQL Server parallella frågor för att optimera frågekörning och indexåtgärder för datorer som har fler än en mikroprocessor (CPU). Eftersom SQL Server parallellt kan utföra en fråga eller ett index genom att använda flera arbetstrådar kan operationen utföras snabbt och effektivt.
Frågor är en avgörande komponent i förbättringen av databaslösningens allmänna prestanda. Felaktiga frågor körs på obegränsad tid, löper ut och förbrukar resurser som processor, minne och nätverksbandit. Detta hindrar tillgängligheten för viktig företagsinformation. Även en dålig fråga kan orsaka allvarliga prestandaproblem för din databas.
Mer information finns i Faster querying with SQL Server (e-bok).
Frågeoptimering
Flera verktyg samarbetar för att hjälpa dig att analysera frågeprestanda och förbättra den: Frågeoptimering, körningsplaner och Query Store.
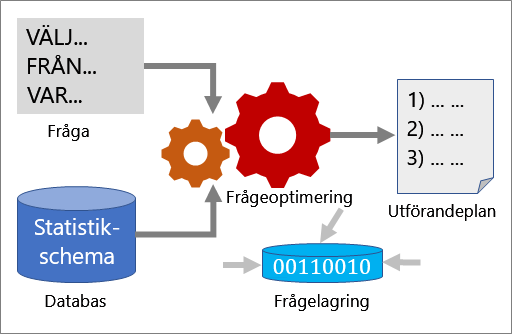
Frågeoptimering
Frågeoptimeraren är en av de viktigaste komponenterna i SQL Server. Använd frågeoptimeraren för att analysera en fråga och fastställa det effektivaste sättet att komma åt nödvändiga data. Indata till frågeoptimeraren består av frågan, databasschemat (tabeller och indexdefinitioner) samt databasstatistik. Utdata från frågeoptimeraren är en körningsplan.
Mer information finns i The SQL Server Query Optimizer.
Körningsplan
En körningsplan är en definition som skapar sekvenser av källtabeller för åtkomst och metoder som används för att hämta data från varje tabell. Optimering innebär att du väljer ut en körningsplan ur ett potentiellt antal möjliga planer. Varje möjlig körningsplan har en associerad kostnad vad gäller mängden datorresurser som används och frågeoptimeraren väljer den som har den lägsta uppskattade kostnaden.
SQL Server måste också dynamiskt justeras allt eftersom villkoren ändras i databasen. Regressioner i frågekörningsplaner kan påverka prestanda kraftigt. Vissa ändringar i databasen kan medföra att en körningsplan blir ineffektiv eller ogiltig, baserat på databasens nya tillstånd. I SQL Server identifieras ändringarna som gör att det inte går att validera en körningsplan och markerar planen som ogiltig.
En ny plan måste sedan sammanställas för nästa anslutning som kör frågan. Villkoren som upphäver en plan inkluderar:
-
Ändringar som gjorts i en tabell eller vy som refereras av frågan (ALTER TABLE och ALTER VIEW).
-
Ändringar av index som används av körningsplanen.
-
Uppdateringar av statistik som används av körningsplanen, som antingen skapas explicit från en sats, t. ex. UPDATE STATISTICS, eller skapas automatiskt.
Mer information finns i Execution plans.
Query Store
I Query Store finns information om valet av körningsplan och prestanda. Det underlättar felsökning av prestandaproblem genom att snabbt hjälpa dig att hitta prestandaskillnader orsakade av ändringar i körningsplanen. I Query Store samlas telemetridata i form av frågehistorik, planhistorik, körningsstatistik och väntestatistik. Använd instruktionen ALTER DATABASE för att implementera Query Store:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Gå till Query Store och Övervaka prestanda för mer information.
Automatisk plankorrigering
Det enklaste sättet att förbättra frågeprestanda är att använda Automatisk plankorrigering, en funktion som finns tillgänglig i Azure SQL Database. Det är bara att aktivera den och låta den arbeta. Den utför löpande övervakning av och analyserar körningsplaner, identifierar problematiska körningsplaner och löser prestandaproblem automatiskt. Bakom kulisserna använder Automatisk plankorrigering en metod i fyra steg som innebär lär, anpassa, verifiera och upprepa.
Mer information finns i Automatic tuning.
Adaptiv frågebearbetning
Du kan även få frågor snabbare bara genom att uppgradera till SQL Server 2017, som har en ny funktion som kallas Adaptiv frågebearbetning. SQL Server justerar alternativen för frågeplanen baserat på körningens egenskaper.
En kardinalitetsberäkning uppskattar antalet rader som bearbetas i varje steg av en körningsplan. Felaktiga uppskattningar kan resultera i långsamma svarstider för frågor, onödigt resursutnyttjande (minne, processor och I/O) samt minskat genomflöde och samtidighet. Tre tekniker används för anpassning till applikationernas arbetsbelastning och egenskaper:
-
Tillåt feedback från minne i batchläge Dåliga kardinalitetsberäkningar kan medföra att frågor “spiller ut” till hårddisken eller tar upp för mycket minne. I SQL Server 2017 justeras beviljat minne utifrån körningsfeedback, tas spill bort i hårddisken och förbättrar samtidighet i upprepande frågor.
-
Adaptiva sammanfogningar i batchläge Adaptiva sammanfogningar väljer under körning dynamiskt bättre interna kopplingstyper (kapslade slingor, sammanfogade kopplingar eller hash-kopplingar), baserat på de faktiska indata-radvärdena. Därför kan en plan under körning dynamiskt växla till en bättre kopplingsstrategi.
-
Överlagrad körning Multipla värdefunktioner i tabeller har traditionellt behandlats som ett svart hål vid frågebearbetning. Med SQL Server 2017 kan du bättre beräkna antalet rader och förbättra underordnade åtgärder.
Du kan låta arbetsbelastning bli automatiskt berättigad till anpassad frågebearbetning genom att aktivera en kompatibilitetsnivå på 140 för databasen:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Mer information finns i Intelligent query processing in SQL databases.
Olika sätt att fråga
I SQL Server finns flera sätt att fråga, som alla har sina fördelar. Det är bra om du känner till dem, så att du kan välja rätt Access-lösning. Det bästa sättet att skapa dina TSQL-frågor är att interaktivt redigera och testa dem med hjälp av SQL Server Management Studio (SSMS) Transact-SQL Editor, som innehåller IntelliSense för att hjälpa dig att välja rätt sökord och söka efter syntaxfel.
Vyer
I SQL Server är en vy som en virtuell tabell där visningsdata kommer från en eller flera tabeller eller andra vyer. Men vyerna refereras till precis som tabeller i frågor. Med vyer kan du dölja komplexiteten i frågor och få hjälp med att skydda data genom att begränsa uppsättningen rader och kolumner. Här är ett exempel på en enkel vy:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Skapa en indexerad vy för bästa möjliga prestanda och för redigering av visningsresultatet. Den finns kvar i databasen precis som en tabell, tilldelas lagringsutrymme och kan tillfrågas precis som vilken tabell som helst. Om du vill använda det i Access länkar du till vyn på samma sätt som du länkar till en tabell. Här är ett exempel på en indexerad vy:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Det finns dock begränsningar. Du kan inte uppdatera data om fler än en bastabell berörs, eller om vyn innehåller mängdfunktioner eller en DISTINCT-sats. Om SQL Server returnerar ett felmeddelande som innebär att servern inte vet vilken post som ska tas bort kan du behöva lägga till en Ta bort-utlösare i vyn. Dessutom kan du inte använda ORDER BY-satsen på det sätt som du kan göra med en Access-fråga.
Mer information finns i Views and Create indexed Views.
Lagrade procedurer
En lagrad procedur är en grupp med ett eller flera TSQL-uttryck som tar emot indataparametrar, returnerar utdataparametrar och anger om statusvärdet är klart eller misslyckat. De agerar som ett mellanliggande lager mellan Access front-end och SQL Server back-end. Lagrade procedurer kan vara lika enkla som ett SELECT-uttryck eller lika komplexa som vilket program som helst. Här är ett exempel:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
När du använder en lagrad procedur i Access skickas det vanligtvis en resultatuppsättning tillbaka till ett formulär eller en rapport. Men det kan hända att det utförs andra åtgärder som inte returnerar resultat, t. ex. DDL- och DML-uttryck. När du använder en pass-through query, kontrollera att du har ställt in egenskapen Returnera poster på rätt sätt.
Mer information finns i Stored procedures.
Vanliga tabelluttryck
Ett vanligt tabelluttryck (CTE) fungerar som en tillfällig tabell som genererar en namngiven resultatuppsättning. Den är bara till för körning av en enskild fråga eller DML-sats. En CTE är inbyggd i samma kodrad som SELECT-satsen eller DML-satsen där den används, medan en tillfällig tabell eller vy vanligtvis skapas i två steg. Här är ett exempel:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
En CTE har flera fördelar, inklusive följande:
-
Eftersom CTEs är tillfälliga behöver du inte skapa dem som permanenta databasobjekt, som t. ex. vyer.
-
Du kan referera till samma CTE mer än en gång i en fråga eller DML-sats, vilket gör din kod mer hanterbar.
-
Du kan använda frågor som refererar till en CTE för att definiera en markör.
Mer information finns i WITH common_table_expression.
Användardefinierade funktioner (UDF:er)
En användardefinierad funktion (UDF) kan utföra frågor och beräkningar och returnera antingen skalärvärden eller uppsättningar med dataresultat. De fungerar som funktioner i programmeringsspråk som accepterar parametrar, utför en åtgärd i form av en komplex beräkning och returnerar resultatet av den åtgärden som ett värde. Här är ett exempel:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
En UDF har vissa begränsningar. De kan till exempel inte använda vissa icke-deterministiska systemfunktioner, utföra DML- eller DDL-instruktioner eller utföra dynamiska SQL-frågor.
Mer information finns i User Defined Functions.
Lägga till nycklar och index
Vilket databassystem du än använder går nycklar och index hand i hand.
Nycklar
Kontrollera att du skapar primärnycklar för varje tabell och sekundärnycklar för varje relaterad tabell i SQL Server. Motsvarande funktion i SQL Server till datatypen Access AutoNumber är egenskapen IDENTITY som kan användas för att skapa nyckelvärden. När du använder den här egenskapen på en numerisk kolumn blir den skrivskyddad och underhålls av databassystemet. När du infogar en post i en tabell som innehåller en IDENTITY-kolumn så ökar systemet automatiskt värdet för den kolumnen med 1 och från och med 1, men du kan kontrollera värdena med hjälp av argument.
Mer information finns i CREATE TABLE, IDENTITY (Property).
Index
Som alltid är valet av index en balansakt mellan frågehastighet och uppdateringskostnad. I Access har du en enda typ av index, medan du i SQL Server har tolv stycken. Som tur är kan du använda frågeoptimering för att få hjälpa med att välja det mest effektiva indexet. I Azure SQL kan du använda automatisk indexhantering, en funktion för automatisk justering som ger rekommendationer om vilket index du bör lägga till eller ta bort. Till skillnad från Access måste du skapa egna index för utländska nycklar i SQL Server. Du kan också skapa index i en indexerad vy för att förbättra frågeprestandan. Nackdelarna med en indexerad vy ökar när du ändrar data i vyns bastabeller, eftersom även vyn måste uppdateras. Mer information finns i SQL Server Index Architecture and Design Guide och Indexes.
Genomföra transaktioner
Det är svårt att utföra en transaktionsprocess online (OLTP) när du använder Access, men relativt enkelt med SQL Server. En transaktion är en enskild arbetsenhet som åtar sig alla dataändringar när de lyckas, men som återställer dem när de misslyckas. En transaktion måste ha fyra egenskaper, så kallade ACID:
-
Atomicitet En transaktion måste vara en atomisk arbetsenhet. Antingen utförs samtliga dess dataändringar eller ingen alls.
-
Konsekvens När den är klar måste en transaktion lämna alla data i ett konsekvent tillstånd. Det innebär att alla regler för dataintegritet måste följas.
-
Isolering Ändringar som görs av samtidiga transaktioner är isolerade från den aktuella transaktionen.
-
Varaktighet När transaktionen har slutförts blir ändringarna permanenta även i händelse av ett systemfel.
Du använder en transaktion för att säkerställa att dataintegriteten garanteras, t. ex. vid bankomatuttag eller automatiska checkinsättningar. Du kan utföra explicita eller implicita transaktioner eller batch-transaktioner. Här är två TSQL-exempel:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Mer information finns under Transactions.
Använda villkor och utlösare
Alla databaser har metoder att upprätthålla dataintegritet.
Villkor
I Access tillämpas referensintegritet i en tabellrelation via parvis sammanfogning av primära och sekundära nycklar, sammanhängande uppdateringar och borttagningar samt verifieringsuttryck. Mer information finns i Guide till tabellrelationer och Begränsa datainmatning med hjälp av verifieringsuttryck.
I SQL Server använder du villkoren UNIQUE och CHECK, som är databasobjekt som upprätthåller dataintegritet i SQL Server-tabeller. Verifiera att ett värde är giltigt i en annan tabell genom att använda ett sekundärnyckel-villkor. För att verifiera att ett värde ligger inom en viss gräns använder du ett kontrollvillkor. De här objekten är din första skyddslinje och är utformade för att fungera effektivt. Mer information finns i Unique Constraints and Check Constraints.
Utlösare
Access har inga databasutlösare. I SQL Server kan du använda utlösare för att förstärka komplexa regler för dataintegritet och för att köra den här affärslogiken på servern. En databasutlösare är en lagrad procedur som körs när vissa åtgärder utförs i en databas. Utlösaren är en händelse, till exempel som att lägga till eller ta bort en post i en tabell, som utlöser och sedan kör en lagrad procedur. Även om en Access-databas kan säkerställa referensintegritet när en användare försöker att uppdatera eller ta bort data, har SQL Server en avancerad uppsättning utlösare. Du kan till exempel programmera en utlösare för att ta bort poster gruppvis och säkerställa dataintegriteten. Du kan även lägga till utlösare i tabeller och vyer.
Mer information finns i Triggers DML, Triggers – DDL och Designing a T-SQL trigger.
Använda beräknade kolumner
I Access kan du skapa en beräknad kolumn genom att lägga till den i en fråga och skapa ett uttryck, t. ex.:
Extended Price: [Quantity] * [Unit Price]
I SQL Server kallas motsvarande funktion för en beräknad kolumn. Detta är en virtuell kolumn som inte är fysiskt lagrad i tabellen, om inte kolumnen är markerad med PERSISTED. I likhet med en beräknad (calculated) kolumn används data från andra kolumner i ett uttryck i en beräknad (computed) kolumn. Om du vill skapa en beräknad kolumn kan du lägga till den i en tabell. Till exempel:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Mer information finns i Specify Computed Columns in a Table.
Tidsstämpla dina data
När en post skapas kan du ibland lägga till ett tabellfält för att spela in en tidsstämpel så att du kan logga datainmatningen. I Access kan du enkelt skapa en datumkolumn med standardvärdet för =Now(). Om du vill spela in ett datum eller en tid i SQL Server kan du använda datatypen datetime2 med standardvärdet för SYSDATETIME().
Obs! Undvik att blanda ihop rowversion med tillägg av tidsstämpel för dina data. Nyckelordet tidsstämpel är en synonym till rowversion i SQL Server, men du bör använda nyckelordet rowversion. I SQL Server är rowversion en datatyp som visar automatiskt genererade, unika binära tal i en databas och används vanligtvis som en mekanism för versionsstämpling av tabellrader. Datatypen rowversion är dock bara ett ökande tal. Den bevarar inte ett datum eller en tid och är inte avsedd att användas för att skapa tidsstämpling för en rad.
Mer information finns i rowversion. Mer information om hur du använder rowversion för att minimera postkonflikter finns i Migrera en Access-databas till SQL Server.
Hantera stora objekt
I Access hanterar du ostrukturerade data, t. ex. filer, foton och bilder, genom att använda datatypen Attachment data type. I terminologin för SQL Server kallas ostrukturerade data för Blob (Binary Large Object) och det finns flera sätt att arbeta med dem:
FILESTREAM Använder datatypen varbinary (max) för att lagra ostrukturerade data i filsystemet i stället för i databasen. Mer information finns i Access FILESTREAM Data with Transact-SQL.
FileTable Lagrar blobbar i särskilda tabeller som kallas FileTables och tillhandahåller kompatibilitet med Windows-program som om de lagrats i filsystemet och utan att göra några ändringar i dina klientprogram. FileTable kräver att FILESTREAM används. Mer information finns i FileTables.
Remote BLOB store (RBS) Lagrar stora binära objekt (BLOB) i råvarulagringslösningar istället för direkt på servern. Detta sparar utrymme och minskar maskinvaruresurser. Mer information finns i Binary Large Object (Blob) Data.
Arbeta med hierarkiska data
Även om relationsdatabaser som till exempel Access är mycket flexibla, så är arbetet med hierarkiska relationer ett undantag och kräver oftast komplexa SQL-uttryck eller kod. Exempel på hierarkiska data är: en organisationsstruktur, ett filsystem, en taxonomi med språkvillkor och ett diagram med länkar mellan webbsidor. SQL Server har en inbyggd hierarchyid-datatyp och en uppsättning hierarkiska funktioner som enkelt lagrar, ställer frågor och hanterar hierarkiska data.
Mer information finns i Hierarchical data och Tutorial: Using the hierarchyid data type.
Hantera JSON-text
Java Script Object Notation (JSON) är en webbtjänst som använder läsbar text för att överföra data som attribut-värdepar i asynkron kommunikation mellan webbläsare och server. Till exempel:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
I Access finns inte några inbyggda sätt att hantera JSON-data, men i SQL Server kan du smidigt lagra, indexera, fråga och extrahera JSON-data. Du kan konvertera och lagra JSON-text i en tabell eller formatera data som JSON-text. Du kanske till exempel vill formatera frågeresultat som JSON för ett webbprogram eller lägga till JSON-datastrukturer i rader och kolumner.
Obs! JSON stöds inte i VBA. Alternativt kan du använda XML i VBA med hjälp av MSXML-biblioteket.
Mer information finns i JSON data in SQL Server.
Resurser
Nu är det dags att lära dig mer om SQL Server och Transact SQL (TSQL). Som du har sett finns det många funktioner som Access, men du får även tillgång till egenskaper som Access helt enkelt saknar. Här följer några utbildningsresurser för att ta dig vidare till nästa nivå:
|
Resurs |
Beskrivning |
|
Videobaserad kurs |
|
|
Självstudiekurser om SQL Server 2017 |
|
|
Praktisk utbildning för Azure |
|
|
Bli en expert |
|
|
Startsidan |
|
|
Information och hjälp |
|
|
Information och hjälp |
|
|
Översikt över molnet |
|
|
En visuell sammanfattning av de nya funktionerna |
|
|
En sammanfattning av varje versions funktioner |
|
|
Ladda ned SQL Server Express 2017 |
|
|
Ladda ned exempeldatabaser |









