
Ovaj članak opisuje sintaksu formule i upotrebu funkcije LINEST u programu Microsoft Excel. Veze ka više informacija o pravljenju grafikona i izvršavanju regresivne analize pronaći ćete u odeljku Takođe pogledajte.
Opis
Funkcija LINEST izračunava statistiku za liniju pomoću metoda „najmanjih kvadrata“ da bi se izračunale prava linija koja najbolje odgovara vašim podacima, a zatim daje niz koji tu liniju opisuje. Funkciju LINEST možete i da kombinujete sa drugim funkcijama da biste izračunali statistiku za druge tipove modela koji imaju linearne nepoznate parametre, kao što su polinomski, logaritamski, eksponencijalni i potencijalni redovi. Ova funkcija mora da se unese kao formula niza zato što daje niz vrednosti. U ovom članku uputstva se nalaze posle primera.
Jednačina za liniju je:
y = mx + b
– ili –
y = m1x1 + m2x2 + ... + b
ako postoji više opsega x vrednosti gde su zavisne y vrednosti funkcija nezavisnih x vrednosti. M vrednosti su koeficijenti koji odgovaraju svakoj x vrednosti, a b je konstantna vrednost. Imajte u vidu da y, x i m mogu da budu vektori. Niz koji funkcija LINEST daje je {mn;mn-1;...;m1;b}. Funkcija LINEST takođe može da vrati dodatnu statistiku regresije.
Sintaksa
LINEST(poznati_y, [poznati_x], [konstanta], [statistika])
Sintaksa funkcije LINEST ima sledeće argumente:
Sintaksa
-
poznati_y Obavezno. Skup y vrednosti koji vam je već poznat iz relacije y = mx + b.
-
Ako opseg argumenta poznati_y predstavlja jednu kolonu, svaka kolona argumenta poznati_x tumači se kao zasebna promenljiva.
-
Ukoliko se opseg argumenta poznati_y nalazi u jednom redu, svaki red argumenta poznati_x tumači se kao zasebna promenljiva.
-
-
poznati_x Opcionalno. Skup x vrednosti koji vam već može biti poznat iz relacije y = mx + b.
-
Opseg argumenta poznati_x može da sadrži jedan ili više skupova promenljivih. Ako se koristi samo jedna promenljiva, argumenti poznati_y i poznati_x mogu da budu opsezi bilo kog oblika, sve dok imaju jednake dimenzije. Ukoliko se koristi više promenljivih, argument poznati_y mora biti vektor (to jest, opseg visine jednog reda ili širine jedne kolone).
-
Ako je argument poznati_x izostavljen, podrazumeva se da je to niz {1,2,3,...} koji ima istu veličinu kao argument poznati_y.
-
-
konstanta Opcionalno. Logička vrednost kojom se određuje da li će konstanta b biti jednaka 0.
-
Ako argument konstanta ima vrednost TRUE ili je izostavljen, b se računa normalno.
-
Ukoliko argument konstanta ima vrednost FALSE, b je jednako 0, a m vrednosti su podešene tako da se uklapaju u y = mx.
-
-
statistika Opcionalno. Logička vrednost koja određuje da li će se vratiti dodatna statistika regresije.
-
Ako statistika ima vrednost TRUE, funkcija LINEST daje dodatnu statistiku regresije; kao rezultat toga, dobijeni niz je {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2,sey; F,df; ssreg,ssresid}.
-
Ukoliko je argument statistika FALSE ili izostavljen, funkcija LINEST daje samo m koeficijente i konstantu b.
Dodatna statistika regresije ide sledećim redom.
-
|
Statistika |
Opis |
|---|---|
|
se1;se2;...;sen |
Standardne vrednosti greške za koeficijente m1;m2;...;mn. |
|
seb |
Standardna vrednost greške za konstantu b (seb = #N/A ako argument konstanta ima vrednost FALSE). |
|
r2 |
Koeficijent determinacije. Upoređuje predviđene i stvarne y vrednosti i opsege u vrednosti od 0 do 1. Ako je 1, onda postoji savršena korelacija u uzorku – ne postoji razlika između predviđene y vrednosti i stvarne y vrednosti. S druge strane gledano, ukoliko je koeficijent determinacije 0, jednačina regresije nije od pomoći u predviđanju y vrednosti. Informacije o tome kako seizračunava 2 potražite u odeljku "Primedke" u nastavku ove teme. |
|
sey |
Standardna greška za y predviđanja. |
|
F |
F statistika ili F posmatrana vrednost. Koristite F statistiku da biste odredili da li se posmatran odnos između zavisnih i nezavisnih promenljivih pojavljuje slučajno. |
|
df |
Stepeni slobode. Koristite stepene slobode da biste pronašli F kritične vrednosti u statističkoj tabeli. Uporedite vrednosti koje ste pronašli u tabeli sa onima koje je dala F statistika pomoću funkcije LINEST da biste utvrdili nivo sigurnosti modela. Za informacije o tome kako se računa df, pogledajte „Primedbe" kasnije u nastavku ove teme. Primer 4 prikazuje korišćenje F i df. |
|
ssreg |
Regresija zbira kvadrata. |
|
ssresid |
Ostatak zbira kvadrata. Za informacije o tome kako se računa ssreg i ssresid pogledajte „Primedbe" u nastavku ove teme. |
Sledeća ilustracija prikazuje redosled dobijanja dodatne statistike regresije.

Primedbe
-
Možete da opišete bilo koju pravu liniju sa nagibom i y odsečak:
Nagib (m):
Da biste pronašli nagib linije, koji se često piše kao m, uzmite dve tačke na liniji, (x1,y1) i (x2,y2); nagib je jednak (y2 – y1)/(x2 - x1).Y odsečak (b):
Y odsečak linije, koji se često piše kao b, jeste vrednost y u tački u kojoj linija prelazi y osu.Jednačina prave linije je y = mx + b. Kada znate vrednosti m i b, možete da izračunate bilo koju tačku na liniji tako što ćete y ili x vrednost uneti u tu jednačinu. Takođe možete da koristite funkciju TREND.
-
Kada imate samo jednu nezavisnu x promenljivu, možete da obezbedite nagib i y odsečak vrednosti direktno korišćenjem sledećih formula:
Nagib:
=INDEX(LINEST(known_y,known_x,1)Y odsečak:
=INDEX(LINEST(known_y,known_x,2) -
Tačnost linije izračunate pomoću funkcije LINEST zavisi od stepena rasejanosti u vašim podacima. Što su podaci više linearni, to je precizniji LINEST model. LINEST koristi metod najmanjih kvadrata za određivanje najboljeg uklapanja podataka. Kada imate samo jednu nezavisnu x promenljivu, računanja za m i b su zasnovana na sledećim formulama:
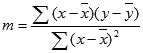
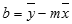
gde su x i y srednje vrednosti, tj., x = AVERAGE(poznati x) i y = AVERAGE(poznati_y).
-
Funkcije line-and curve-fitting funkcije LINEST i LOGEST mogu da izračunaju najbolju prave linije ili eksponencijalnu krivu koja odgovara vašim podacima. Međutim, morate da odlučite koji od ova dva rezultata najbolje odgovara vašim podacima. Možete da izračunate oznake TREND(known_y, known_x) za pravu liniju ili GROWTH(known_y, known_x) za eksponencijalnu krivu. Ove funkcije, bez new_x argumenta, vraćaju niz y vrednosti koje su predviđene duž te linije ili krive kod stvarnih tačaka podataka. Zatim možete da uporedite predviđene vrednosti sa stvarnim vrednostima. Trebalo bi da ih prikažete u grafikonu kako biste videli vizuelno poređenje.
-
U analizi regresije program Excel za svaku tačku računa kvadratnu razliku između y vrednosti koja je za tu tačku predviđena i njene stvarne y vrednosti. Zbir tih kvadratnih razlika se zove ostatak zbira kvadrata, ssresid. Excel nakon toga računa ukupan zbir kvadrata, sstotal. Kada je argument const = TRUE ili je izostavljen, ukupan zbir kvadrata je zbir kvadratnih razlika između stvarnih y vrednosti i proseka y vrednosti. Kada je argument const = FALSE, ukupan zbir kvadrata je zbir kvadrata stvarnih y vrednosti (bez oduzimanja prosečne y vrednosti od svake pojedinačne y vrednosti). Nakon toga se regresivni zbir kvadrata, ssreg, može izračunati na sledeći način: ssreg = sstotal - ssresid. Što je manji ostatak zbira kvadrata, u poređenju sa ukupnim zbirom kvadrata, veća je vrednost koeficijenta determinacije, r2, što je pokazatelj koliko dobro jednačina dobijena regresivnom analizom objašnjava odnos između promenljivih. Vrednost r2 jednaka je ssreg/sstotal.
-
U nekim slučajevima, neke X kolone (pretpostavljaju da su Y i X u kolonama) možda neće imati dodatnu predvidljivu vrednost u prisustvu drugih X kolona. Drugim rečima, eliminisanje nekih X kolona može dovesti do predviđenih Y vrednosti koje su podjednako tačne. U tom slučaju bi trebalo izostaviti ove suvišne X kolone iz modela regresije. Ovaj fenomen se naziva "kolinarnost" zato što se svaka suvišna X kolona može izraziti kao zbir višestrukih x kolona koje nisu redundantne. Funkcija LINEST proverava kolinarnost i uklanja sve suvišne X kolone iz modela regresije kada ih identifikuje. Uklonjene X kolone mogu se prepoznati u LINEST rezultatu kao da ima 0 koeficijenta pored 0 se vrednosti. Ako se neke kolone uklone kao redundantne, to utiče na df zato što df zavisi od broja X kolona koje se zapravo koriste u prediktivne svrhe. Detalje o procjeni df potražite u članku 4. primer. Ako se df promeni zato što su redundantne X kolone uklonjene, to utiče i na vrednosti sey i F. Kolinarnost bi trebalo da bude relativno retka u praksi. Međutim, jedan slučaj u kojem se verovatnije javlja jeste kada neke X kolone sadrže samo 0 i 1 vrednosti kao indikatore toga da li je tema u eksperimentu ili nije član određene grupe. Ako je argument konstanta = TRUE ili je izostavljen, funkcija LINEST efikasno umeće dodatnu X kolonu sa svim 1 vrednostima da bi modelovala odsečak. Ako imate kolonu sa brojem 1 za svaku temu ako je muško ili 0 ako nije, a imate i kolonu sa brojem 1 za svaku temu ako je ženska, ili 0 ako nije, ova druga kolona je suvišna zato što se stavke u njemu mogu dobiti od oduzimanjem stavke u koloni "indikator muškog pola" od stavke u dodatnoj koloni svih 1 vrednosti koje dodaje funkcija LINEST .
-
Vrednost df se izračunava na sledeći način u slučaju da se nijedna X kolona ne uklanja iz modela zbog kolinearnosti: ukoliko postoje k kolone argumenta poznati_x, a argument konstanta = TRUE ili je izostavljen, onda je df = n – k – 1. Ako je argument konstanta = FALSE, onda je df = n - k. U oba slučaja, svaka X kolona koja je uklonjena zbog kolinearnosti povećava vrednost df za 1.
-
Prilikom unosa konstante niza (poput poznati_x) kao argumenta, koristite zareze da biste razdvojili vrednosti u istom redu, a tačku i zarez da biste razdvojili redove. Znakovi za razdvajanje mogu se razlikovati u zavisnosti od regionalnih postavki.
-
Obratite pažnju na to da y vrednosti koje su predviđene jednačinom regresije možda nisu ispravne ukoliko se nalaze izvan opsega y vrednosti koji ste koristili da odredite jednačinu.
-
Osnovni algoritam koji se koristi u funkciji LINEST razlikuje se od osnovnog algoritma koji se koristi u funkcijama SLOPE i INTERCEPT. Razlika između ovih algoritama može prouzrokovati različite rezultate, kada su podaci neodređeni i kolinearni. Na primer, ako tačke podataka argumenta poznati_y iznose 0, a tačke podataka argumenta poznati_x iznose 1:
-
LINEST daje vrednost 0. Algoritam funkcije LINEST je dizajniran tako da za kolinearne podatke daje razumne rezultate, a u ovom slučaju se može pronaći najmanje jedan odgovor.
-
SLOPE i INTERCEPT daju #DIV/0! grešku. Algoritam funkcija SLOPE i INTERCEPT dizajniran je da potraži samo jedan odgovor, a u ovom slučaju može da postoji više odgovora.
-
-
Pored korišćenja funkcije LOGEST za izračunavanje statističkih podataka o drugim tipovima regresije, možete da koristite funkciju LINEST za izračunavanje opsega drugih tipova regresije tako što ćete funkcije promenljivih x i y uneti kao x i y grupe za funkciju LINEST. Na primer, sledeća formula:
=LINEST(yvrednosti, xvrednosti^COLUMN($A:$C))
funkcioniše kada imate jednu kolonu y-vrednosti i jednu kolonu x-vrednosti za izračunavanje kubne aproksimacije (aproksimacije pomoću polinoma trećeg stepena) obrasca:
y = m1*x + m2*x^2 + m3*x^3 + b
Ovu formulu možete da podesite za izračunavanje drugih tipova regresije, ali u nekim slučajevima ćete možda morati da podesite vrednosti rezultata i druge statističke podatke.
-
Vrednost F-testa koju vraća funkcija LINEST razlikuje se od vrednosti F-testa koju vraća funkcija FTEST. Funkcija LINEST vraća F statistiku, a funkcija FTEST vraća verovatnoću.
Primeri
1. primer – kosina i Y presek
Kopirajte date primere podataka u sledeću tabelu i nalepite ih u ćeliju A1 novog radnog lista u programu Excel. Ako želite da formule izračunaju rezultate, izaberite formule, pritisnite taster F2, a zatim pritisnite taster Enter. Ako je potrebno, možete prilagoditi širinu kolona kako biste videli sve podatke u njima.
|
Poznato y |
Poznato x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Rezultat (nagib) |
Rezultat (y-odsečak) |
|
2 |
1 |
|
Formula (formula niza u ćelijama A7:B7) |
|
|
=LINEST(A2:A5,B2:B5,,FALSE) |
2. primer – prosta linearna regresija
Kopirajte date primere podataka u sledeću tabelu i nalepite ih u ćeliju A1 novog radnog lista u programu Excel. Ako želite da formule izračunaju rezultate, izaberite formule, pritisnite taster F2, a zatim pritisnite taster Enter. Ako je potrebno, možete prilagoditi širinu kolona kako biste videli sve podatke u njima.
|
Mesec |
Prodaja |
|---|---|
|
1 |
$3,100 |
|
2 |
$4,500 |
|
3 |
$4,400 |
|
4 |
$5,400 |
|
5 |
$7,500 |
|
6 |
$8,100 |
|
Formula |
Rezultat |
|
=SUM(LINEST(B1:B6, A1:A6)*{9,1}) |
11.000 din. |
|
Izračunava procenu prodaje u devetom mesecu, na osnovu prodaje od prvog do šestog meseca. |
3. primer – višestruka linearna regresija
Kopirajte date primere podataka u sledeću tabelu i nalepite ih u ćeliju A1 novog radnog lista u programu Excel. Ako želite da formule izračunaju rezultate, izaberite formule, pritisnite taster F2, a zatim pritisnite taster Enter. Ako je potrebno, možete prilagoditi širinu kolona kako biste videli sve podatke u njima.
|
Površina poda (x1) |
Kancelarije (x2) |
Ulazi (x3) |
Starost (x4) |
Procenjena vrednost (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
142.000 din. |
|
2333 |
2 |
2 |
12 |
144.000 din. |
|
2356 |
3 |
1,5 |
33 |
151.000 din. |
|
2379 |
3 |
2 |
43 |
150.000 din. |
|
2402 |
2 |
3 |
53 |
139.000 din. |
|
2425 |
4 |
2 |
23 |
169.000 din. |
|
2448 |
2 |
1,5 |
99 |
126.000 din. |
|
2471 |
2 |
2 |
34 |
142.900 din. |
|
2494 |
3 |
3 |
23 |
163.000 din. |
|
2517 |
4 |
4 |
55 |
169.000 din. |
|
2540 |
2 |
3 |
22 |
149.000 din. |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Formula (dinamička formula niza uneta u A19) |
||||
|
=LINEST(E2:E12,A2:D12,TRUE,TRUE) |
4. primer – korišćenje F i r2 statistike
U prethodnom primeru koeficijent determinacije ili r2 je 0,99675 (pogledajte ćeliju A17 u rezultatu funkcije LINEST), što bi ukazalo na jaku vezu između nezavisnih promenljivih i prodajne cene. F statistiku možete da koristite da biste odredili da li su se ovi rezultati, sa tako visokom vrednošću r2, pojavili slučajno.
Pretpostavimo na trenutak da, u stvari, ne postoji nikakva veza među promenljivim, već da ste vi izvukli redak primerak od 11 poslovnih zgrada koji je dao statističku analizu koja prikazuje jaku vezu. Termin „Alfa" se koristi za verovatnoću pogrešnog zaključivanja da postoji veza.
F i df vrednosti u izlazu funkcije LINEST mogu se koristiti za procenu verovatnoće veće F vrednosti koja se slučajno pojavljuje. F se može uporediti sa kritičnim vrednostima u objavljenim tabelama F-raspodele ili funkcijom FDIST u programu Excel za izračunavanje verovatnoće veće F vrednosti koja se slučajno pojavi. Odgovarajuća F raspodela ima v1 i v2 stepen slobode. Ako je n broj tačaka podataka i konstanta = TRUE ili je izostavljen, onda je v1 = n – df – 1 i v2 = df. (Ako je konstanta = FALSE, onda je v1 = n – df i v2 = df.) Funkcija FDIST – pomoću sintakse FDIST(F,v1,v2) – vraća verovatnoću da se veća F vrednost pojavljuje slučajno. U ovom primeru, df = 6 (ćelija B18) i F = 459,753674 (ćelija A18).
Pod pretpostavkom da je alfa vrednost 0,05, v1 = 11 – 6 – 1 = 4, a v2 = 6, kritičan nivo F je 4,53. Pošto je F = 459,753674 mnogo veće od 4,53, veoma je malo verovatno da se tako visoka F vrednost slučajno dogodila. (Ako je alfa = 0,05, hipoteza da ne postoji odnos između known_y i known_x ćelija treba da bude odbijena kada F premaši kritičan nivo, 4,53.) Funkciju FDIST možete da koristite u programu Excel da biste dobili verovatnoću da se F vrednost tako visoka slučajno pojavila. Na primer, FDIST(459,753674, 4, 6) = 1,37E-7, što je veoma mala verovatnoća. Možete zaključiti, pronalaženjem kritičnog nivoa F u tabeli ili korišćenjem funkcije FDIST , da je jednačina regresije korisna za predviđanje procenjene vrednosti office zgrada u ovoj oblasti. Ne zaboravite da je od suštinske važnosti da koristite ispravne vrednosti v1 i v2 koje su izračunate u prethodnom pasusu.
5. primer – izračunavanje t-statistike
Još jedan hipotetički test će utvrditi da li je svaki koeficijent nagiba koristan u predviđanju procenjene vrednosti poslovne zgrade u primeru 3. Na primer, za testiranje koeficijenta za starost u statističke svrhe, podelite -234,24 (koeficijent nagiba za starost) sa 13,268 (predviđena standardna greška koeficijenata za starost u ćeliji A15). Sledi t posmatrana vrednost:
t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
Ukoliko je apsolutna vrednost t dovoljno visoka, može se zaključiti da je koeficijent nagiba koristan u predviđanju procenjene vrednosti poslovne zgrade u primeru 3. Sledeća tabela prikazuje apsolutne vrednosti 4 t posmatrane vrednosti.
Ukoliko pogledate tabelu u statističkom priručniku, videćete da je t kritična vrednost, sa dva kraja, sa 6 stepeni slobode i Alfa = 0,05 je 2,447. Ova kritična vrednost se takođe može pronaći pomoću funkcije TINV u programu Excel. TINV(0,05;6) = 2,447. Budući da je apsolutna vrednost t (17,7) veća od 2,447, starost je važna promenljiva u predviđanju procenjene vrednosti poslovne zgrade. Svaka druga nezavisna promenljiva može da se na sličan način testira u statističke svrhe. Slede t posmatrane vrednosti za svaku nezavisnu promenljivu.
|
Promenljiva |
t posmatrana vrednost |
|---|---|
|
Površina poda |
5,1 |
|
Broj kancelarija |
31,3 |
|
Broj ulaza |
4,8 |
|
Starost |
17,7 |
Sve ove vrednosti imaju apsolutnu vrednost veću od 2,447. Stoga su sve promenljive koje se koriste u jednačini regresije korisne za predviđanje procenjene vrednosti poslovnih zgrada u ovom području.









