
Po przeprowadzeniu migracji danych z programu Access do programu SQL Server masz już bazę danych klient/serwer, która może być rozwiązaniem lokalnym lub hybrydowym w chmurze platformy Azure. W każdym przypadku program Access jest teraz warstwą prezentacji, a program SQL Server jest warstwą danych. Teraz nadszedł czas na ponowne przemyślenie aspektów swojego rozwiązania, a zwłaszcza wydajności zapytań, zabezpieczeń i ciągłości działania firmy, dzięki czemu możesz ulepszyć i skalować swoje rozwiązanie bazy danych.
Użytkownik programu Access, który po raz pierwszy zapoznaje się z dokumentacją programu SQL Server i platformy Azure, może poczuć zniechęcenie. Ta sytuacja aż się prosi o przewodnik, który zapozna Cię z najważniejszymi informacjami, które mają dla Ciebie znaczenie. Po zakończeniu tej wycieczki możesz rozpocząć poznawanie postępów w dziedzinie technologii baz danych i wybrać się w dłuższą podróż.
W tym artykule
|
Zarządzanie bazą danych Zachowanie ciągłości działania Zabezpieczenia programu SQL Server |
Zapytania i powiązane tematy |
Typy danych |
Różne Praca z danymi hierarchicznymi |
Zachowanie ciągłości działania
W przypadku rozwiązania w programie Access zadbaj o zapewnienie, że pracuje ono z minimalnymi przerwami, ale opcje dotyczące bazy danych zaplecza w programie Access są ograniczone. Tworzenie kopii zapasowej bazy danych programu Access jest bardzo istotne dla ochrony danych, ale wymaga przejścia użytkowników w tryb offline. Ponadto istnieją niezaplanowane przestoje powodowane przez modernizacje sprzętu/uaktualnienia oprogramowania podczas konserwacji, przerwy w działaniu sieci lub zasilania, awarie sprzętu, naruszenia zabezpieczeń a nawet cyberataki. W celu zminimalizowania przestojów i wpływu na działalność firmy możesz utworzyć kopię zapasową bazy danych programu SQL Server, gdy jest ona używana. Ponadto program SQL Server oferuje także strategie wysokiej dostępności (HA) i odzyskiwania po awarii (DR). Te dwie połączone technologie są nazywane HADR. Aby uzyskać więcej informacji, zobacz Zapewnianie ciągłości działania i odzyskiwanie bazy danych oraz Zachowanie ciągłości działania firmy za pomocą programu SQL Server (e-book).
Kopia zapasowa podczas używania
Program SQL Server używa procesu tworzenia kopii zapasowej online, który może wystąpić podczas działania bazy danych. Możesz wykonać pełną kopię zapasową, częściową kopię zapasową lub kopię zapasową pliku. Kopia zapasowa kopiuje dane i dzienniki transakcji w celu zapewnienia pełnej operacji przywracania. Szczególnie w przypadku rozwiązania lokalnego należy zdawać sobie sprawę z różnic między opcjami prostego i pełnego odzyskiwania oraz z ich wpływu na przyrost dziennika transakcji. Aby uzyskać więcej informacji, zobacz Modele odzyskiwania.
Większość operacji tworzenia kopii zapasowych występuje od razu, z wyjątkiem operacji zarządzania plikami i zmniejszania bazy danych. Natomiast w przypadku próby utworzenia lub usunięcia pliku bazy danych w trakcie operacji tworzenia kopii zapasowej operacja zakończy się niepowodzeniem. Aby uzyskać więcej informacji, zobacz Omówienie tworzenia kopii zapasowej.
HADR
Dwie najczęściej stosowane techniki pozwalające uzyskać wysoką dostępność i ciągłość działania firmy to klonowanie i klastrowanie. Program SQL Server integruje technologię klonowania i klastrowania za pomocą opcji „Always On Failover Cluster Instances (Zawsze włączone wystąpienia klastra trybu failover)” i „Always On Availability Groups (Zawsze włączone grupy dostępności)”.
Klonowanie to rozwiązanie zapewnienia ciągłości na poziomie bazy danych, które obsługuje prawie natychmiastowe przejście w tryb failover, utrzymując rezerwową bazę danych, pełną kopię lub kopię lustrzaną aktywnej bazy danych na osobnym sprzęcie. Może to działać w trybie synchronicznym (wysokie bezpieczeństwo), w którym transakcja przychodząca jest zatwierdzona na wszystkich serwerach w tym samym czasie, lub w trybie asynchronicznym (wysoka wydajność), w którym transakcja przychodząca jest zatwierdzona dla aktywnej bazy danych, a następnie w pewnym wstępnie określonym punkcie jest kopiowana do lustrzanej bazy danych. Klonowanie jest rozwiązaniem na poziomie bazy danych i działa tylko w przypadku baz danych, w których jest używany model pełnego odzyskiwania.
Klastrowanie jest rozwiązaniem na poziomie serwera, które łączy serwery w jeden magazyn danych, który użytkownik widzi jako jedno wystąpienie. Użytkownicy łączą się z tym wystąpieniem, ale nigdy nie muszą wiedzieć, który serwer w wystąpieniu jest obecnie aktywny. Jeśli jeden serwer ulegnie awarii lub wymaga przełączenia w tryb offline w celu przeprowadzenia konserwacji, środowisko użytkownika nie zmieni się. Każdy serwer w klastrze jest monitorowany przez menedżera klastra przy użyciu pulsu, dzięki czemu wykrywa on, kiedy aktywny serwer w klastrze przechodzi w tryb offline, i próbuje bezproblemowo przełączać się do następnego serwera w klastrze, chociaż czas opóźnienia związany z przełączaniem jest zmienny.
Aby uzyskać więcej informacji, zobacz Always On Failover Cluster Instances (Zawsze włączone wystąpienia klastra trybu failover) i Zawsze włączone grupy dostępności: rozwiązanie wysokiej dostępności i odzyskiwania po awarii.
Zabezpieczenia programu SQL Server
Chociaż możesz chronić bazę danych programu Access za pomocą Centrum zaufania i szyfrując bazę danych, program SQL Server ma bardziej zaawansowane funkcje zabezpieczeń. Spójrzmy na trzy wyróżniające się funkcje dla użytkowników programu Access. Aby uzyskać więcej informacji, zobacz Zabezpieczanie programu SQL Server.
Uwierzytelnianie bazy danych
W programie SQL Server istnieją cztery metody uwierzytelniania baz danych, każdą z których możesz określić w parametrach połączenia ODBC. Aby uzyskać więcej informacji, zobacz Łączenie z danymi lub importowanie ich z bazy danych Azure SQL Server Database. Każda z tych metod ma swoje zalety.
Zintegrowane uwierzytelnianie systemu Windows Użyj poświadczeń systemu Windows, aby zweryfikować użytkownika, role zabezpieczeń i ograniczyć dostęp użytkowników do funkcji i danych. Możesz korzystać z poświadczeń domeny i łatwo zarządzać prawami użytkowników w Twojej aplikacji. Opcjonalnie wprowadź Nazwy główne usług (SPN). Aby uzyskać więcej informacji, zobacz Wybieranie trybu uwierzytelniania.
Uwierzytelnianie programu SQL Server Użytkownicy muszą nawiązywać połączenia przy użyciu poświadczeń skonfigurowanych w bazie danych, wpisując identyfikator logowania i hasło podczas pierwszego w sesji uzyskiwania dostępu do bazy danych. Aby uzyskać więcej informacji, zobacz Wybieranie trybu uwierzytelniania.
Zintegrowane uwierzytelnianie usługi Azure Active Directory Połącz się z bazą danych Azure SQL Server Database przy użyciu usługi Azure Active Directory. W przypadku skonfigurowania uwierzytelniania usługi Azure Active Directory nie jest wymagane żadne dodatkowe podanie identyfikatora logowania i hasła. Aby uzyskać więcej informacji, zobacz Łączenie z bazą danych SQL przy użyciu uwierzytelniania usługi Azure Active Directory.
Uwierzytelnianie za pomocą hasła w usłudze Active Directory Połącz się przy użyciu poświadczeń skonfigurowanych w usłudze Azure Active Directory, wpisując nazwę logowania i hasło. Aby uzyskać więcej informacji, zobacz Łączenie z bazą danych SQL przy użyciu uwierzytelniania usługi Azure Active Directory.
Porada Za pomocą wykrywania zagrożeń możesz otrzymywać alerty o odbiegających od normy działaniach bazy danych oznaczających potencjalne zagrożenia bezpieczeństwa w bazie danych usługi Azure SQL Server. Aby uzyskać więcej informacji, zobacz Wykrywanie zagrożeń w bazie danych SQL.
Zabezpieczenia aplikacji
Program SQL Server ma dwie funkcje zabezpieczeń na poziomie aplikacji, z których można korzystać w programie Access.
Dynamiczne maskowanie danych Ukrywaj poufne informacje, maskując je przed nieuprawnionymi użytkownikami. Na przykład możesz maskować numer PESEL (częściowo lub w całości).
 Częściowa maska danych |
 Pełna maska danych |
Maskę danych można zdefiniować na kilka sposobów i można je stosować do różnych typów danych. Maskowanie danych jest oparte na zasadach na poziomie tabel i kolumn dla określonego zestawu użytkowników i jest stosowane w czasie rzeczywistym do zapytania. Aby uzyskać więcej informacji, zobacz Dynamiczne maskowanie danych.
Zabezpieczenia na poziomie wiersza Za pomocą zabezpieczeń na poziomie wiersza możesz kontrolować dostęp do określonych wierszy bazy danych zawierających poufne informacje na podstawie charakterystyki użytkownika. System bazy danych zastosuje te ograniczenia dostępu, co spowoduje, że system zabezpieczeń jest bardziej niezawodny i wydajny.

Istnieją dwa typy predykatów zabezpieczeń:
-
Predykat filtru filtruje wiersze z zapytania. Filtr jest przezroczysty, a użytkownik końcowy nie zauważa żadnego filtrowania.
-
Predykat blokowy zapobiega nieautoryzowanej akcji i zgłasza wyjątek, jeśli nie można wykonać akcji.
Aby uzyskać więcej informacji, zobacz Zabezpieczenia na poziomie wiersza.
Ochrona danych za pomocą szyfrowania
Zabezpieczanie danych magazynowanych, przesyłanych i danych podczas użytkowania bez wpływu na wydajność bazy danych. Aby uzyskać więcej informacji, zobacz Szyfrowanie programu SQL Server.
Szyfrowanie danych magazynowanych Aby zabezpieczyć dane osobowe przed atakami z nośnikami w trybie offline w warstwie pamięci fizycznej, należy użyć szyfrowania danych magazynowanych, zwanego także przezroczystym szyfrowaniem danych (TDE). Oznacza to, że Twoje dane są chronione nawet w przypadku kradzieży lub nieprawidłowej utylizacji nośnika fizycznego. TDE wykonuje w czasie rzeczywistym szyfrowanie i odszyfrowywanie baz danych, kopii zapasowych i dzienników transakcji bez konieczności wprowadzania jakichkolwiek zmian w Twojej aplikacji.
Szyfrowanie podczas przesyłania W celu ochrony przed śledzeniem i „atakami typu man-in-the-middle” możesz zaszyfrować dane przesyłane przez sieć. Program SQL Server obsługuje standard TLS (Transport Layer Security) 1.2 w celu zapewnienia wysokiego poziomu bezpieczeństwa komunikacji. Protokół strumienia danych tabelarycznych (TDS) jest używany również do ochrony komunikacji za pośrednictwem niezaufanych sieci.
Szyfrowanie używane w kliencie Do ochrony danych osobowych podczas używania służy funkcja Always Encrypted. Dane osobowe są szyfrowane i odszyfrowywane przez sterownik na komputerze klienckim bez ujawniania kluczy szyfrowania w aparacie bazy danych. W efekcie dane zaszyfrowane są widoczne tylko dla osób odpowiedzialnych za zarządzanie tymi danymi, a nie innych użytkowników o wysokich uprawnieniach, którzy nie powinni mieć dostępu. W zależności od wybranego typu szyfrowania funkcja Always Encrypted może ograniczać niektóre funkcje bazy danych, takie jak wyszukiwanie, grupowanie i indeksowanie zaszyfrowanych kolumn.
Obsługa obaw dotyczących prywatności
Zagadnienia związane z ochroną prywatności są na tyle powszechne, że Unia Europejska określiła wymagania prawne, wprowadzając Ogólne Rozporządzenie o Ochronie Danych (RODO). Na szczęście zaplecze programu SQL Server jest dobrze przystosowane do odpowiadania na te wymagania. Zastanów się nad wdrożeniem RODO w trzech krokach.

Krok 1. Ocena zagrożenia zgodności i zarządzanie nim
RODO wymaga identyfikowania i inwentaryzacji informacji osobistych znajdujących się w tabelach i plikach. Te informacje mogą być dowolne, poczynając od nazwy, zdjęcia, adresu e-mail, szczegółów dotyczących banku, wpisów w witrynach internetowych sieci społecznościowych, informacji medycznych, a nawet adresu IP.
Nowe narzędzie,Klasyfikacja i odnajdywanie danych SQL, wbudowane w program SQL Server Management Studio, ułatwia odnajdowanie, klasyfikowanie, etykietowanie i raportowanie dotyczące wrażliwych danych dzięki zastosowaniu dwóch atrybutów metadanych do kolumn:
-
Etykiety W celu zdefiniowania wrażliwości danych.
-
Typy informacji W celu zapewnienia dodatkowego stopnia szczegółowości dotyczącego typów danych przechowywanych w kolumnie.
Innym mechanizmem odnajdowania, którego można używać, jest wyszukiwanie pełnotekstowe, które obejmuje stosowanie predykatów CONTAINS i FREETEXT oraz funkcji zwracających zestaw wierszy, takich jak CONTAINSTABLE i FREETEXTTABLE do użycia z instrukcją SELECT. Za pomocą wyszukiwania pełnotekstowego możesz przeszukiwać tabele w celu odnalezienia wyrazów, kombinacji wyrazów lub odmian wyrazów, takich jak synonimy lub formy fleksyjne. Aby uzyskać więcej informacji, zobacz Wyszukiwanie pełnotekstowe.
Krok 2. Ochrona informacji osobistych
RODO wymaga zabezpieczania danych osobowych i ograniczania do nich dostępu. Oprócz standardowych czynności, jakie należy wykonać w celu zarządzania dostępem do sieci i zasobów, takich jak ustawienia zapory, można użyć funkcji zabezpieczeń programu SQL Server, aby ułatwić kontrolę dostępu do danych:
-
Uwierzytelnianie programu SQL Server pozwala zarządzać tożsamością użytkownika i zapobiegać nieautoryzowanemu dostępowi.
-
Zabezpieczenia na poziomie wiersza w celu ograniczenia dostępu do wierszy w tabeli jest oparte na relacji między użytkownikiem a tymi danymi.
-
Dynamiczne maskowanie danych umożliwia ograniczenie ujawnienia danych osobowych przez ich maskowanie przed nieuprawnionymi użytkownikami.
-
Szyfrowanie pozwalające zapewnić, że dane osobowe są chronione podczas przesyłania i magazynowania oraz są chronione przed naruszeniem, w tym po stronie serwera.
Aby uzyskać więcej informacji, zobacz Zabezpieczenia programu SQL Server.
Krok 3. Skuteczne odpowiadanie na żądania
RODO wymaga utrzymywania rejestrów związanych z przetwarzaniem danych osobowych i udostępniania tych rejestrów organom nadzorczym na żądanie. Jeśli wystąpią problemy, a w tym z przypadkowym uwolnieniem danych, mechanizmy kontroli ochrony pozwalają szybko zareagować. Jeśli potrzebne są raporty, dane muszą być szybko dostępne. Na przykład RODO wymaga podania do organu nadzoru danych związanych z naruszeniem danych osobowych „nie później niż w terminie 72 godzin po stwierdzeniu naruszenia”.
Program SQL Server 2017 pomaga Ci w raportowaniu zadań na kilka sposobów:
-
Audyt programu SQL Server pomaga zapewnić, że istnieją trwałe rejestry dostępu do bazy danych i działań przetwarzania. Wykonuje on szczegółowy audyt, który śledzi działania wykonywane w bazie danych, co ułatwia zrozumienie i zidentyfikowanie potencjalnych zagrożeń, podejrzeń o nadużycie i naruszeń zabezpieczeń. Możesz łatwo przeprowadzać dochodzenia dotyczące danych.
-
Tabele danych czasowych programu SQL Server to tabele użytkownika z wersjami systemowymi zaprojektowane w taki sposób, aby zachować pełną historię zmian danych. Umożliwiają one łatwe raportowanie i analizę punktu w czasie.
-
Ocena luk w zabezpieczeniach SQL pomaga w wykryciu problemów dotyczących zabezpieczeń i uprawnień. W przypadku wykrycia problemu możesz również przejść do szczegółów raportów skanowania bazy danych, aby znaleźć działania mające na celu rozwiązanie problemu.
Aby uzyskać więcej informacji, zobacz Tworzenie platformy zaufania (e-book) i Podróż do zapewnienia zgodności z RODO.
Tworzenie migawek bazy danych
Migawka bazy danych to statyczny widok bazy danych programu SQL Server w danym momencie, który jest dostępny tylko do odczytu. Chociaż możesz skopiować plik bazy danych programu Access w celu skutecznego utworzenia migawki bazy danych, program Access nie ma wbudowanej metodologii, jak program SQL Server. Migawkę bazy danych można stosować do pisania raportów na podstawie danych z chwili tworzenia migawki bazy danych. Migawkę bazy danych można również stosować do przechowywania danych historycznych, na przykład dla każdego kwartału obrachunkowego używanego do sporządzania raportów na koniec okresu. Zalecamy stosowanie następujących najważniejszych wskazówek:
-
Nadaj nazwę migawce Każda migawka bazy danych wymaga unikatowej nazwy bazy danych. Dodaj przeznaczenie i przedział czasu do nazwy, aby ułatwić identyfikację. Na przykład, aby uzyskać migawkę bazy danych firmy AdventureWorks trzy razy dziennie w odstępach 6 godzinnych od godziny 6:00 do 18:00, na podstawie zegara w formacie 24-godzinnym, nadaj im nazwę AdventureWorks_migawka_0600, AdventureWorks_migawka_1200 i AdventureWorks_migawka_1800.
-
Ograniczanie liczby migawek Każda migawka bazy danych będzie trwała, dopóki nie zostanie jawnie usunięta. Ponieważ każda migawka będzie coraz większa, może być konieczne zaoszczędzenie przestrzeni dyskowej przez usunięcie starszej migawki po utworzeniu nowej. Jeśli na przykład sporządzasz codzienne raporty, przechowuj migawkę bazy danych przez 24 godziny, a następnie usuń ją i zastąp nową.
-
Nawiązywanie połączenia z właściwą migawką Aby można było korzystać z migawki bazy danych, fronton programu Access musi znać właściwą lokalizację. Po podstawianiu nowej migawki zamiast istniejącej musisz przekierować program Access do nowej migawki. Dodaj logikę do frontonu programu Access, aby upewnić się, że łączysz się z właściwą migawką bazy danych.
Oto jak można utworzyć migawkę bazy danych:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Aby uzyskać więcej informacji, zobacz Migawki bazy danych (SQL Server).
Kontrola współbieżności
Jeśli wiele osób jednocześnie próbuje zmodyfikować dane w bazie danych, jest potrzebny system kontrolek, aby zmiany wprowadzone przez jedną osobę nie miały negatywnego wpływu na zmiany innej osoby. Nazywa się to kontrolą współbieżności i istnieją dwie podstawowe strategie blokowania: pesymistyczna i optymistyczna. Blokowanie może zapobiec modyfikowaniu danych przez użytkowników w sposób, który ma wpływ na innych użytkowników. Blokowanie pomaga także zapewnić integralność bazy danych, zwłaszcza w przypadku zapytań, które w przeciwnym przypadku mogą dawać nieoczekiwane wyniki. Występują istotne różnice w sposobie, w jaki programy Access i SQL Server wdrażają te strategie kontroli współbieżności.
W programie Access domyślna strategia blokowania jest optymistyczna i udziela własności blokady pierwszej osobie próbującej dokonać zapisu do rekordu. Inna osoba próbująca dokonać zapisu w tym samym rekordzie w tym samym czasie zobaczy w programie Access okno dialogowe Konflikt zapisu. Aby rozwiązać konflikt, inna osoba może zapisać rekord, skopiować go do Schowka lub zrezygnować z wprowadzonych zmian.
Za pomocą właściwości RecordLocks można również zmienić strategię kontroli współbieżności. Ta właściwość ma wpływ na formularze, raporty i kwerendy oraz ma trzy ustawienia:
-
Bez blokowania W formularzu użytkownicy mogą próbować edytować ten sam rekord jednocześnie, ale może zostać wyświetlone okno dialogowe Konflikt zapisu. W przypadku raportów rekordy nie są blokowane podczas przeglądania lub drukowania raportów. W przypadku zapytań rekordy nie są blokowane, gdy działa zapytanie. Jest to sposób programu Access na implementację optymistycznego blokowania.
-
Wszystkie rekordy W przypadku przeglądania lub drukowania raportu, lub gdy jest uruchomione zapytanie wszystkie rekordy w tabeli lub zapytaniu źródłowym są blokowane, kiedy formularz jest otwarty w widoku formularza lub widoku arkusza danych. Użytkownicy mogą odczytywać rekordy podczas zablokowania.
-
Edytowany rekord W przypadku formularzy i zapytań strona rekordów zostaje zablokowana, jak tylko dowolny użytkownik rozpocznie edytowanie dowolnego pola w rekordzie. Strona pozostaje zablokowana do momentu, kiedy użytkownik przejdzie do innego rekordu. Zatem rekord w danym momencie może być edytowany tylko przez jednego użytkownika. Jest to sposób programu Access na implementację pesymistycznego blokowania.
Aby uzyskać więcej informacji, zobacz Okno dialogowe Konfliktu zapisu i Właściwość RecordLocks.
W programie SQL Server kontrola współbieżności działa w następujący sposób:
-
Pesymistyczna Gdy użytkownik wykona akcję powodującą zastosowanie blokady, inni użytkownicy nie będą mogli wykonywać akcji, które mogłyby powodować konflikt z blokadą do czasu jej zwolnienia przez właściciela. Ta kontrola współbieżności jest używana głównie w środowiskach, w których istnieje duża rywalizacja o dane.
-
Optymistyczna W przypadku optymistycznej kontroli współbieżności użytkownicy nie blokują danych podczas ich odczytywania. Gdy użytkownik zaktualizuje dane, system sprawdzi, czy dane zostały zmienione przez innego użytkownika po ich przeczytaniu. Jeśli dane zostały zaktualizowane przez innego użytkownika, zostanie zgłoszony błąd. Zwykle użytkownik, który zobaczył komunikat o błędzie, wycofuje transakcję i rozpoczyna pracę od nowa. Ta kontrola współbieżności jest używana głównie w środowiskach, w których występuje małą rywalizacja o dane.
Typ kontroli współbieżności możesz określić, wybierając kilka poziomów izolacji transakcji, które określają poziom ochrony transakcji przed modyfikacjami wprowadzonymi przez inne transakcje za pomocą instrukcji SET TRANSACTION:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Poziom izolacji |
Opis |
|
Odczyt niezatwierdzony |
Transakcje są izolowane jedynie na tyle, aby zapewnić, że fizycznie uszkodzone dane nie są odczytywane. |
|
Odczyt zatwierdzony |
Transakcje mogą odczytywać dane wcześniej odczytane przez inną transakcję, nie czekając na ukończenie pierwszej transakcji. |
|
Odczyt powtarzalny |
Blokada odczytu i zapisu występuje dla wybranych danych do końca transakcji, ale mogą wystąpić odczyty fantomów. |
|
Migawka |
Używa wersji wiersza w celu zapewnienia spójności odczytu na poziomie transakcji. |
|
Możliwe do serializacji |
Transakcje są całkowicie izolowane od siebie. |
Aby uzyskać więcej informacji, zobacz Blokowanie transakcji i przewodnik po przechowywaniu wersji wiersza.
Optymalizowanie wydajności zapytania
Gdy działa zapytanie przekazujące programu Access, możesz skorzystać z zaawansowanych metod, za pomocą których program SQL Server spowoduje, że będzie ono działać skuteczniej.
W przeciwieństwie do bazy danych programu Access w programie SQL Server są dostępne zapytania równoległe służące do optymalizowania wykonywania zapytania i operacji indeksowania dla komputerów mających więcej niż jeden mikroprocesor (CPU). Ponieważ program SQL Server może równolegle wykonywać zapytanie lub operację indeksowania przy użyciu kilku wątków roboczych systemu, można szybko i wydajnie wykonać operację.
Zapytania są najważniejszym elementem ulepszania ogólnej wydajności Twojego rozwiązania bazy danych. Złe zapytania działają w nieskończoność, przekraczają limit czasu i zużywają zasoby, na przykład procesory CPU, pamięć i przepustowość sieci. To pogarsza dostępność krytycznych informacji biznesowych. Nawet jedno złe zapytanie może być przyczyną poważnych problemów z wydajnością Twojej bazy danych.
Aby uzyskać więcej informacji, zobacz Szybsze wykonywanie zapytań za pomocą programu SQL Server (e-book).
Optymalizacja zapytania
Kilka narzędzi współpracuje ze sobą, aby ułatwić analizowanie wydajności zapytania i ulepszanie go: Optymalizator zapytań, plany wykonywania i magazyn zapytań.
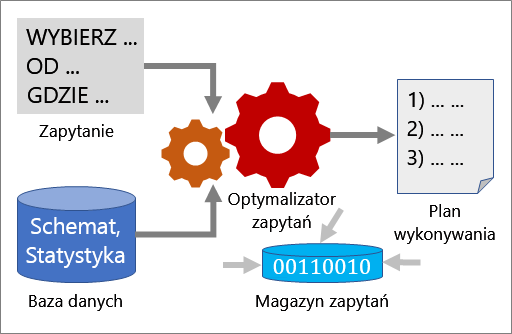
Optymalizator zapytań
Optymalizator kwerend jest jednym z najważniejszych składników programu SQL Server. Optymalizator zapytań służy do analizowania zapytania i określenia najbardziej efektywnego sposobu uzyskiwania dostępu do wymaganych danych. Dane wprowadzane do optymalizatora zapytań składają się z zapytania, schematu bazy danych (definicje tabel i indeksu) i statystyki bazy danych. Dane wyjściowe optymalizatora zapytań to plan wykonywania.
Aby uzyskać więcej informacji, zobacz Optymalizator zapytań programu SQL Server.
Plan wykonywania
Plan wykonywania jest definicją, która pozwala uporządkować tabele źródłowe, do których należy uzyskać dostęp, i metody używane do wyodrębniania danych z poszczególnych tabel. Optymalizacja to proces wybierania jednego planu wykonywania z potencjalnie wielu możliwych planów. Każdy możliwy plan wykonywania ma skojarzony koszt jako ilość użytych zasobów obliczeniowych, zaś optymalizator zapytań wybiera ten, który ma najniższy szacowany koszt.
Program SQL Server musi także dynamicznie dostosowywać się do zmieniających się warunków w bazie danych. Regresje planów wykonywania zapytań mogą mieć znaczny wpływ na wydajność. Pewne zmiany w bazie danych mogą powodować, że plan wykonywania będzie niewydajny albo nieprawidłowy w stosunku do nowego stanu bazy danych. Program SQL Server wykrywa zmiany, które unieważniają plan wykonywania, i oznacza plan jako nieważny.
Następnie należy ponownie skompilować nowy plan dla następnego połączenia, które wykona zapytanie. Do warunków unieważniających plan należą:
-
Zmiany wprowadzone w tabeli lub widoku, do których odwołuje się zapytanie (ALTER TABLE i ALTER VIEW).
-
Zmiany indeksów używanych przez plan wykonywania.
-
Aktualizacje dotyczące statystyk używanych w ramach planu wykonywania generowane jawnie na podstawie instrukcji, takich jak UPDATE STATISTICS, albo automatycznie.
Aby uzyskać więcej informacji, zobacz Plany wykonywania.
Magazyn zapytań
Magazyn zapytań zapewnia dokładniejsze informacje na temat wyboru planu wykonywania i jego wydajności. Ułatwia on rozwiązywanie problemów z wydajnością, pomagając szybko znaleźć różnice w wydajności spowodowane zmianami planu wykonywania. Magazyn zapytań zbiera dane telemetryczne, takie jak historia zapytań, plany, statystyki czasu wykonania i statystyki oczekiwania. Zaimplementuj magazyn zapytań przy użyciu instrukcji ALTER DATABASE:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Aby uzyskać więcej informacji, zobacz Monitorowanie wydajności przy użyciu magazynu zapytań.
Automatyczna korekta planu
Najłatwiejszym sposobem poprawienia wydajności zapytania jest prawdopodobnie automatyczna korekta planu, która jest funkcją dostępną w usłudze Azure SQL Database. Wystarczy ją włączyć i pozwolić jej działać. Nieustannie przeprowadza ona monitorowanie planu wykonywania i jego analizowanie, wykrywa niepoprawne plany wykonywania i automatycznie naprawia problemy z wydajnością. W tle automatyczna korekta planu wykorzystuje strategię czterech etapów: uczenia się, adaptacji, weryfikacji i powtarzania.
Aby uzyskać więcej informacji, zobacz Automatyczne dostosowywanie.
Adaptacyjne przetwarzanie zapytań
Możesz także szybciej wykonywać zapytania, przeprowadzając uaktualnienie do programu SQL Server 2017, który zawiera nową funkcję o nazwie adaptacyjne przetwarzanie zapytań. Program SQL Server dopasowuje wybór planu zapytania na podstawie charakterystyk środowiska uruchomieniowego.
Oszacowanie kardynalności przybliża liczbę przetworzonych wierszy na każdym kroku planu wykonywania. Niedokładne oszacowania mogą skutkować długim czasem reakcji na zapytanie, niepotrzebnym wykorzystywaniem zasobów (pamięci, procesora CPU i We/Wy) oraz ograniczoną przepływnością i współbieżnością. W celu dostosowania charakterystyk obciążenia aplikacji stosowane są trzy techniki:
-
Tryb wsadowy — opinia dotycząca przydzielenia pamięci Słabe oszacowania kardynalności mogą powodować, że zapytania będą się „rozlewać na dysk” lub zajmą zbyt dużo pamięci. Program SQL Server 2017 dopasowuje przyznaną pamięć na podstawie opinii o wykonaniu, usuwa rozlanie na dysk i ulepsza współbieżność powtarzających się zapytań.
-
Tryb wsadowy — sprzężenia adaptacyjne Sprzężenia adaptacyjne dynamicznie wybierają lepszy typ sprzężenia wewnętrznego (sprzężenia pętli zagnieżdżonej, sprzężenia łączące lub sprzężenia mieszane) w środowisku uruchomieniowym na podstawie rzeczywistych wierszy wejściowych. W efekcie plan może dynamicznie przełączać się na lepszą strategię dołączania podczas wykonywania.
-
Wykonywanie przeplatane Funkcje wartości tabeli z wieloma instrukcjami zazwyczaj były uważane za czarną skrzynkę przez przetwarzanie zapytań. Program SQL Server 2017 może lepiej oszacować liczbę wierszy w celu ulepszenia działań podrzędnych.
Możesz automatycznie spowodować, że obciążenia będą uprawnione do adaptacyjnego przetwarzania zapytań po włączeniu poziomu kompatybilności równego 140 dla bazy danych:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Aby uzyskać więcej informacji, zobacz Inteligentne przetwarzanie zapytań w bazach danych SQL.
Sposoby tworzenia zapytań
Program SQL Server pozwala na wykonywanie zapytań na kilka sposobów, z których każdy ma swoje zalety. Chcesz się dowiedzieć, jakie one są, więc możesz dokonać prawidłowego wyboru dla swojego rozwiązania w programie Access. Najlepszym sposobem na tworzenie zapytań języka TSQL jest interakcyjne edytowanie i testowanie ich za pomocą edytora języka Transact-SQL SQL Server Management Studio (SSMS), w którym jest używana technologia IntelliSense pomagająca wybrać odpowiednie słowa kluczowe i sprawdzić, czy nie ma błędów składniowych.
Widoki
W programie SQL Server widok przypomina wirtualną tabelę, w której dane pochodzą przynajmniej z jednej tabeli lub innego widoku. Jednak odwołania do widoków są takie jak do tabel w zapytaniach. Widok może ukrywać złożoność zapytań i pomaga zabezpieczać dane, ograniczając zestaw wierszy i kolumn. Oto przykładowy widok prosty:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
W celu zapewnienia optymalnej wydajności i edytowania wyników widoków należy utworzyć widok indeksowany, który będzie trwale istniał w bazie danych, jak tabela, będzie miał przydzieloną pamięć masową i można będzie utworzyć do niego zapytanie, jak do każdej innej tabeli. Aby korzystać z niego w programie Access, utwórz link do widoku w ten sam sposób, jak w przypadku linku do tabeli. Oto przykładowy widok indeksowany:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Istnieją jednak ograniczenia. Nie możesz zaktualizować danych, jeśli wpływa to na więcej niż jedną tabelę podstawową lub widok zawiera funkcje agregujące lub klauzulę DISTINCT. Jeśli program SQL Server zwróci komunikat o błędzie informujący o tym, że nie wiadomo, który rekord usunąć, może być konieczne dodanie wyzwalacza usuwania w tym widoku. Wreszcie nie możesz użyć klauzuli ORDER BY jak w przypadku zapytania programu Access.
Aby uzyskać więcej informacji, zobacz Widoki i Tworzenie widoków indeksowanych.
Procedury składowane
Procedura składowana to grupa zawierająca przynajmniej jedną instrukcję języka TSQL, która pobiera parametry wejściowe, zwraca parametry wyjściowe i wskazuje powodzenie lub niepowodzenie za pomocą wartości stanu. Działają one jako warstwa pośrednia między frontonem programu Access a zapleczem programu SQL Server. Procedury składowane mogą być proste, jak instrukcja SELECT, lub złożone jak dowolny program. Oto przykład:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
W przypadku użycia procedury składowanej w programie Access zwykle zwraca ona zestaw wyników z powrotem do formularza lub raportu. Może jednak wykonywać inne akcje, które nie zwracają wyników, na przykład instrukcje DDL lub DML. W przypadku użycia zapytania przekazującego należy się upewnić, że właściwość Zwraca rekordy jest odpowiednio ustawiona.
Aby uzyskać więcej informacji, zobacz Procedury składowane.
Typowe wyrażenia używane w tabelach
Typowe wyrażenia używane w tabelach (CTE) przypominają tabelę tymczasową generującą nazwany zestaw wyników. Istnieje on tylko w przypadku wykonywania jednego zapytania lub instrukcji DML. CTE są utworzone na tym samym wierszu kodu, co instrukcja SELECT lub instrukcja DML, która go używa, zaś tworzenie i używanie tymczasowej tabeli lub widoku jest zwykle procesem dwuetapowym. Oto przykład:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
Wyrażenia CTE mają kilka zalet, a w tym:
-
Ponieważ wyrażenia CTE są chwilowe, nie musisz tworzyć ich jako trwałych obiektów bazy danych, takich jak widoki.
-
W zapytaniu lub instrukcji DML można odwołać się do tego samego wyrażenia CTE więcej niż raz, ulepszając zarządzanie swoim kodem.
-
Za pomocą zapytań, które odwołują się do wyrażenia CTE, możesz zdefiniować kursor.
Aby uzyskać więcej informacji, zobacz WITH common_table_expression.
Funkcje zdefiniowane przez użytkownika
Funkcja zdefiniowana przez użytkownika (UDF) może wykonywać zapytania i obliczenia oraz zwracać wartości skalarne albo zestawy wyników danych. Są one podobne do funkcji w językach programowania akceptujących parametry, wykonujących akcję, taką jak złożone obliczenia, i zwracających wynik tej akcji jako wartość. Oto przykład:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Format UDF ma pewne ograniczenia. Na przykład nie mogą korzystać z niektórych niedeterministycznych funkcji systemowych, wykonywać instrukcji DML lub DDL, lub wykonywać dynamicznych zapytań języka SQL.
Aby uzyskać więcej informacji, zobacz Funkcje zdefiniowane przez użytkownika.
Dodawanie kluczy i indeksów
W dowolnym używanym systemie bazy danych klucze i indeksy idą ręka w rękę.
Klucze
W programie SQL Server należy pamiętać o utworzeniu kluczy podstawowych dla każdej tabeli i kluczy obcych dla poszczególnych powiązanych tabel. Funkcją w programie SQL Server równoważną typowi danych AutoNumber w programie Access jest właściwość IDENTITY, której można użyć do tworzenia wartości kluczy. Po zastosowaniu tej właściwości do dowolnej kolumny numerycznej stanie się ona tylko do odczytu i będzie utrzymywana przez system bazy danych. Po wstawieniu rekordu do tabeli zawierającej kolumnę IDENTITY system automatycznie zwiększa wartość kolumny IDENTITY o 1, rozpoczynając od wartości 1, ale możesz kontrolować te wartości za pomocą argumentów.
Aby uzyskać więcej informacji, zobacz CREATE TABLE, IDENTITY (właściwość).
Indeksy
Jak zwykle dobór indeksów to proces utrzymania równowagi między szybkością zapytania a kosztem aktualizacji. W programie Access istnieje jeden typ indeksu, ale w programie SQL Server jest ich dwanaście. Na szczęście możesz użyć optymalizatora zapytań, który pomoże Ci pewnie wybrać najbardziej efektywny indeks. W bazie danych SQL Azure możesz używać funkcji automatycznego zarządzania indeksami, funkcji automatycznego dostosowywania, która zaleca dodawanie lub usuwanie indeksów. W odróżnieniu od programu Access, w programie SQL Server musisz utworzyć własne indeksy dla kluczy obcych. W widoku indeksowanym można także tworzyć indeksy, aby zwiększyć wydajność zapytania. Wadą widoku indeksowanego jest zwiększony narzut podczas modyfikowania danych w tabelach podstawowych widoku, ponieważ należy również zaktualizować widok. Aby uzyskać więcej informacji, zobacz Przewodnik po architekturze i projektowaniu indeksów programu SQL Server i Indeksy.
Wykonywanie transakcji
Realizowanie procesu OLTP jest trudne podczas korzystania z programu Access, ale stosunkowo łatwe w programie SQL Server. Transakcja to jedna jednostka pracy, która potwierdza wszystkie zmiany danych, jeśli kończy się pomyślnie, ale wycofuje te zmiany, jeśli się nie powiedzie. Transakcja musi mieć cztery właściwości, często określane jako ACID:
-
Niepodzielność (Atomicity) Transakcja musi być niepodzielną jednostką pracy, przy czym są wykonywane wszystkie modyfikacje jej danych lub nie są wykonywane żadne operacje.
-
Spójność (Consistency) Po zakończeniu transakcja musi pozostawiać wszystkie dane w stanie spójnym. Oznacza to, że były zastosowane wszystkie reguły integralności danych.
-
Izolacja (Isolation) Zmiany wprowadzone przez współbieżne transakcje są odizolowane od bieżącej transakcji.
-
Wytrzymałość (Durability) Po ukończeniu transakcji zmiany są trwałe nawet w przypadku awarii systemu.
Transakcja służy do zapewniania gwarantowanej integralności danych, na przykład podczas pobierania gotówki z bankomatu lub automatycznego deponowania wypłaty. Możliwe jest wykonywanie transakcji jawnych, niejawnych lub transakcji w zakresie wsadu. Oto dwa przykłady w języku TSQL:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Aby uzyskać więcej informacji, zobacz Transakcje.
Korzystanie z ograniczeń i wyzwalaczy
We wszystkich bazach danych istnieją metody zapewniające integralność danych.
Ograniczenia
W programie Access więzy integralności są wymuszane w relacji między tabelami za pomocą par klucz podstawowy-klucz obcy, aktualizacji i usuwania kaskadowego oraz reguł walidacji. Aby uzyskać więcej informacji, zobacz Przewodnik po relacjach między tabelami i Ograniczanie wprowadzania danych przy użyciu reguł walidacji.
W programie SQL Server używasz ograniczeń typu UNIQUE i CHECK, czyli obiektów bazy danych, które wymuszają integralność danych w tabelach programu SQL Server. W celu walidacji, czy wartość jest prawidłowa w innej tabeli, należy zastosować ograniczenie klucza obcego. W celu walidacji, czy wartość w kolumnie mieści się w określonym zakresie, należy zastosować ograniczenie sprawdzania. Te obiekty stanowią pierwszą linię obrony i są zaprojektowane do wydajnej pracy. Aby uzyskać więcej informacji, zobacz Ograniczenia Unique i ograniczenia Check.
Wyzwalacze
W programie Access nie są dostępne wyzwalacze bazy danych. W programie SQL Server możesz używać wyzwalaczy, aby wymuszać złożone reguły integralności danych i uruchamiać tę logikę biznesową na serwerze. Wyzwalacz bazy danych to procedura składowana uruchamiana w przypadku wystąpienia określonych akcji w bazie danych. Wyzwalacz to zdarzenie, takie jak dodanie lub usunięcie rekordu tabeli, które uruchamia się, a następnie wykonuje procedurę składowaną. Chociaż baza danych programu Access może zagwarantować więzy integralności podczas próby aktualizacji lub usunięcia danych przez użytkownika, program SQL Server ma zaawansowany zestaw wyzwalaczy. Na przykład możesz zaprogramować wyzwalacz w celu usunięcia rekordów zbiorczo, aby zapewnić integralność danych. Możesz nawet dodać wyzwalacze do tabel i widoków.
Aby uzyskać więcej informacji, zobacz Wyzwalacze — DML, Wyzwalacze — DDL i Projektowanie wyzwalacza w języku T-SQL.
Używanie kolumn obliczanych
W programie Access możesz utworzyć kolumnę obliczeniową, dodając ją do zapytania i tworząc wyrażenie, takie jak:
Extended Price: [Quantity] * [Unit Price]
W programie SQL Server odpowiadająca jej funkcja jest nazywana kolumną obliczaną, która jest wirtualną kolumną, która nie jest fizycznie przechowywana w tabeli, o ile kolumna nie jest oznaczona jako PERSISTED. Podobnie jak w przypadku kolumny obliczeniowej, kolumna obliczana używa danych z innych kolumn w wyrażeniu. Aby utworzyć kolumnę obliczaną, należy ją dodać do tabeli. Przykłady:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Aby uzyskać więcej informacji, zobacz Określanie kolumn obliczanych w tabeli.
Sygnatura czasowa danych
Czasami podczas tworzenia rekordu należy dodać pole tabeli w celu zarejestrowania sygnatury czasowej, aby można było dodać wpis danych do dziennika. W programie Access możesz po prostu utworzyć kolumnę daty z wartością domyślną =Now(). Aby zarejestrować datę lub godzinę w programie SQL Server, użyj typu danych datetime2 z wartością domyślną SYSDATETIME().
Uwaga Unikaj mylenia słowa kluczowego rowversion z dodawaniem słowa kluczowego timestamp do swoich danych. Słowo kluczowe timestamp jest synonimem dla słowa rowversion w programie SQL Server, ale należy stosować słowo kluczowe rowversion. W programie SQL Server słowo kluczowe rowversion to typ danych, który ujawnia automatycznie generowane, unikatowe liczby binarne w bazie danych, i jest powszechnie używane jako mechanizm oznaczania wersją wierszy tabeli. Jednak typ danych rowversion to po prostu zwiększana liczba i nie zachowuje on daty ani godziny oraz nie jest przeznaczony do oznaczania wiersza sygnaturą czasową.
Aby uzyskać więcej informacji, zobacz rowversion. Aby uzyskać więcej informacji na temat używania typu danych rowversion do zminimalizowania konfliktów rekordów, zobacz Migrowanie bazy danych programu Access do programu SQL Server.
Zarządzanie dużymi obiektami
W programie Access możesz zarządzać danymi bez struktury, takimi jak pliki, zdjęcia i obrazy, przy użyciu typu danych Załącznik. W terminologii programu SQL Server dane bez struktury są określane mianem obiektu BLOB (duży obiekt binarny) i istnieje kilka sposobów pracy z nimi:
FILESTREAM Program używa typu danych varbinary(max) do przechowywania danych bez struktury w systemie plików, a nie w bazie danych. Aby uzyskać więcej informacji, zobacz Uzyskiwanie dostępu do danych typu FILESTREAM w języku Transact-SQL.
FileTable Przechowuje obiekty blob w specjalnych tabelach nazywanych FileTable i zapewnia zgodność z aplikacjami systemu Windows tak, jakby były przechowywane w systemie plików, i bez wprowadzania jakichkolwiek zmian w aplikacjach klienckich. Tabela FileTable wymaga użycia typu FILESTREAM. Aby uzyskać więcej informacji, zobacz FileTables.
Zdalny magazyn obiektów BLOB (RBS) Przechowuje obiekty BLOB w rozwiązaniach magazynu zamiast bezpośrednio na serwerze. Powoduje to oszczędność miejsca i zmniejsza zasoby sprzętowe. Aby uzyskać więcej informacji, zobacz Dane obiektu BLOB.
Praca z danymi hierarchicznymi
Chociaż relacyjne bazy danych, takie jak Access, są bardzo elastyczne, praca z relacjami hierarchicznymi jest wyjątkiem i często wymaga złożonych instrukcji SQL lub kodu. Do przykładów danych hierarchicznych należą: struktura organizacyjna, system plików, taksonomia pojęć językowych i wykres połączeń między stronami internetowymi. Program SQL Server ma wbudowany typ danych hierarchyid i zestaw funkcji hierarchicznych, które ułatwiają zapisywanie danych hierarchicznych i zarządzanie nimi oraz wykonywanie zapytań.
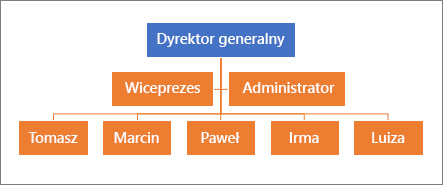
Aby uzyskać więcej informacji, zobacz Dane hierarchiczne i Samouczek: Używanie typu danych hierarchyid.
Manipulowanie tekstem w formacie JSON
Notacja JSON to usługa internetowa, która używa tekstu czytelnego dla człowieka do przesyłania danych w postaci par atrybut-wartość w asynchronicznej komunikacji przeglądarka-serwer. Przykłady:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Program Access nie ma żadnych wbudowanych sposobów zarządzania danymi JSON, ale w programie SQL Server można płynnie przechowywać, indeksować, wysyłać zapytania i wyodrębniać dane JSON. Możesz przekonwertować tekst JSON i przechować go w tabeli lub sformatować dane jako tekst JSON. Na przykład możesz chcieć sformatować wyniki zapytania jako JSON dla aplikacji internetowej lub dodać struktury danych JSON do wierszy i kolumn.
Uwaga Kod JSON nie jest obsługiwany w języku VBA. Alternatywnym rozwiązaniem jest skorzystanie z języka XML w języku VBA przy użyciu biblioteki MSXML.
Aby uzyskać więcej informacji, zobacz Dane notacji JSON w programie SQL Server.
Zasoby
Teraz jest najwyższy czas, aby dowiedzieć się więcej na temat programu SQL Server i języka Transact SQL (TSQL). Pokazaliśmy, że istnieje wiele funkcji, takich jak w programie Access, ale że istnieją także funkcje, których program Access po prostu nie ma. Aby przenieść naszą wycieczkę na następny poziom, oto kilka zasobów szkoleniowych:
|
Zasób |
Opis |
|
Kurs oparty na klipie wideo |
|
|
Samouczki dotyczące programu SQL Server 2017 |
|
|
Praktyczna nauka dla platformy Azure |
|
|
Zostań ekspertem |
|
|
Główna strona docelowa |
|
|
Informacje pomocy |
|
|
Informacje pomocy |
|
|
Omówienie chmury |
|
|
Wizualne podsumowanie nowych funkcji |
|
|
Podsumowanie funkcji wg wersji |
|
|
Pobierz program SQL Server Express 2017 |
|
|
Pobierz przykładowe bazy danych |









