
In Excel 2013 of hoger kunt u gegevensmodellen met miljoenen rijen maken en vervolgens krachtige gegevensanalyses uitvoeren ten opzichte van deze modellen. Gegevensmodellen kunnen met of zonder de Power Pivot-invoegtoepassing worden gemaakt om elk gewenst aantal draaitabellen, grafieken en Power View-visualisaties in dezelfde werkmap te ondersteunen.
Opmerking: In dit artikel worden gegevensmodellen in Excel 2013 beschreven. Dezelfde functies voor gegevensmodelleren en Power Pivot die in 2013 zijn geïntroduceerd Excel 2013, zijn echter ook van toepassing op Excel 2016. Er is weinig verschil tussen deze versies van Excel.
Hoewel u eenvoudig enorme gegevensmodellen kunt bouwen in Excel, zijn er enkele reden waarom u dit niet moet doen. Ten eerste zijn grote modellen met veel tabellen en kolommen een overkill voor de meeste analysen, waardoor een omslachtige lijst met velden wordt verkregen. Ten tweede verbruiken grote modellen kostbaar geheugen, wat een negatief effect heeft op andere toepassingen en rapporten waarin dezelfde systeembronnen worden gedeeld. Ten slotte Microsoft 365 zowel SharePoint Online als Excel Web App de grootte van een Excel tot 10 MB. Bij werkmapgegevensmodellen met miljoenen rijen zit u vrij snel aan de limiet van 10 MB. Zie Specificatie en limieten van gegevensmodellen.
In dit artikel leert u hoe u een krachtig model bouwt dat eenvoudiger in gebruik is en minder geheugen verbruikt. Als u de tijd neemt voor het leren van best practices in een efficiënt modelontwerp, betaalt u de weg af voor elk model dat u maakt en gebruikt, of u het nu bekijkt in Excel 2013, Microsoft 365 SharePoint Online, op een Office Web Apps-server of in SharePoint 2013.
Overweeg ook om de Workbook Size Optimizer uit te voeren. Hiermee kunt u uw Excel-werkmappen analyseren en comprimeren, als dat mogelijk is. Download de werkmapgrootte optimizer.
In dit artikel
Compressieratio’s en de analyse-engine in het geheugen
Voor gegevensmodellen in Excel wordt de analyse-engine in het geheugen gebruikt om gegevens in het geheugen op te slaan. Met de engine worden krachtige compressietechnieken geïmplementeerd om opslagvereisten te verminderen, waardoor een resultatenset wordt verkleind tot een fractie van de oorspronkelijke grootte.
Gemiddeld kunt u verwachten dat een gegevensmodel zeven tot tien keer zo klein is als dezelfde gegevens op het punt van herkomst. Als u bijvoorbeeld 7 MB aan gegevens importeert uit een SQL Server-database, kan het gegevensmodel in Excel gemakkelijk 1 MB of kleiner zijn. De werkelijk gerealiseerde mate van compressie hangt hoofdzakelijk af van het aantal unieke waarden in elke kolom. Hoe meer unieke waarden er zijn, des te meer geheugen nodig is om deze op te slaan.
Waarom hebben we het over compressie en unieke waarden? Omdat het maken van een efficiënt model dat het geheugengebruik minimaliseert, alles te maken heeft met compressiemaximalisatie en de eenvoudigste manier om dat te doen, is door kolommen te verwijderen die u niet echt nodig hebt, vooral als deze kolommen een groot aantal unieke waarden bevatten.
Opmerking: De verschillen in opslagvereisten voor individuele kolommen kunnen enorm zijn. In sommige gevallen is het beter om meerdere kolommen met weinig unieke waarden te hebben dan één kolom met veel unieke waarden. In de sectie over optimalisaties voor datum/tijd wordt gedetailleerd ingegaan op deze techniek.
Niets verbruikt minder geheugen dan een niet-bestaande kolom
De meest geheugenefficiënte kolom is de kolom die u nooit hebt geïmporteerd. Als u een efficiënt model wilt maken, bekijkt u elke kolom en vraagt u zich af of het bijdraagt aan de analyse die u wilt uitvoeren. Als dat niet zo is of als u het niet zeker weet, laat het dan weg. U kunt later altijd nieuwe kolommen toevoegen als u ze nodig hebt.
Twee voorbeelden van kolommen die u beter altijd kunt uitsluiten
Het eerste voorbeeld houdt verband met gegevens die afkomstig zijn uit een datawarehouse. In een datawarehouse komen vaak artefacten van ETL-processen voor waarmee gegevens in de warehouse worden geladen en vernieuwd. Kolommen zoals 'datum maken', 'datum bijwerken' en 'ETL-uitvoering' worden gemaakt wanneer de gegevens worden geladen. Geen van deze kolommen is nodig in het model en kan het beste worden uitgeschakeld wanneer u gegevens importeert.
Het tweede voorbeeld heeft betrekking op het weglaten van de primaire-sleutelkolom wanneer u een feitentabel importeert.
Veel tabellen, waaronder feitentabellen, bevatten primaire sleutels. Voor de meeste tabellen, zoals tabellen met klant-, personeels- of verkoopgegevens, zult u relaties in het model willen maken met behulp van de primaire sleutel van de tabel.
Feitentabellen zijn anders. In een feitentabel wordt de primaire sleutel gebruikt om elke rij uniek aan te duiden. Hoewel een dergelijke tabel nodig is voor normalisatiedoeleinden, is deze minder nuttig in een gegevensmodel waarin u alleen kolommen wilt die worden gebruikt om analysen uit te voeren of tabelrelaties tot stand te brengen. Neem daarom niet de primaire sleutel op wanneer u gegevens importeert uit een feitentabel. Primaire sleutels in een feitentabel verbruiken enorm veel ruimte in het model terwijl ze geen voordeel bieden, want ze kunnen niet worden gebruikt om relaties te maken.
Opmerking: In gegevensmagazijnen en multidimensionale databases worden grote tabellen die bestaan uit voornamelijk numerieke gegevens vaak 'feitentabellen' genoemd. Feitentabellen bevatten meestal bedrijfsprestaties of transactiegegevens, zoals verkoop- en kostengegevenspunten die zijn samengevoegd en uitgelijnd op organisatie-eenheden, producten, marktsegmenten, geografische regio's, en dergelijke. Alle kolommen in een feitentabel die zakelijke gegevens bevatten of die kunnen worden gebruikt om gegevens te kruisen die zijn opgeslagen in andere tabellen, moeten in het model worden opgenomen ter ondersteuning van gegevensanalyse. De kolom die u wilt uitsluiten, is de primaire sleutelkolom van de feitentabel, die bestaat uit unieke waarden die alleen aanwezig zijn in de feitentabel en nergens anders. Omdat feitentabellen zo groot zijn, zijn enkele van de grootste voordelen in de efficiëntie van het model afgeleid van het uitsluiten van rijen of kolommen uit feitentabellen.
Onnodige kolommen uitsluiten
Efficiënte modellen bevatten alleen kolommen die u werkelijk nodig hebt in uw werkmap. Als u wilt regelen welke kolommen worden opgenomen in het model, moet u de gegevens importeren met de wizard Tabel importeren in de Power Pivot-invoegtoepassing in plaats van het dialoogvenster Gegevens importeren in Excel.
Wanneer u de wizard Tabel importeren start, selecteert u welke tabellen u wilt importeren.
Voor elke tabel kunt u op de knop Voorbeeld en filteren klikken en de delen van de tabel selecteren die u echt nodig hebt. U kunt het beste eerst alle kolommen uitschakelen en daarna de gewenste kolommen controleren nadat u hebt overwogen of ze nodig zijn voor de analyse.
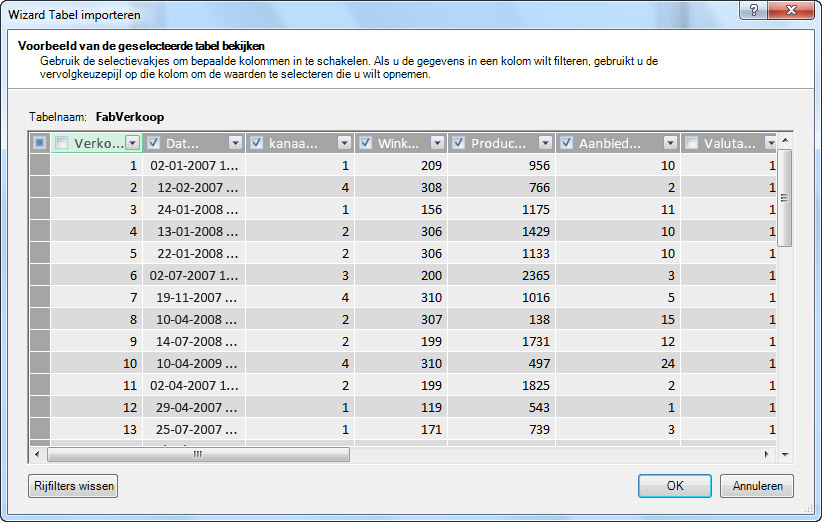
En wat als alleen de benodigde rijen worden gefilterd?
Veel tabellen in bedrijfsdatabases en datawarehouses bevatten historische gegevens die gedurende lange tijd zijn opgebouwd. Bovendien kunnen de tabellen waarin u geïnteresseerd bent, gegevens bevatten voor gebieden van het bedrijf die niet nodig zijn voor uw specifieke analyse.
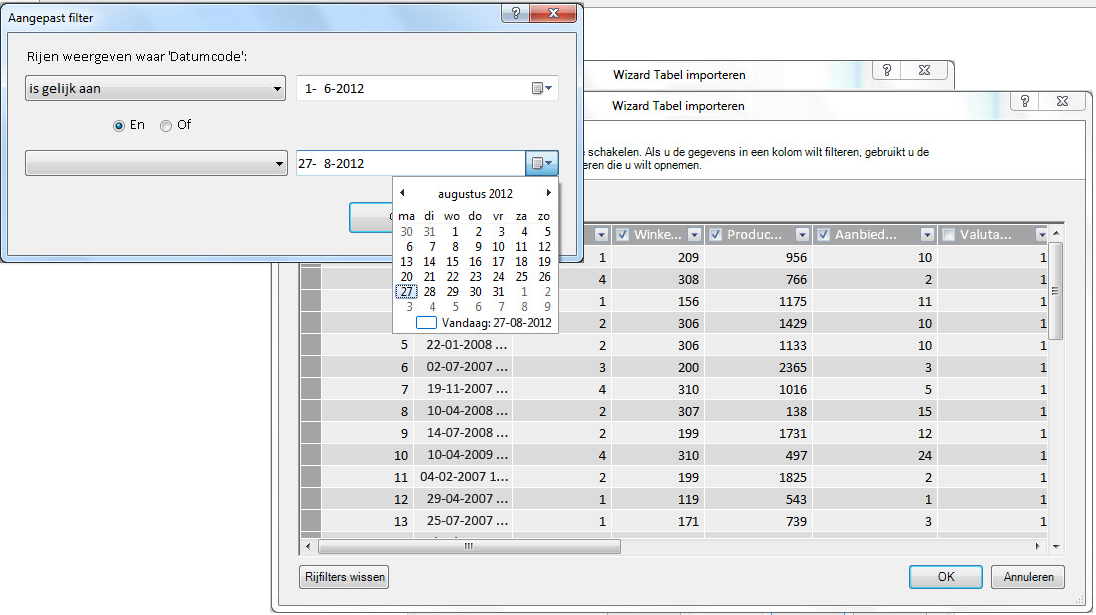
Met de tabel Wizard importeren kunt u historische of ongerelateerde gegevens eruitfilteren en zo veel ruimte in het model besparen. In de volgende afbeelding wordt een datumfilter gebruikt om alleen rijen met gegevens voor het huidige jaar op te halen, behalve historische gegevens die u niet nodig hebt.
Wat als we de kolom nodig hebben? Kunnen we dan toch nog de benodigde ruimte beperken?
U kunt enkele aanvullende technieken toepassen zodat een kolom beter kan worden gecomprimeerd. Onthoud dat het aantal unieke waarden de enige eigenschap is die van invloed is op compressie. In deze sectie leert u hoe sommige kolommen kunnen worden gewijzigd om het aantal unieke waarden te verminderen.
Datum-/tijdkolommen wijzigen
In veel gevallen kunnen datum-/tijdkolommen veel ruimte innemen. U kunt de opslagvereisten voor dit gegevenstype op een aantal manieren verminderen. De technieken variëren afhankelijk van hoe u de kolom gebruikt en hoe ervaren u bent met het bouwen van SQL-query's.
Datum-/tijdkolommen bevatten een datumgedeelte en een tijd. Stel uzelf meerdere keren dezelfde vraag voor een datum-/tijdkolom als u zich afvraagt of u deze nodig hebt:
-
Heb ik het tijdgedeelte nodig?
-
Heb ik het tijdgedeelte nodig op het niveau van uren? Minuten? Seconden? Milliseconden?
-
Heb ik meerdere datum-/tijdkolommen omdat ik het verschil hiertussen wil berekenen of omdat ik de gegevens per jaar, maand, kwartaal en dergelijke wil optellen? Enzovoort.
Uw antwoord op elk van deze vragen is bepalend voor de opties waarmee u de datum-/tijdkolom kunt beheren.
Voor al deze oplossingen moet een SQL worden gewijzigd. Als u de wijziging van query's eenvoudiger wilt maken, moet u ten minste één kolom in elke tabel filteren. Door een kolom te filteren, wijzigt u de queryconstructie van een afgekorte indeling (SELECT *) in een SELECT-instructie die volledig gekwalificeerde kolomnamen bevat, die veel gemakkelijker te wijzigen zijn.
Laten we eens kijken naar de query's die voor u worden gemaakt. In het dialoogvenster Tabeleigenschappen kunt u overschakelen naar de queryeditor en de huidige SQL-query voor elke tabel bekijken.

Selecteer in Tabeleigenschappen de optie Queryeditor.
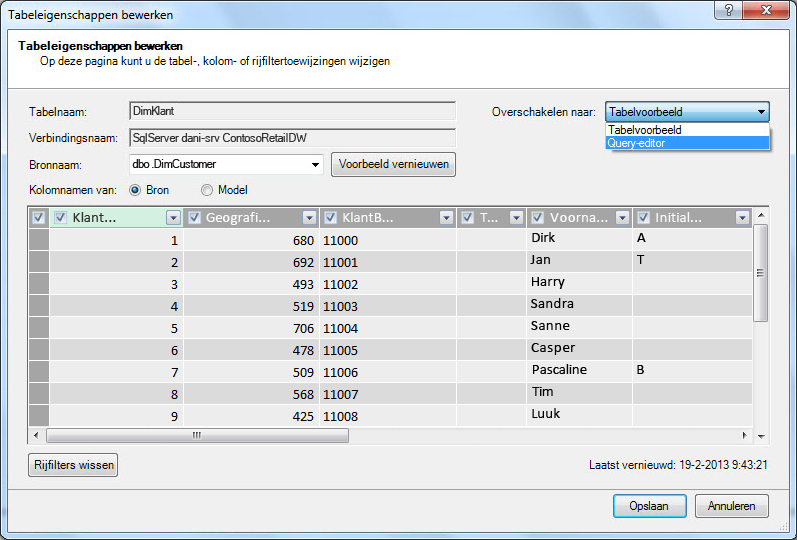
In de queryeditor wordt de SQL-query weergegeven waarmee de tabel wordt ingevoerd. Als u een kolom tijdens de import eruit hebt gefilterd, omvat uw query volledig gekwalificeerde kolomnamen:
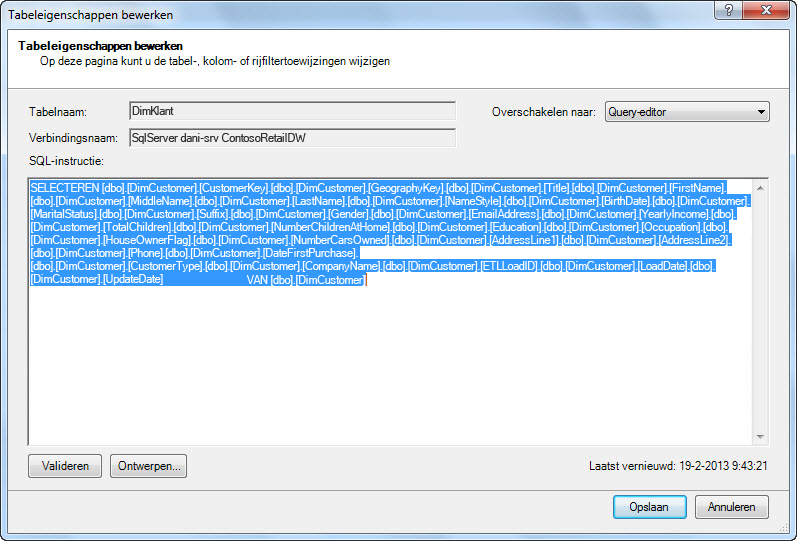
|
Als u daarentegen een tabel volledig hebt geïmporteerd zonder een kolom uit te schakelen of een filter toe te passen, ziet u de query als '* selecteren vanaf'. Deze is lastiger te wijzigen:
|
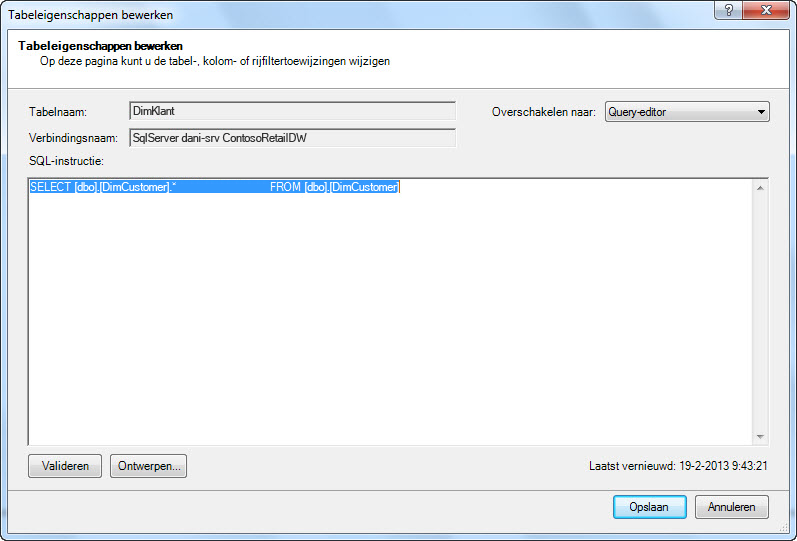
De SQL-query wijzigen
Nu u weet hoe u de query kunt zoeken, kunt u deze verder wijzigen om de grootte van uw model verder te beperken.
-
Gebruik de volgende syntaxis om de decimalen te verwijderen als u deze niet nodig hebt in kolommen met valuta- of decimaalgegevens:
"SELECT ROUND([kolomnaam_met_decimalen],0)… .”
Vervang de 0 door 2 als u de centen nodig hebt, maar geen fracties van centen. Als u negatieve getallen gebruikt, kunt u afronden op eenheden, tientallen, honderdtallen, enzovoort.
-
Gebruik de volgende syntaxis om de tijd te verwijderen als u een datum-/tijdkolom met de naam dbo.grotetabel.[Datum Tijd] hebt en het tijdgedeelte niet nodig hebt:
“SELECT CAST (dbo.grotetabel.[Datum Tijd] as date) AS [Datum Tijd]) “
-
Gebruik meerdere kolommen in de SQL-query in plaats van één datum-/tijdkolom als u een datum-/tijdkolom met de naam dbo.grotetabel.[Datum tijd] hebt en zowel het datum- als het tijdgedeelte nodig hebt:
“SELECT CAST (dbo.grotetabel.[Datum Tijd] as date) AS [Datum Tijd],
datepart(hh, dbo.grotetabel.[Datum Tijd]) as [Datum Tijd Uren],
datepart(mi, dbo.grotetabel.[Datum Tijd]) as [Datum Tijd Minuten],
datepart(ss, dbo.grotetabel.[Datum Tijd]) as [Datum Tijd Seconden],
datepart(ms, dbo.grotetabel.[Datum Tijd]) as [Datum Tijd Milliseconden]"
Gebruik zoveel kolommen als nodig om elk deel in een aparte kolom op te slaan.
-
Als u uren en minuten nodig hebt en deze liever samenvoegt in één tijdkolom, kunt u de volgende syntaxis gebruiken:
Timefromparts(datepart(hh, dbo.grotetabel.[Datum Tijd]), datepart(mm, dbo.grotetabel.[Datum Tijd])) as [Datum Tijd Uren Minuut]
-
Als u twee datum-/tijdkolommen hebt, zoals [Begintijd] en [Eindtijd], en u alleen het tijdverschil hiertussen in seconden nodig hebt als kolom met de naam [Duur], verwijdert u beide uit de lijst en voegt u het volgende toe:
"datediff(ss,[Begindatum],[Einddatum]) as [Duur]"
Als u het trefwoord ms in plaats van ss gebruikt, verkrijgt u de duur in milliseconden.
Met DAX berekende maateenheden in plaats van kolommen
Als u eerder hebt gewerkt met een taal voor DAX-expressies, weet u mogelijk al dat berekende kolommen worden gebruikt om nieuwe kolommen af te leiden van een andere kolom in het model, maar alleen worden geëvalueerd wanneer ze in een draaitabel of ander rapport worden gebruikt.
U kunt onder andere geheugen besparen door normale of berekende kolommen te vervangen door berekende maateenheden. Het klassieke voorbeeld is Eenheidsprijs, Hoeveelheid en Totaal. Als u alle drie hebt, kunt u ruimte besparen door er slechts twee te handhaven en de derde te berekenen met DAX.
Welke twee kolommen kunt u het beste behouden?
Behoud in het bovenstaande voorbeeld Hoeveelheid en Eenheidsprijs. Deze twee bevatten minder waarden dan Totaal. Als u Totaal wilt berekenen, voegt u een berekende maateenheid toe zoals:
“TotaleVerkoop:=sumx('Verkooptabel','Verkooptabel'[Eenheidsprijs]*'Verkooptabel'[Hoeveelheid])”
Berekende kolommen nemen net zoals normale kolommen ruimte in het model in beslag. Berekende maateenheden worden echter berekend zodra ze zich voordoen en nemen geen ruimte in beslag.
Conclusie
In dit artikel hebben we verschillende benaderingen besproken waarmee u een geheugenefficiënter model kunt opbouwen. Als u de bestandsgrootte en geheugenvereisten van een gegevensmodel wilt beperken, vermindert u het totale aantal kolommen en rijen, en het aantal unieke waarden dat in elke kolom wordt weergegeven. Onder andere de volgende technieken zijn aan de orde gekomen:
-
Natuurlijk kunt u het beste ruimte besparen door kolommen te verwijderen. Bepaal welke kolommen u echt nodig hebt.
-
Soms kunt u een kolom verwijderen en vervangen door een berekende maateenheid in de tabel.
-
Mogelijk hebt u niet alle rijen in een tabel nodig. U kunt rijen eruitfilteren in de wizard Tabel importeren.
-
In het algemeen is het een goed idee om één kolom te verdelen in meerdere aparte delen als u het aantal unieke waarden in een kolom wilt verminderen. Elk deel bevat een klein aantal unieke waarden, en het gecombineerde totaal is kleiner dan de originele samengevoegde kolom.
-
In veel gevallen hebt u ook de verschillende delen nodig als slicer in uw rapporten. Zo nodig kunt u hiërarchieën maken van delen als Uren, Minuten en Seconden.
-
Vaak bevatten kolommen meer gegevens dan nodig. Stel dat in een kolom decimalen worden op slaat, maar u hebt opmaak toegepast om alle decimalen te verbergen. Afronding kan dan erg effectief zijn om een numerieke kolom te verkleinen.
Nu u al het mogelijke hebt gedaan om de grootte van uw werkmap te beperken, kunt u ook overwegen de Workbook Size Optimizer uit te voeren. Hiermee kunt u uw Excel-werkmappen analyseren en comprimeren, als dat mogelijk is. Download de werkmapgrootte optimizer.
Verwante koppelingen
Specificaties en beperkingen van gegevensmodellen
Power Pivot: krachtige gegevensanalyse en gegevensmodellen in Excel









