
Nadat u uw gegevens hebt gemigreerd van Access naar SQL Server, beschikt u over een client/server-database. Dit kan een on-premises of een hybride Azure-cloudoplossing zijn. In beide gevallen is Access de presentatielaag en SQL Server de gegevenslaag. Dit is een goed moment om aspecten van uw oplossing opnieuw te bekijken, met name queryprestaties, beveiliging en bedrijfscontinuïteit, zodat u uw databaseoplossing kunt verbeteren en schalen.
De documentatie voor SQL Server en Azure kan intimiderend zijn voor een Access-gebruiker die dit voor het eerst ziet. Dit vraagt om een gids die u door de belangrijkste hoogtepunten loodst. Nadat u deze excursie hebt voltooid, bent u klaar om de ontwikkelingen in de databasetechnologie dieper te verkennen.
In dit artikel
|
Databasebeheer Omgaan met privacy-aandachtspunten |
Query’s etc. Prestaties van query's verbeteren |
Gegevenstypen |
Diverse |
Bedrijfscontinuïteit stimuleren
U wilt uw Access-oplossing met minimale onderbreking operationeel houden, maar de opties met een back-end-database van Access zijn beperkt. Het maken van een back-up van uw Access-database is essentieel voor het beschermen van uw gegevens, maar daarvoor moeten uw gebruikers offline zijn. Dan is er ongeplande downtime die wordt veroorzaakt door onderhoudsupgrades van hardware en software, netwerk- of stroomuitval, hardwarestoringen, beveiligingsinbreuken of zelfs cyberaanvallen. Om de downtime en overlast voor uw bedrijf tot een minimum te beperken, kunt u een reservekopie maken van een SQL Server-database terwijl deze wordt gebruikt. Daarnaast biedt SQL Server strategieën voor hoge beschikbaarheid (HA) en herstel na noodgevallen (DR). Deze twee gecombineerde technologieën worden HADR genoemd. Zie Bedrijfscontinuïteit en herstel van databases en Stimuleer bedrijfscontinuïteit met SQL Server (e-book) voor meer informatie.
Een back-up maken tijdens gebruik
SQL Server gebruikt een onlineback-upproces dat kan worden uitgevoerd terwijl de database operationeel is. U kunt een volledige back-up of een gedeeltelijke back-up maken of een back-up van een bestand. Een back-up kopieert gegevens en transactielogboeken om een volledige herstelbewerking te garanderen. Met name in een on-premises oplossing moet u rekening houden met de verschillen tussen de opties voor eenvoudig en volledig herstel en de invloed hiervan op de groei van het transactielogboek. Zie Herstelmodellen voor meer informatie.
De meeste bewerkingen voor back-ups worden meteen uitgevoerd, met uitzondering van bestandsbeheer en database-verkleinende bewerkingen. Als u een databasebestand probeert te maken of verwijderen terwijl een back-upbewerking wordt uitgevoerd, mislukt de bewerking. Zie Overzicht van backups voor meer informatie.
HADR
De twee meest gebruikte technieken voor het bereiken van hoge beschikbaarheid en bedrijfscontinuïteit zijn spiegelen en clusteren. SQL Server integreert mirroring- en clustering-technologie met "Always On Failover Cluster-instanties" en "Always On Availability Groups".
Mirroring is een continuïteitsoplossing op databaseniveau die vrijwel onmiddellijke failover ondersteunt door een standby-database, een volledige kopie, of een mirror van de actieve database op afzonderlijke hardware te onderhouden. Het kan in een synchrone (hoge veiligheid) modus worden uitgevoerd, waarbij een binnenkomende transactie op hetzelfde moment wordt doorgevoerd aan alle servers, of in een asynchrone (hoge prestatie) modus, waarbij een binnenkomende transactie wordt doorgevoerd in de actieve database en vervolgens op een vooraf bepaald punt naar de mirror wordt gekopieerd. Mirroring is een oplossing op databaseniveau en werkt alleen met databases die het model voor volledig herstel gebruiken.
Clustering is een oplossing op serverniveau waarbij servers worden gecombineerd tot één gegevensopslagunit die er voor de gebruiker uitziet als een eenheid. Gebruikers maken verbinding met de instantie en hoeven nooit te weten welke server in de instantie momenteel actief is. Als er één server defect raakt of offline moet worden genomen voor onderhoud, verandert de gebruikerservaring niet. Elke server in het cluster wordt op basis van een heartbeat gecontroleerd door clusterbeheer. Deze detecteert wanneer de actieve server in de cluster offline raakt en probeert naadloos over te schakelen naar de volgende server in de cluster. Er is een variabele tijdsvertraging tijdens het overschakelen.
Zie Always On Failover Cluster Instances en Always On availability-groepen: een oplossing met hoge beschikbaarheid en een oplossing voor herstel bij calamiteiten voor meer informatie.
SQL Server-beveiliging
Hoewel u uw Access-database kunt beschermen met behulp van het vertrouwenscentrum en de database kunt versleutelen, beschikt SQL Server over geavanceerdere beveiligingsfuncties. Laten we eens kijken naar drie mogelijkheden die opvallen voor de Access-gebruiker. Zie SQL Server beveiligen voor meer informatie.
Databaseverificatie
Er zijn vier methoden voor database-authenticatie in SQL Server, die u elk in een ODBC-verbindingsreeks kunt opgeven. Zie Gegevens koppelen of importeren vanuit een Azure SQL Server-database voor meer informatie. Elke methode heeft zijn voordelen.
Geïntegreerde Windows-verificatie Gebruik Windows-referenties voor gebruikersvalidatie, beveiligingsrollen en het beperken van gebruikers tot functies en gegevens. U kunt domeinreferenties gebruiken en eenvoudig gebruikersrechten beheren in uw toepassing. U kunt desgewenst een SPN (Service Principle Name) invoeren. Zie Kies een verificatiemodus voor meer informatie.
SQL Server-verificatie Gebruikers moeten verbinding maken met referenties die in de database zijn ingesteld door de aanmeldings-ID en het wachtwoord in te voeren, de eerste keer dat ze de database in een sessie openen. Zie Kies een verificatiemodus voor meer informatie.
Geïntegreerde Azure Active Directory-verificatie Maak verbinding met de Azure Active Directory-database door middel van Azure Active Directory. Als u Azure Active Directory-verificatie hebt geconfigureerd, hoeft u geen extra aanmeldings-id en wachtwoord in te voeren. Zie Connecting to SQL Database by Using Azure Active Directory Authentication (Verbinding maken met SQL Database door middel van Azure Active Directory-verificatie) voor meer informatie.
Active Directory-wachtwoordverificatie Maak verbinding door middel van referenties die zijn ingesteld in Azure Active Directory door de aanmeldingsnaam en het wachtwoord in te voeren. Zie Connecting to SQL Database by Using Azure Active Directory Authentication (Verbinding maken met SQL Database door middel van Azure Active Directory-verificatie) voor meer informatie.
Tip Gebruik bedreigingsdetectie om waarschuwingen te ontvangen over onregelmatige database-activiteiten met mogelijke beveiligingsrisico's voor een Azure SQL Server-database. Zie SQL Database bedreigingsdetectie voor meer informatie.
Toepassingsbeveiliging
SQL Server bevat twee beveiligingsfuncties op toepassingsniveau die u kunt gebruiken in Access.
Dynamische Gegevensmaskering U kunt gevoelige informatie verbergen door deze te maskeren voor niet-geautoriseerde gebruikers. U kunt bijvoorbeeld sofi-nummers gedeeltelijk of volledig maskeren.
 Een gedeeltelijk gegevensmasker |
 Een volledig gegevensmasker |
Er zijn verschillende manieren waarop u een gegevensmasker kunt definiëren en deze op verschillende gegevenstypen kunt toepassen. Gegevensmaskering is gebaseerd op het beleid op tabel-en kolomniveau voor een gedefinieerde groep gebruikers en wordt toegepast in realtime-query's. Zie Dynamische gegevensmaskering voor meer informatie.
Beveiliging op rijniveau U kunt de toegang tot specifieke databaserijen met gevoelige informatie op basis van gebruikerskenmerken beheren door middel van beveiliging op rijniveau. Het databasesysteem past deze toegangsbeperkingen toe en dit maakt het beveiligingssysteem betrouwbaarder en robuuster.

Er zijn twee soorten beveiligingspredikaten:
-
Met een filterpredikaat worden rijen uit een query gefilterd. Het filter is transparant en de gebruiker merkt niets van het filter.
-
Een Block-predikaat voorkomt dat een ongeautoriseerde actie wordt uitgevoerd en genereert een uitzondering als de actie niet kan worden uitgevoerd.
Zie Beveiliging op rijniveau voor meer informatie.
Gegevens beveiligen met versleuteling
Bescherm gegevens in rust, tijdens de overdracht en tijdens gebruik, zonder dat de databaseprestaties worden beïnvloed. Zie SQL Server-versleuteling voor meer informatie.
Versleuteling in rust Gebruik versleuteling-in-rust, ook wel TDE (Transparent Data Encryption) genoemd, om persoonlijke gegevens te beveiligen tegen aanvallen van offline media op de fysieke opslaglaag. Dit betekent dat uw gegevens beschermd zijn, zelfs als de fysieke media worden gestolen of ten onrechte worden verwijderd. TDE voert de verwerking van databases, back-ups en het maken van transacties in realtime uit, zonder dat u de toepassingen hoeft te wijzigen.
Versleuteling in transit Om u te beschermen tegen "snuffelen" en "man-in-the-middle-aanvallen", kunt u gegevens versleutelen die over het netwerk worden verzonden. SQL Server ondersteunt TLS (Transport Layer Security) 1.2 voor zwaarbeveiligde communicatie. Het TDS-protocol (Tabular Data Stream) wordt ook gebruikt om communicatie via niet-vertrouwde netwerken te beveiligen.
Versleuteling in gebruik op de client Als u persoonlijke gegevens wilt beschermen terwijl ze worden gebruikt, is “Altijd Gecodeerd” de gewenste functie. Persoonlijke gegevens worden versleuteld en gedecodeerd met een stuurprogramma op de clientcomputer, zonder dat er versleutelingssleutels aan de database-engine worden getoond. Dientengevolge zijn gecodeerde gegevens alleen zichtbaar voor de personen die verantwoordelijk zijn voor het beheer van die gegevens, en niet voor andere zeer bevoorrechte gebruikers die geen toegang zouden moeten hebben. Afhankelijk van het geselecteerde type codering, kan Altijd Gecodeerd bepaalde databasefuncties beperken, zoals zoeken, groeperen en indexeren van versleutelde kolommen.
Omgaan met privacy-aandachtspunten
Privacykwesties zijn zo wijdverspreid dat de Europese Unie juridische vereisten heeft gedefinieerd via de Algemene Verordening Gegevensbescherming (AVG). Gelukkig is een SQL Server-back-end prima geschikt om aan deze vereisten te voldoen. Denk na over het implementeren van de AVG in een driestappenkader.

Stap 1: Nalevingsrisico evalueren en beheren
De AVG vereist dat u persoonlijke informatie die in tabellen en bestanden is opgeslagen, identificeert en inventariseert. Deze informatie kan bestaan uit een naam, een foto, een e-mailadres, bankgegevens, berichten op sociale netwerken, medische gegevens of zelfs een IP-adres.
Een nieuwe tool, SQL Data Discovery en Classification, ingebouwd in SQL Server Management Studio, helpt u gevoelige gegevens te ontdekken, classificeren, labelen en rapporteren door twee metadata-kenmerken toe te passen op kolommen:
-
Labels Voor het definiëren van de gegevensgevoeligheid.
-
Gegevenstypen Als u extra granulariteit wilt voor de typen gegevens die zijn opgeslagen in een kolom.
Een ander detectiemechanisme dat u kunt gebruiken, is zoeken in volledige tekst, inclusief het gebruik van CONTAINS en FREETEXT-predicaten en functies op rijniveau, zoals CONTAINSTABLE en FREETEXTTABLE voor gebruik met de SELECT-instructie. Met behulp van zoeken in volledige tekst kunt u tabellen doorzoeken om woorden, woordcombinaties of variaties op een woord te ontdekken, zoals synoniemen of inflectional-formulieren. Zie Zoeken in volledige tekst voor meer informatie.
Stap 2: Persoonlijke gegevens beveiligen
De AVG vereist dat u persoonlijke informatie beveiligt en de toegang ertoe beperkt. Naast de standaardstappen die u moet uitvoeren om de toegang tot uw netwerk en bronnen, zoals firewall-instellingen, te beheren, kunt u gebruikmaken van de beveiligingsfuncties van SQL Server om de toegang tot gegevens te beheren:
-
SQL Server-verificatie voor het beheren van gebruikersidentiteit en het voorkomen van niet-geautoriseerde toegang.
-
Beveiliging op rijniveau om de toegang tot rijen in een tabel te beperken op basis van de relatie tussen de gebruiker en die gegevens.
-
Dynamische Gegevensmaskering om de blootstelling te beperken tot persoonlijke gegevens door deze te maskeren voor gebruikers zonder de juiste bevoegdheden.
-
Versleuteling om ervoor te zorgen dat persoonlijke gegevens worden beschermd tijdens verzending en opslag en worden beschermd tegen inbreuken, ook aan de serverkant.
Zie SQL Server-beveiligingvoor meer informatie.
Stap 3: Efficiënt reageren op verzoeken
De AVG schrijft voor dat u records van het verwerken van persoonlijke gegevens bijhoudt en deze records op verzoek beschikbaar stelt aan toezichthoudende autoriteiten. Als er zich problemen voordoen, waaronder het onbedoeld vrijgeven van gegevens, kunt u met beveiligingsbesturingselementen snel reageren. Gegevens moeten snel beschikbaar zijn wanneer rapportage nodig is. De AVG vereist bijvoorbeeld dat een inbreuk in de persoonlijke gegevens aan de toezichthoudende autoriteit wordt gemeld "niet later dan 72 uur nadat het bekend is geraakt".
SQL Server 2017 biedt u op verschillende manieren hulp bij het rapporteren van taken:
-
SQL Server Audit helpt u ervoor te zorgen dat persistente records van databasetoegang en verwerkingsactiviteiten bestaan. Het voert een fijnmazig onderzoek uit dat databaseactiviteiten bijhoudt, om potentiële bedreigingen, vermoedelijk misbruik of beveiligingsschendingen te herkennen en te identificeren. U kunt gegevensforensiek gemakkelijk uitvoeren.
-
Tijdelijke SQL Server-tabellen zijn systeemgebaseerde gebruikerstabellen die een volledige geschiedenis van de gegevenswijzigingen bijhouden. U kunt deze gebruiken voor eenvoudige rapportage en tijdstipanalyse.
-
SQL-Beveiligingslekken kunt u problemen met de beveiliging en machtigingen ontdekken. Als er een probleem wordt waargenomen, kunt u ook inzoomen op databasescanrapporten om te zoeken naar acties voor het oplossen van problemen.
Zie Een platform van vertrouwen opzetten (e-book) en Nakoming van de AVG voor meer informatie.
Momentopnamen van databases maken
Een momentopname van een database is een alleen-lezen, statische weergave van een SQL Server-database op een bepaald moment. Hoewel u een Access-databasebestand kunt kopiëren om een momentopname van een database te maken, heeft Access geen ingebouwde methodologie zoals SQL Server. U kunt een momentopname van een database gebruiken om rapporten te schrijven op basis van de gegevens op het moment dat de momentopname van de database wordt gemaakt. U kunt ook een momentopname van de database gebruiken om historische gegevens bij te houden, bijvoorbeeld een momentopname voor elk financieel kwartaal dat u gebruikt om rapportages aan het einde van de periode op te halen. De volgende werkwijze wordt aanbevolen:
-
Geef de momentopname een naam Voor elke databasemomentopname is een unieke databasenaam vereist. Voeg het doel en de tijdsduur toe aan de naam zodat u deze eenvoudiger kunt herkennen. Als u bijvoorbeeld een momentopname wilt maken van de AdventureWorks-database, drie keer per dag, tussen 6:00 uur en 18:00 uur, met een tijdsinterval van zes uur, op basis van een 24-uurs klok, kunt u deze AdventureWorks_snapshot_0600, AdventureWorks_snapshot_1200 en AdventureWorks_snapshot_1800 noemen.
-
Het aantal momentopnamen beperken De momentopname van een database blijft behouden tot deze expliciet wordt verwijderd. Omdat elke momentopname blijft groeien, wilt u misschien schijfruimte besparen door een oudere momentopname te verwijderen na het maken van een nieuwe momentopname. Als u bijvoorbeeld dagelijks rapporten wilt maken, kunt u de momentopname van de database 24 uur behouden en vervolgens verwijderen en vervangen door een nieuwe.
-
Verbinding maken met de juiste momentopname Als u een momentopname van een database wilt gebruiken, moet de front-end van Access de juiste locatie weten. Wanneer u een nieuwe momentopname vervangt voor een bestaande momentopname, moet u Access omleiden naar de nieuwe momentopname. Voeg logica toe aan de front-end van Access om er zeker van te zijn dat u verbinding maakt met de juiste momentopname van een database.
U kunt als volgt een momentopname maken van een database:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Zie Momentopnamen van databases (SQL Server) voor meer informatie.
Gelijktijdigheidsbeheer
Wanneer veel mensen tegelijkertijd proberen gegevens in een database te wijzigen, is een controlesysteem nodig zodat wijzigingen aangebracht door één persoon geen nadelige invloed hebben op die van een andere persoon. Dit wordt gelijktijdigheidsbeheer genoemd en er zijn twee basisstrategieën voor vergrendelen, pessimistisch en optimistisch. Vergrendeling kan voorkomen dat gebruikers gegevens wijzigen op een manier die andere gebruikers beïnvloedt. Door de vergrendeling wordt ook de integriteit van de database gegarandeerd. Dit werkt vooral met query's die anders onverwachte resultaten opleveren. Er zijn belangrijke verschillen in de manier waarop in Access en SQL Server deze gelijktijdigheidsbeheerstrategieën worden geïmplementeerd.
In Access is de standaard vergrendelingsstrategie optimistisch en wordt het eigendom van het slot verleend aan de eerste persoon die probeert een record te schrijven. Access geeft het dialoogvenster Schrijfconflict weer aan de andere persoon die probeert tegelijkertijd naar hetzelfde record te schrijven. Om het conflict op te lossen, kan de andere persoon de record opslaan, naar het Klembord kopiëren of de wijzigingen annuleren.
U kunt ook de eigenschap RecordLocks gebruiken om de gelijktijdigheidsbeheerstrategie te wijzigen. Deze eigenschap is van invloed op formulieren, rapporten en query's. Het kent drie instellingen:
-
Geen vergrendelingen In een formulier kunnen gebruikers proberen hetzelfde record tegelijkertijd te bewerken, maar het dialoogvenster Schrijfconflict kan worden weergegeven. Bij rapporten worden de records niet vergrendeld tijdens het afdrukken of het maken van een afdrukvoorbeeld van het rapport. Bij query's worden de records niet vergrendeld tijdens het uitvoeren van de query. Dit is de manier waarop Access optimistische vergrendeling implementeert.
-
Alle records Alle records in de onderliggende tabel of query worden vergrendeld zolang het formulier is geopend in Formulier- of Gegevensbladweergave, tijdens het afdrukken of het maken van een afdrukvoorbeeld van het rapport, of tijdens het uitvoeren van de query. Gebruikers kunnen de records tijdens de vergrendeling lezen.
-
Bewerkte records (Alleen formulieren en query's) Een pagina met records wordt vergrendeld zodra een gebruiker een veld in de record begint te bewerken en blijft vergrendeld tot de gebruiker doorgaat naar een andere record. Een record kan dus slechts door één gebruiker tegelijk worden bewerkt. Dit is de manier waarop Access pessimistische vergrendeling implementeert.
Zie het dialoogvenster Schrijfconflict en RecordLocks-eigenschap voor meer informatie.
In SQL Server werkt gelijktijdigheidsbeheer op de volgende manier:
-
Pessimistisch Wanneer een gebruiker een actie uitvoert waardoor de vergrendeling wordt toegepast, kunnen andere gebruikers geen acties uitvoeren die strijdig zouden zijn met de vergrendeling, totdat de eigenaar deze vrijgeeft. Dit gelijktijdigheidsbeheer wordt voornamelijk gebruikt in omgevingen waar gegevens vaak door meerdere personen bijgewerkt worden.
-
Optimistisch Bij de optimistische gelijktijdigheidsbeheerstrategie kunnen gebruikers geen gegevens vergrendelen wanneer ze deze lezen. Wanneer een gebruiker gegevens bijwerkt, wordt in het systeem gecontroleerd of een andere gebruiker de gegevens heeft gewijzigd nadat deze zijn opgehaald. Als een andere gebruiker de gegevens heeft bijgewerkt, wordt een foutmelding weergegeven. De gebruiker die de fout ontvangt, draait de transactie meestal terug en begint opnieuw. Dit gelijktijdigheidsbeheer wordt voornamelijk gebruikt in omgevingen waar gegevens zelden door meerdere personen bijgewerkt worden.
U kunt het type gelijktijdigheidsbeheer opgeven door verschillende transactie-isolatieniveaus te selecteren, die het beschermingsniveau voor de transactie definiëren voor wijzigingen die zijn aangebracht door andere transacties met behulp van de instructie SET TRANSACTION:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Isolatieniveau |
Beschrijving |
|
Niet-vastgelegde leesbewerking |
Transacties worden alleen voldoende geïsoleerd om ervoor te zorgen dat fysiek corrupte gegevens niet worden gelezen. |
|
Vastgelegde leesbewerking |
Transacties kunnen gegevens lezen die eerder door een andere transactie zijn gelezen, zonder te wachten tot de eerste transactie is voltooid. |
|
Herhaalbare leesbewerking |
Er worden lees-en schrijfvergrendelingen uitgevoerd op geselecteerde gegevens tot het einde van de transactie, maar er kunnen zich fantoom-leesbewerkingen voordoen. |
|
Momentopname |
Maakt gebruik van de rijversie om leesconsistentie op transactieniveau te bieden. |
|
Serialiseerbaar |
Transacties zijn volledig geïsoleerd van elkaar. |
Voor meer informatie, zie Handleiding Transactievergrendeling en Rijversie.
Prestaties van query's verbeteren
Wanneer u een Pass Through-query hebt geopend, kunt u gebruikmaken van de geavanceerde manieren waarop SQL Server dit kan verbeteren.
In tegenstelling tot een Access-database biedt SQL Server parallelle query's om de uitvoering van query's en indexbewerkingen voor computers met meer dan één microprocessor (CPU) te optimaliseren. Omdat SQL Server parallel een query of indexbewerking kan uitvoeren door verschillende threads van de systeemwerker te gebruiken, kan de bewerking snel en efficiënt worden voltooid.
Query's vormen een belangrijk onderdeel van het verbeteren van de algehele prestaties van uw databaseoplossing. Verkeerde zoekopdrachten worden eindeloos uitgevoerd, stoppen uit zichzelf en gebruiken bronnen zoals CPU's, geheugen en netwerk-bandit. Dit belemmert de beschikbaarheid van cruciale bedrijfsgegevens. Zelfs één slechte query kan ernstige prestatieproblemen voor uw database veroorzaken.
Zie Snellere query's met SQL Server (e-book) voor meer informatie.
Query-optimalisatie
Er zijn verschillende hulpprogramma's die u kunt gebruiken om de prestaties van een query te analyseren en te verbeteren: Query Optimizer, uitvoeringsplannen en Query Store.
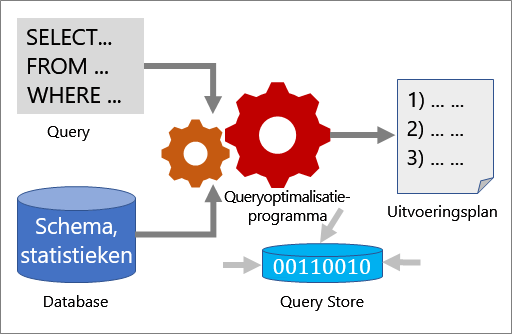
Query optimizer
De Query Optimizer is een van de belangrijkste onderdelen van SQL Server. Gebruik de Query Optimizer om een query te analyseren en de efficiëntste manier te bepalen voor toegang tot de vereiste gegevens. De invoer van het query-optimalisatieprogramma bestaat uit de query, het databaseschema (tabel- en indexdefinities) en de databasestatistieken. De uitvoer van de Query Optimizer is een uitvoeringsplan.
Zie De SQL Server Query Optimizer voor meer informatie.
Uitvoeringsplan
Een uitvoeringsplan is een definitie die de toegang tot de brontabellen sorteert en de methoden die worden gebruikt om gegevens uit elke tabel te extraheren. Optimalisatie is het proces waarbij één uitvoeringsplan wordt geselecteerd uit potentieel vele mogelijke plannen. Elk mogelijk uitvoeringsplan heeft een bijbehorende prijs die is gekoppeld aan de hoeveelheid gebruikte computerresources. Query Optimizer kiest degene met de laagste geschatte kosten.
SQL Server moet ook dynamisch worden aangepast aan veranderende omstandigheden in de database. Regressies in plannen voor query-uitvoering kunnen de prestaties enorm beïnvloeden. Bepaalde wijzigingen in een database kunnen ertoe leiden dat een uitvoeringsplan inefficiënt of ongeldig wordt, op basis van de nieuwe staat van de database. SQL Server detecteert de wijzigingen die een uitvoeringsplan ongeldig maken en markeert het als niet geldig.
Een nieuw plan moet dan opnieuw worden gecompileerd voor de volgende verbinding die de query uitvoert. De voorwaarden die een plan ongeldig maken, zijn onder meer:
-
Wijzigingen die zijn aangebracht in een tabel of weergave waarnaar wordt verwezen door de query (ALTER TABLE en ALTER VIEW).
-
Wijzigingen in indexen die worden gebruikt door het uitvoeringsplan.
-
Updates van statistieken die door het uitvoeringsplan worden gebruikt, hetzij expliciet gegenereerd vanuit een verklaring, zoals UPDATE STATISTICS, of automatisch.
Zie Uitvoeringsplannen voor meer informatie.
Query Store
Query Store biedt inzicht in de keuze en prestaties van het uitvoeringsplan. Het maakt het eenvoudiger om de prestaties te verbeteren door snel prestatieverschillen te vinden die worden veroorzaakt door wijzigingen in het uitvoeringsplan. In de Query Store worden gegevens verzameld over de telemetrie, zoals een geschiedenis van query's, abonnementen, runtime-statistieken en wacht-statistieken. Gebruik de instructie ALTER DATABASE om de Query Store te implementeren:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Zie Prestaties bewaken met behulp van de Query Store voor meer informatie.
Automatische correctie van plannen
De gemakkelijkste manier om de prestaties van query's te verbeteren is met Automatische plancorrectie. Dit is een functie die beschikbaar is in Azure SQL database. U schakelt het gewoon in en laat het werken. Het voert continu bewaking en analyse van uitvoeringsplannen uit, detecteert problematische uitvoeringsplannen en lost automatisch prestatieproblemen op. Achter de schermen gebruikt Automatische plancorrectie een vierstappenstrategie van leren, aanpassen, verifiëren en herhalen.
Zie Automatische afstemming voor meer informatie.
Adaptieve query-verwerking
U kunt ook snellere query's krijgen door een upgrade uit te voeren naar SQL Server 2017, dat een nieuwe functie bevat met de naam adaptieve queryverwerking. In SQL Server worden de opties voor query-planning aangepast op basis van runtime kenmerken.
Cardinaliteitschatting benadert het aantal rijen dat in elke stap in een uitvoeringsplan wordt verwerkt. Onjuiste schattingen kunnen leiden tot een trage query, onnodig brongebruik (geheugen, CPU en i/o) en een beperkte doorvoer en gelijktijdigheid. Drie technieken worden gebruikt om de werkbelastingskarakteristieken van de toepassing aan te passen:
-
Geheugenconfiguratie in batchmodus Slechte kardinaliteitschattingen kunnen ervoor zorgen dat query's naar de schijf worden ‘overlopen’ of dat er te veel geheugenruimte wordt ingenomen. SQL Server 2017 past de toegewezen geheugenruimte aan op basis van uitvoeringsfeedback, verwijdert naar schijf gemorste bestanden en verbetert de gelijktijdigheid voor herhalende query's.
-
Adaptieve joins in batch-modus Adaptieve joins selecteren dynamisch een beter intern jointype (geneste lusjoins, merge-joins of hash-joins) tijdens runtime, op basis van werkelijke invoerrijen. Een plan kan dus dynamisch overschakelen naar een betere join-strategie tijdens de uitvoering.
-
Interleaved execution De functies met een tabelwaardefunctie met meerdere instructies worden normaal gesproken door de query-verwerking als een zwarte doos behandeld. In SQL Server 2017 kunt u het aantal rijen beter ramen, om stroomafwaartse bewerkingen te verbeteren.
U kunt ervoor zorgen dat werkbelastingen automatisch in aanmerking komen voor adaptieve queryverwerking door een compatibiliteitsniveau van 140 voor de database in te schakelen:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Zie Intelligente queryverwerking in SQL-databases voor meer informatie.
Manieren om een query uit te voeren
In SQL Server zijn er verschillende manieren om query's uit te voeren en deze hebben elk hun voordelen. U wilt weten wat ze zijn, zodat u de juiste keuze kunt maken voor uw Access-oplossing. De beste manier om uw TSQL-query's te maken, is door ze interactief te bewerken en te testen met behulp van de SQL Server Management Studio (SSMS) Transact-SQL editor, die IntelliSense heeft om u te helpen bij het kiezen van de juiste trefwoorden en bij de controle op syntaxisfouten.
Weergaven
In SQL Server is een weergave vergelijkbaar met een virtuele tabel, waarbij de weergavegegevens afkomstig zijn van een of meer tabellen of andere weergaven. Er wordt echter verwezen naar de weergaven, net zoals bij tabellen in query's. Weergaven kunnen de complexiteit van query's verbergen en gegevens helpen beschermen door de set rijen en kolommen te beperken. Hier ziet u een voorbeeld van een eenvoudige weergave:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Voor optimale prestaties en om de weergaveresultaten te bewerken, maakt u een geïndexeerde weergave die in de database, zoals een tabel, persistente opslag krijgt en die kan worden opgevraagd zoals elke andere tabel. Als u dit in Access wilt gebruiken, kunt u een koppeling naar de weergave maken op dezelfde manier als u naar een tabel linkt. Hier ziet u een voorbeeld van een geïndexeerde weergave:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Er gelden echter beperkingen. U kunt geen gegevens bijwerken als er meer dan één basistabel bij is betrokken of als de weergave verzamelfuncties of een DISTINCT-component bevat. Als SQL Server een foutmelding geeft dat het niet weet welke record moet worden verwijderd, moet u mogelijk een verwijdertrigger toevoegen aan de weergave. Ten slotte kunt u de ORDER BY-component niet gebruiken zoals u dat in een Access-query kunt doen.
Zie Weergaven en Geïndexeerde weergaven maken voor meer informatie.
Opgeslagen procedures
Een opgeslagen procedure is een groep met een of meer TSQL-instructies waarin invoerparameters worden ingevoerd, uitvoerparameters worden geretourneerd en die een succes of fout aangeven met een statuswaarde. Ze fungeren als een tussenlaag tussen de Access-front-end en de SQL Server-back-end. Opgeslagen procedures kunnen zo eenvoudig zijn als een SELECT-instructie of zo complex als elk ander programma. Hier volgt een voorbeeld:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Wanneer u een opgeslagen procedure in Access gebruikt, wordt er meestal een resultaat teruggestuurd voor een formulier of rapport. Het is echter mogelijk dat er andere acties worden uitgevoerd die geen resultaten opleveren, zoals DDL- of DML-instructies. Wanneer u een pass-through-query gebruikt, moet u de eigenschap Returns Records op de juiste manier instellen.
Zie Opgeslagen procedures voor meer informatie.
Algemene tabelexpressies
Een CTE (Common Table Expressions) is een tijdelijke tabel waarmee een benoemde resultaatset wordt gegenereerd. Het bestaat alleen voor de uitvoering van één query of DML-instructie. Een CTE is gebouwd in dezelfde coderegel als de SELECT-instructie of de DML-instructie die deze gebruikt, terwijl het maken en gebruiken van een tijdelijke tabel of weergave meestal een proces in twee stappen is. Hier volgt een voorbeeld:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
Een CTE heeft verschillende voordelen, waaronder:
-
Omdat CTEs tijdelijk zijn, hoeft u ze niet te maken als permanente databaseobjecten, zoals weergaven.
-
U kunt in een query of een DML-instructie meer dan één keer naar dezelfde CTE verwijzen. Hierdoor kan de code beter worden beheerd.
-
U kunt query's gebruiken die naar een CTE verwijzen om een cursor te definiëren.
Zie WITH common_table_expression voor meer informatie.
Door de gebruiker gedefinieerde functies
Een door de gebruiker gedefinieerde functie (UDF) kan query's en berekeningen uitvoeren en scalaire waarden of sets met gegevensresultaten retourneren. Ze zijn als functies in programmeertalen die parameters accepteren, een actie uitvoeren zoals een complexe berekening en het resultaat van die actie als een waarde retourneren. Hier volgt een voorbeeld:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Voor een UDF gelden bepaalde beperkingen. Ze kunnen bijvoorbeeld bepaalde niet-deterministische systeemfuncties niet gebruiken, en geen DML- of DDL-instructies of dynamische SQL-query's uitvoeren.
Zie Door de gebruiker gedefinieerde functies voor meer informatie.
Sleutels en indexen toevoegen
Welk databasesysteem u ook gebruikt, sleutels en indexen gaan hand in hand.
Sleutels
Zorg er in SQL Server voor dat u primaire sleutels maakt voor elke tabel en externe sleutels voor elke gerelateerde tabel. De equivalente functie in SQL Server voor het gegevenstype Access AutoNumber is de eigenschap IDENTITY, die kan worden gebruikt om sleutelwaarden te maken. Wanneer u deze eigenschap op een numerieke kolom toepast, wordt deze alleen-lezen en wordt deze in het databasesysteem bijgehouden. Wanneer u een record in een tabel invoegt die een IDENTITY-kolom bevat, verhoogt het systeem de waarde voor de IDENTITY-kolom automatisch met 1 beginnend met 1, maar u kunt deze waarden met argumenten bepalen.
Zie CREATE TABLE, IDENTITY (eigenschap) voor meer informatie.
Indexen
Zoals altijd is de selectie van indexen een evenwichtsoefening tussen de query-snelheid en de update-kosten. In Access hebt u één type index, maar in SQL Server heeft u er twaalf. Gelukkig kunt u het hulpprogramma query-optimalisatie gebruiken om op betrouwbare wijze de meest effectieve index te kiezen. En in Azure SQL kunt u automatisch indexbeheer gebruiken, een functie voor automatisch afstemmen, die het toevoegen of verwijderen van indexen aanbeveelt. In tegenstelling tot Access moet u zelf indexen maken voor refererende sleutels in SQL Server. U kunt ook indexen maken voor een geïndexeerde weergave, om de prestaties van query's te verbeteren. Het nadeel van een geïndexeerde weergave is een grotere belasting als u gegevens wijzigt in de basistabellen van de weergave, omdat de weergave ook moet worden bijgewerkt. Zie de SQL Server Index Architecture and Design Guide en Indexen voor meer informatie.
Transacties uitvoeren
Het uitvoeren van een online transactieproces (OLTP) is lastig bij het gebruik van Access, maar relatief eenvoudig met SQL Server. Een transactie is een enkele werkeenheid die alle gegevenswijzigingen doorvoert wanneer deze succesvol zijn, maar de wijzigingen terugdraait wanneer deze niet succesvol zijn. Een transactie moet vier eigenschappen hebben, vaak aangeduid als ACID:
-
Atomiciteit Een transactie moet een atomaire eenheid van werk zijn: alle gegevenswijzigingen worden uitgevoerd of er wordt er geen een uitgevoerd.
-
Consistentie Wanneer u klaar bent, moet een transactie alle gegevens in een consistente status achterlaten. Dit betekent dat alle regels voor gegevensintegriteit zijn toegepast.
-
Isolatie Wijzigingen die door gelijktijdige transacties worden aangebracht, worden geïsoleerd van de huidige transactie.
-
Duurzaamheid Wanneer een transactie is voltooid, zijn de wijzigingen permanent, zelfs bij een systeemstoring.
U gebruikt een transactie om gegarandeerde gegevensintegriteit te garanderen, zoals bij een geldopname uit een geldautomaat of de automatische storting van een salaris. U kunt expliciete, impliciete of transacties met de reikwijdte van een batch uitvoeren. Hier volgen twee TSQL-voorbeelden:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Zie Transacties voor meer informatie.
Beperkingen en triggers gebruiken
Alle databases hebben manieren om de gegevensintegriteit te handhaven.
Beperkingen
In Access dwingt u de referentiële integriteit in een tabelrelatie af met refererende sleutelparen, trapsgewijze bijwerken en verwijderen, en validatieregels. Zie de Handleiding voor tabelrelaties en Gegevensinvoer beperken met behulp van validatieregels voor meer informatie.
In SQL Server gebruikt u UNIQUE-en CHECK-beperkingen. Dit zijn databaseobjecten waarmee de integriteit van gegevens in SQL Server-tabellen wordt afgedwongen. Als u wilt valideren of een waarde geldig is in een andere tabel, gebruikt u een refererende-sleutelbeperking. Gebruik een CHECK-beperking om te valideren of een waarde in een kolom binnen een bepaald bereik valt. Deze objecten zijn uw eerste verdedigingslinie en zijn ontworpen om efficiënt te werken. Zie Unieke beperkingen en controlebeperkingen voor meer informatie.
Triggers
Access beschikt niet over databasetriggers. In SQL Server kunt u triggers gebruiken om ingewikkelde regels voor gegevensintegriteit af te dwingen en om deze bedrijfslogica op de server uit te voeren. Een databasetrigger is een opgeslagen procedure die wordt uitgevoerd wanneer specifieke acties worden uitgevoerd in een database. De trigger is een gebeurtenis, zoals het toevoegen of verwijderen van een record aan een tabel, die wordt gestart en vervolgens de opgeslagen procedure uitvoert. Hoewel een Access-database referentiële integriteit kan controleren wanneer een gebruiker gegevens probeert bij te werken of te verwijderen, beschikt SQL Server over een geavanceerde reeks triggers. U kunt bijvoorbeeld een trigger programmeren om records bulksgewijs te verwijderen en de integriteit van gegevens te waarborgen. U kunt zelfs triggers aan tabellen en weergaven toevoegen.
Zie Triggers - DML, Triggers - DDL en Een T-SQL-trigger ontwerpen voor meer informatie.
Berekende kolommen gebruiken
In Access maakt u een berekende kolom door deze toe te voegen aan een query en een expressie te maken, zoals:
Extended Price: [Quantity] * [Unit Price]
In SQL Server wordt de equivalente functie een berekende kolom genoemd. Dit is een virtuele kolom die niet fysiek in de tabel is opgeslagen, tenzij de kolom is gemarkeerd als PERSISTED. Net als een gecalculeerde kolom gebruikt een berekende kolom gegevens uit andere kolommen in een expressie. Als u een berekende kolom wilt maken, voegt u deze toe aan een tabel. Bijvoorbeeld:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Zie Berekende kolommen specificeren in een tabel voor meer informatie.
Tijdstempel van uw gegevens
U voegt soms een tabelveld toe om een tijdstempel te registreren wanneer een record wordt aangemaakt, zodat u de gegevensinvoer kunt vastleggen. In Access kunt u eenvoudig een datumkolom maken met de standaardwaarde van =Now(). Als u een datum of tijd wilt vastleggen in SQL Server, gebruikt u het gegevenstype datetime2 met een standaardwaarde van SYSDATETIME().
Opmerking Vermijd verwarrende rowversion door een tijdstempel aan uw gegevens toe te voegen. Het zoekwoord tijdstempel is een synoniem voor rowversion in SQL Server, maar u moet het zoekwoord rowversion gebruiken. In SQL Server is rowversion een gegevenstype dat automatisch gegenereerde, unieke binaire getallen in een database beschrijft en dat meestal wordt gebruikt als een mechanisme om tabelrijen van een versienummer te voorzien. Het gegevenstype rowversion is echter slechts een oplopend nummer, behoudt geen datum of tijd en is niet bedoeld om een tijdstempel aan een rij toe te voegen.
Zie rowversion voor meer informatie. Zie Een Access-database migreren naar SQL Server voor meer informatie over het gebruik van rowversion om record-conflicten tot een minimum te beperken.
Grote objecten beheren
In Access kunt u niet-gestructureerde gegevens, zoals bestanden, foto's en afbeeldingen beheren met behulp van het gegevenstype Bijlage. In SQL Server-terminologie worden niet-gestructureerde gegevens ook wel een BLOB (Binairy Large OBject) genoemd. U kunt deze op verschillende manieren gebruiken:
FILESTREAM Gebruikt het gegevenstype varbinary (max) voor het opslaan van de niet-gestructureerde gegevens in het bestandssysteem in plaats van in de database. Zie FILESTREAM-gegevens benaderen met Transact-SQL voor meer informatie.
FileTable Slaat blob's op in speciale tabellen met de naam FileTables en biedt compatibiliteit met Windows-toepassingen alsof ze zijn opgeslagen in het bestandssysteem en zonder wijzigingen aan te brengen in de clienttoepassingen. Voor FileTable moet FILESTREAM worden gebruikt. Zie FileTables voor meer informatie.
Externe BLOB-opslag (RBS) Slaat binaire grote objecten (BLOB's) op in commodity-opslagoplossingen in plaats van rechtstreeks op de server. Zo bespaart u ruimte en worden hardwarebronnen beperkt. Zie BLOB (Binary Large Object) Gegevens voor meer informatie.
Werken met hiërarchische gegevens
Hoewel relationele databases, zoals Access zeer flexibel zijn, is het werken met hiërarchische relaties een uitzondering hetgeen vaak complexe SQL-instructies of code vereist. Voorbeelden van hiërarchische gegevens zijn: een organisatiestructuur, een bestandssysteem, een taxonomie van taal termen en een grafiek met koppelingen tussen webpagina's. SQL Server heeft een ingebouwd hierarchyid-gegevenstype en een reeks hiërarchische functies voor het eenvoudig opslaan, opvragen en beheren van hiërarchische gegevens.
Zie Hiërarchische gegevens en Zelfstudie: Het hierarchyid-gegevenstype gebruiken voor meer informatie.
JSON-tekst bewerken
JavaScript Object Notation (JSON) is een webservice die gebruikmaakt van door mensen leesbare tekst om gegevens te verzenden als attribuut-waardeparen in asynchrone browser-servercommunicatie. Bijvoorbeeld:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Toegang heeft geen ingebouwde manieren om JSON-gegevens te beheren. In SQL Server kunt u JSON-gegevens soepel opslaan, indexeren, doorzoeken en extraheren. U kunt JSON-tekst in een tabel converteren en opslaan of gegevens opmaken als JSON-tekst. Het is bijvoorbeeld mogelijk dat u queryresultaten wilt opmaken als JSON voor een web-app of dat u JSON-gegevensstructuren toe wilt voegen aan rijen en kolommen.
Opmerking JSON wordt niet ondersteund in VBA. Als alternatief kunt u XML in VBA gebruiken met behulp van de MSXML-bibliotheek.
Zie JSON-gegevens in SQL Server voor meer informatie.
Informatiebronnen
Dit is een goed moment om meer te weten te komen over SQL Server en Transact SQL (TSQL). Zoals u hebt gezien, zijn er veel functies die ook in Access voorkomen, maar ook functies die Access gewoon niet heeft. Om uw kennis naar een hoger niveau te brengen, volgen hier een paar trainingsmaterialen:
|
Informatiebron |
Beschrijving |
|
Op video gebaseerde cursus |
|
|
Tutorials over SQL Server 2017 |
|
|
Praktisch leren van Azure |
|
|
Word een expert |
|
|
De belangrijkste openingspagina |
|
|
Help opvragen |
|
|
Help opvragen |
|
|
De essentiële handleiding voor gegevens in de cloud (e-book) |
Een overzicht van de cloud |
|
Een visueel overzicht van de nieuwe functies |
|
|
Een overzicht van de functies per versie |
|
|
SQL Server Express 2017 downloaden |
|
|
Voorbeelddatabases downloaden |









