
Dit artikel is aangepast van Microsoft Excel Data Analysis and Business Modeling door Wayne L. Winston.
-
Wie gebruikt Monte Carlo-simulatie?
-
Wat gebeurt er wanneer u =RAND() typt in een cel?
-
Hoe kunt u waarden van een discrete willekeurige variabele simuleren?
-
Hoe kunt u waarden van een normale willekeurige variabele simuleren?
-
Hoe kan een wenskaartbedrijf bepalen hoeveel kaarten er moeten worden geproduceerd?
We willen de waarschijnlijkheid van onzekere gebeurtenissen nauwkeurig inschatten. Wat is bijvoorbeeld de kans dat de cashflows van een nieuw product een positieve netto contante waarde (NHW) hebben? Wat is de risicofactor van onze beleggingsportefeuille? Monte Carlo-simulatie stelt ons in staat om situaties te modelleren die onzekerheid opleveren en ze vervolgens duizenden keren op een computer uit te spelen.
Opmerking: De naam Monte Carlo-simulatie komt van de computersimulaties uitgevoerd tijdens de jaren 30 en 1940 om de kans te schatten dat de kettingreactie die nodig is om een atoombom te ontploffen succesvol zou werken. De natuurkundigen die betrokken waren bij dit werk waren grote fans van gokken, dus gaven ze de simulaties de codenaam Monte Carlo.
In de volgende vijf hoofdstukken ziet u voorbeelden van hoe u Excel kunt gebruiken om Monte Carlo-simulaties uit te voeren.
Veel bedrijven gebruiken Monte Carlo-simulatie als een belangrijk onderdeel van hun besluitvormingsproces. Hier volgen enkele voorbeelden.
-
General Motors, Proctor and Gamble, Pfizer, Bristol-Myers Squibb en Eli Lilly gebruiken simulatie om zowel het gemiddelde rendement als de risicofactor van nieuwe producten te schatten. Bij GM wordt deze informatie door de CEO gebruikt om te bepalen welke producten op de markt komen.
-
GM maakt gebruik van simulatie voor activiteiten zoals het voorspellen van netto-inkomsten voor de onderneming, het voorspellen van structurele en inkoopkosten en het bepalen van de gevoeligheid voor verschillende soorten risico's (zoals rentewijzigingen en wisselkoersschommelingen).
-
Lilly gebruikt simulatie om de optimale plantcapaciteit voor elk geneesmiddel te bepalen.
-
Proctor en Gamble maakt gebruik van simulatie om valutarisico's te modelleren en optimaal af te dekken.
-
Sears maakt gebruik van simulatie om te bepalen hoeveel eenheden van elke productlijn moeten worden besteld bij leveranciers, bijvoorbeeld het aantal paar Dockers-broeken dat dit jaar moet worden besteld.
-
Olie- en farmaceutische bedrijven gebruiken simulatie om 'echte opties' te waarderen, zoals de waarde van een optie om een project uit te breiden, contract te geven of uit te stellen.
-
Financiële planners gebruiken Monte Carlo-simulatie om optimale beleggingsstrategieën te bepalen voor de pensionering van hun klanten.
Wanneer u de formule =RAND() in een cel typt, krijgt u een getal dat even waarschijnlijk een waarde tussen 0 en 1 aanneemt. Rond 25 procent van de tijd moet u dus een getal krijgen dat kleiner is dan of gelijk is aan 0,25; ongeveer 10 procent van de tijd moet u een getal krijgen dat ten minste 0,90 is, enzovoort. Als u wilt laten zien hoe de functie RAND werkt, bekijkt u het bestand Randdemo.xlsx, weergegeven in afbeelding 60-1.
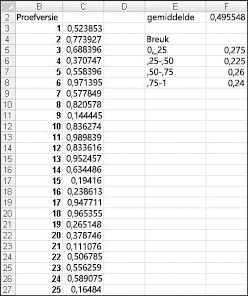
Opmerking: Wanneer u het bestand Randdemo.xlsx opent, ziet u niet dezelfde willekeurige getallen die worden weergegeven in afbeelding 60-1. De functie RAND berekent altijd automatisch de getallen die worden gegenereerd wanneer een werkblad wordt geopend of wanneer nieuwe informatie in het werkblad wordt ingevoerd.
Kopieer eerst van cel C3 naar C4:C402 de formule =RAND(). Vervolgens noemt u het bereik C3: C402-gegevens. Vervolgens kunt u in kolom F het gemiddelde van de 400 willekeurige getallen (cel F2) bijhouden en de functie AANTAL.ALS gebruiken om de breuken tussen 0 en 0,25, 0,25 en 0,50, 0,50 en 0,75 en 0,75 en 1 te bepalen. Wanneer u op F9 drukt, worden de willekeurige getallen opnieuw berekend. U ziet dat het gemiddelde van de 400 getallen altijd ongeveer 0,5 is en dat ongeveer 25 procent van de resultaten tussenpozen van 0,25 is. Deze resultaten zijn consistent met de definitie van een willekeurig getal. Houd er ook rekening mee dat de waarden die door RAND in verschillende cellen worden gegenereerd, onafhankelijk zijn. Als het willekeurige getal dat wordt gegenereerd in cel C3 bijvoorbeeld een groot getal is (bijvoorbeeld 0,99), geeft dit ons niets over de waarden van de andere gegenereerde willekeurige getallen.
Stel dat de vraag naar een kalender wordt bepaald door de volgende discrete willekeurige variabele:
|
Vraag |
kans |
|
10.000 |
0,10 |
|
20.000 |
0,35 |
|
40,000 |
0,3 |
|
60.000 |
0,25 |
Hoe kunnen we deze vraag naar agenda's in Excel laten afspelen of simuleren? De truc is om elke mogelijke waarde van de functie RAND te koppelen aan een mogelijke vraag naar agenda's. De volgende toewijzing zorgt ervoor dat een vraag van 10.000 10 procent van de tijd plaatsvindt, enzovoort.
|
Vraag |
Willekeurig nummer toegewezen |
|
10.000 |
Kleiner dan 0,10 |
|
20.000 |
Groter dan of gelijk aan 0,10 en kleiner dan 0,45 |
|
40,000 |
Groter dan of gelijk aan 0,45 en kleiner dan 0,75 |
|
60.000 |
Groter dan of gelijk aan 0,75 |
Als u de simulatie van de vraag wilt demonstreren, bekijkt u het bestand Discretesim.xlsx, weergegeven in afbeelding 60-2 op de volgende pagina.
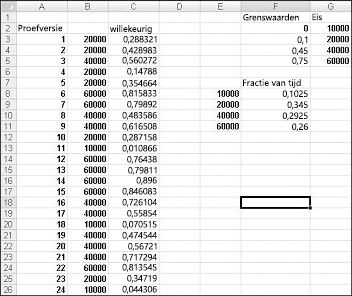
De sleutel tot onze simulatie is om een willekeurig getal te gebruiken om een zoekopdracht te initiëren vanuit het tabelbereik F2:G5 (opzoeken met de naam). Willekeurige getallen groter dan of gelijk aan 0 en kleiner dan 0,10 zullen een vraag van 10.000 opleveren; willekeurige getallen groter dan of gelijk aan 0,10 en kleiner dan 0,45 zullen een vraag van 20.000 opleveren; willekeurige getallen groter dan of gelijk aan 0,45 en kleiner dan 0,75 zullen een vraag van 40.000 opleveren; en willekeurige getallen groter dan of gelijk aan 0,75 leveren een vraag van 60.000 op. U genereert 400 willekeurige getallen door de formule RAND()van C3 naar C4:C402 te kopiëren. Vervolgens genereert u 400 proefversies of iteraties van de agendavraag door de formule VERT.ZOEKEN(C3;opzoeken,2) te kopiëren van B3 naar B4:B402. Deze formule zorgt ervoor dat een willekeurig getal van minder dan 0,10 een vraag van 10.000 genereert, een willekeurig getal tussen 0,10 en 0,45 een vraag van 20.000, enzovoort genereert. Gebruik in het celbereik F8:F11 de functie AANTAL.ALS om het deel van onze 400 iteraties te bepalen dat elke vraag oplevert. Wanneer we op F9 drukken om de willekeurige getallen opnieuw te berekenen, liggen de gesimuleerde waarschijnlijkheden dicht bij de veronderstelde vraagkansen.
Als u in een cel de formule NORMINV(rand(),mu,sigma) typt, genereert u een gesimuleerde waarde van een normale willekeurige variabele met een gemiddelde mu en standaarddeviatie sigma. Deze procedure wordt geïllustreerd in het bestand Normalsim.xlsx, weergegeven in afbeelding 60-3.
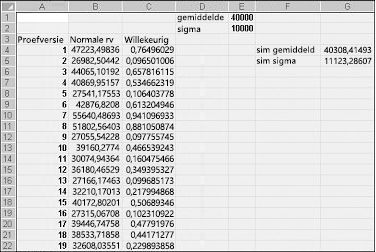
Stel dat we 400 experimenten of iteraties willen simuleren voor een normale willekeurige variabele met een gemiddelde van 40.000 en een standaarddeviatie van 10.000. (U kunt deze waarden typen in de cellen E1 en E2 en deze cellen respectievelijk gemiddelde en sigma noemen.) Als u de formule =RAND() kopieert van C4 naar C5:C403, worden 400 verschillende willekeurige getallen gegenereerd. Bij het kopiëren van B4 naar B5:B403 genereert de formule NORMINV(C4;gemiddelde,sigma) 400 verschillende proefwaarden van een normale willekeurige variabele met een gemiddelde van 40.000 en een standaarddeviatie van 10.000. Wanneer we op F9 drukken om de willekeurige getallen opnieuw te berekenen, blijft het gemiddelde dicht bij 40.000 en de standaarddeviatie bijna 10.000.
Voor een willekeurig getal x genereert de formule NORMINV(p,mu,sigma) het p-percentiel van een normale willekeurige variabele met een gemiddelde mu en een standaarddeviatie sigma. Het willekeurige getal 0,77 in cel C4 (zie afbeelding 60-3) genereert in cel B4 bijvoorbeeld ongeveer het 77e percentiel van een normale willekeurige variabele met een gemiddelde van 40.000 en een standaarddeviatie van 10.000.
In deze sectie ziet u hoe Monte Carlo-simulatie kan worden gebruikt als hulpmiddel voor besluitvorming. Stel dat de vraag naar een Valentijnsdagkaart wordt bepaald door de volgende discrete willekeurige variabele:
|
Vraag |
kans |
|
10.000 |
0,10 |
|
20.000 |
0,35 |
|
40,000 |
0,3 |
|
60.000 |
0,25 |
De wenskaart wordt verkocht voor $ 4,00 en de variabele kosten van het produceren van elke kaart zijn $ 1,50. Overgebleven kaarten moeten worden weggegooid tegen een prijs van $ 0,20 per kaart. Hoeveel kaarten moeten worden afgedrukt?
In principe simuleren we elke mogelijke productiehoeveelheid (10.000, 20.000, 40.000 of 60.000) vaak (bijvoorbeeld 1000 iteraties). Vervolgens bepalen we welke orderhoeveelheid de maximale gemiddelde winst oplevert over de 1000 iteraties. U vindt de gegevens voor deze sectie in het bestand Valentine.xlsx, weergegeven in afbeelding 60-4. U wijst de bereiknamen in cellen B1:B11 toe aan cellen C1:C11. Aan het celbereik G3:H6 is de naamzoekactie toegewezen. Onze verkoopprijs- en kostenparameters worden ingevoerd in de cellen C4:C6.
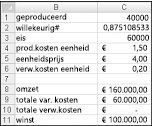
U kunt een proefproductiehoeveelheid (40.000 in dit voorbeeld) invoeren in cel C1. Maak vervolgens een willekeurig getal in cel C2 met de formule =RAND(). Zoals eerder beschreven, simuleert u de vraag naar de kaart in cel C3 met de formule VERT.ZOEKEN(rand,opzoeken,2). (In de formule VERT.ZOEKEN is rand de celnaam die is toegewezen aan cel C3, niet de functie RAND.)
Het aantal verkochte eenheden is het kleinste van onze productiehoeveelheid en vraag. In cel C8 berekent u onze omzet met de formule MIN(geproduceerd,vraag)*unit_price. In cel C9 berekent u de totale productiekosten met de formule geproduceerd*unit_prod_cost.
Als we meer kaarten produceren dan er vraag is, is het aantal eenheden dat overblijft gelijk aan productie minus vraag; anders blijven er geen eenheden over. We berekenen onze verwijderingskosten in cel C10 met de formule unit_disp_cost*ALS(geproduceerd>vraag,geproduceerd-vraag,0). Ten slotte berekenen we in cel C11 onze winst als omzet, total_var_cost total_disposing_cost.
We willen graag een efficiënte manier om F9 vele malen te drukken (bijvoorbeeld 1000) voor elke productiehoeveelheid en de verwachte winst voor elke hoeveelheid te meten. In deze situatie komt een gegevenstabel in twee richtingen ons te hulp. (Zie Hoofdstuk 15, 'Gevoeligheidsanalyse met gegevenstabellen', voor meer informatie over gegevenstabellen.) De gegevenstabel die in dit voorbeeld wordt gebruikt, wordt weergegeven in afbeelding 60-5.
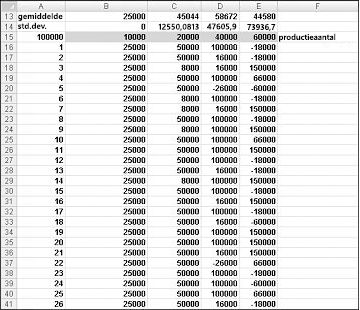
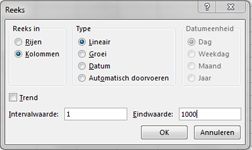
Voer in het celbereik A16:A1015 de getallen 1-1000 in (overeenkomend met onze 1000 tests). Een eenvoudige manier om deze waarden te maken, is door 1 in cel A16 in te voeren. Selecteer de cel en klik vervolgens op het tabblad Start in de groep Bewerken op Opvullen en selecteer Reeks om het dialoogvenster Reeks weer te geven. Voer in het dialoogvenster Reeks , weergegeven in afbeelding 60-6, een stapwaarde van 1 en een stopwaarde van 1000 in. Selecteer in het gebied Reeks in de optie Kolommen en klik vervolgens op OK. De getallen 1-1000 worden ingevoerd in kolom A, beginnend in cel A16.
Vervolgens voeren we onze mogelijke productiehoeveelheden (10.000, 20.000, 40.000, 60.000) in cellen B15:E15 in. We willen de winst berekenen voor elk proefnummer (1 tot en met 1000) en elke productiehoeveelheid. We verwijzen naar de formule voor winst (berekend in cel C11) in de cel linksboven in onze gegevenstabel (A15) door =C11 in te voeren.
We zijn nu klaar om Excel te verleiden tot het simuleren van 1000 iteraties van de vraag voor elke productiehoeveelheid. Selecteer het tabelbereik (A15:E1014) en klik in de groep Hulpmiddelen voor gegevens op het tabblad Gegevens op What If-analyse en selecteer vervolgens Gegevenstabel. Als u een gegevenstabel in twee richtingen wilt instellen, kiest u onze productiehoeveelheid (cel C1) als rijinvoercel en selecteert u een lege cel (we hebben cel I14 gekozen) als kolominvoercel. Nadat u op OK hebt geklikt, simuleert Excel 1000 vraagwaarden voor elke orderhoeveelheid.
Als u wilt weten waarom dit werkt, bekijkt u de waarden die door de gegevenstabel in het celbereik C16:C1015 worden geplaatst. Voor elk van deze cellen gebruikt Excel een waarde van 20.000 in cel C1. In C16 wordt de kolominvoercelwaarde van 1 in een lege cel geplaatst en wordt het willekeurige getal in cel C2 opnieuw berekend. De bijbehorende winst wordt vervolgens geregistreerd in cel C16. Vervolgens wordt de invoerwaarde van de kolomcel 2 in een lege cel geplaatst en wordt het willekeurige getal in C2 opnieuw berekend. De bijbehorende winst wordt ingevoerd in cel C17.
Door van cel B13 naar C13:E13 de formule AVERAGE(B16:B1015) te kopiëren, berekenen we de gemiddelde gesimuleerde winst voor elke productiehoeveelheid. Door van cel B14 naar C14:E14 de formule STDEV(B16:B1015) te kopiëren, berekenen we de standaarddeviatie van onze gesimuleerde winst voor elke orderhoeveelheid. Telkens wanneer we op F9 drukken, worden 1000 iteraties van de vraag gesimuleerd voor elke orderhoeveelheid. Het produceren van 40.000 kaarten levert altijd de grootste verwachte winst op. Daarom lijkt het erop dat het produceren van 40.000 kaarten de juiste beslissing is.
De impact van risico op onze beslissing Als we 20.000 in plaats van 40.000 kaarten produceren, daalt onze verwachte winst met ongeveer 22 procent, maar ons risico (gemeten aan de standaarddeviatie van de winst) daalt met bijna 73 procent. Daarom is het produceren van 20.000 kaarten de juiste beslissing als we uiterst afkeren van risico's. Overigens heeft het produceren van 10.000 kaarten altijd een standaarddeviatie van 0 kaarten, want als we 10.000 kaarten produceren, zullen we ze altijd allemaal verkopen zonder restjes.
Opmerking: In deze werkmap is de optie Berekening ingesteld op Automatisch behalve voor tabellen. (Gebruik de opdracht Berekening in de groep Berekening op het tabblad Formules.) Deze instelling zorgt ervoor dat de gegevenstabel niet opnieuw wordt berekend, tenzij we op F9 drukken. Dit is een goed idee omdat een grote gegevenstabel uw werk vertraagt als deze telkens opnieuw wordt berekend wanneer u iets in het werkblad typt. Houd er rekening mee dat wanneer u in dit voorbeeld op F9 drukt, de gemiddelde winst verandert. Dit gebeurt omdat elke keer dat u op F9 drukt, een andere reeks van 1000 willekeurige getallen wordt gebruikt om de vraag voor elke orderhoeveelheid te genereren.
Betrouwbaarheidsinterval voor gemiddelde winst Een natuurlijke vraag om in deze situatie te stellen is, in welk interval zijn we er 95 procent zeker van dat de werkelijke gemiddelde winst zal dalen? Dit interval wordt het betrouwbaarheidsinterval van 95 procent voor de gemiddelde winst genoemd. Een betrouwbaarheidsinterval van 95 procent voor het gemiddelde van een simulatie-uitvoer wordt berekend met de volgende formule:
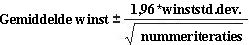
In cel J11 berekent u de ondergrens voor het betrouwbaarheidsinterval van 95 procent op de gemiddelde winst wanneer 40.000 kalenders worden geproduceerd met de formule D13-1,96*D14/SQRT(1000). In cel J12 berekent u de bovengrens voor ons betrouwbaarheidsinterval van 95 procent met de formule D13+1,96*D14/SQRT(1000). Deze berekeningen worden weergegeven in afbeelding 60-7.

We zijn er 95 procent zeker van dat onze gemiddelde winst wanneer 40.000 agenda's worden besteld tussen $ 56.687 en $ 62.589 ligt.
-
Een GMC-dealer is van mening dat de vraag naar 2005 Envoys normaal gesproken zal worden verdeeld met een gemiddelde van 200 en een standaarddeviatie van 30. Zijn kosten voor het ontvangen van een Envoy zijn $ 25.000 en hij verkoopt een Envoy voor $ 40.000. De helft van alle Envoys die niet voor de volledige prijs worden verkocht, kan worden verkocht voor $ 30.000. Hij overweegt 200, 220, 240, 260, 280 of 300 Envoys te bestellen. Hoeveel moet hij bestellen?
-
Een kleine supermarkt probeert te bepalen hoeveel exemplaren van Mensen tijdschrift ze elke week moeten bestellen. Ze zijn van mening dat hun vraag naar Mensen wordt bepaald door de volgende discrete willekeurige variabele:
Vraag
kans
15
0,10
20
0.20
25
0.30
30
0,25
35
0,15
-
De supermarkt betaalt $ 1,00 voor elk exemplaar van Mensen en verkoopt het voor $ 1,95. Elke onverkochte kopie kan worden geretourneerd voor $ 0,50. Hoeveel exemplaren van Mensen moet de winkel bestellen?
Meer hulp nodig?
U kunt altijd uw vraag stellen aan een expert in de Excel Tech Community of ondersteuning vragen in de Communities.









