
En riktig utformet database gir deg tilgang til oppdatert, nøyaktig informasjon. Fordi en riktig utforming er avgjørende for å nå målene dine i å arbeide med en database, er det fornuftig å investere tiden det tar å lære prinsippene for god utforming. Til slutt er det mye mer sannsynlig at du ender opp med en database som oppfyller behovene dine, og som enkelt kan imøtekomme endringer.
Denne artikkelen inneholder retningslinjer for planlegging av en skrivebordsdatabase. Du vil lære hvordan du bestemmer hvilken informasjon du trenger, hvordan du deler denne informasjonen inn i de aktuelle tabellene og kolonnene, og hvordan disse tabellene er relatert til hverandre. Du bør lese denne artikkelen før du oppretter den første skrivebordsdatabasen.
I denne artikkelen
Noen databasetermer å vite
Access organiserer informasjonen i tabeller: lister med rader og kolonner som minner om en regnskapsførers tastatur eller et regneark. I en enkel database har du kanskje bare én tabell. For de fleste databaser trenger du mer enn én. Du kan for eksempel ha en tabell som lagrer informasjon om produkter, en annen tabell som lagrer informasjon om ordrer, og en annen tabell med informasjon om kunder.
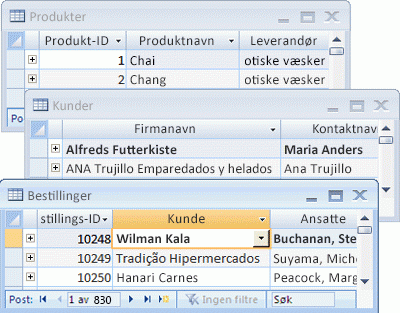
Hver rad kalles en post på riktig måte, og hver kolonne, et felt. En post er en meningsfull og konsekvent måte å kombinere informasjon om noe på. Et felt er ett enkelt informasjonselement – en elementtype som vises i hver post. I for eksempel Produkter-tabellen vil hver rad eller post inneholde informasjon om ett produkt. Hver kolonne, eller hvert felt, inneholder en type informasjon om produktet, for eksempel navn eller pris.
Hva er god databaseutforming?
Enkelte prinsipper veileder utformingsprosessen for databasen. Det første prinsippet er at duplisert informasjon (også kalt overflødige data) er ugyldig, fordi den kaster bort plass og øker sannsynligheten for feil og inkonsekvenser. Det andre prinsippet er at riktighet og fullstendighet av informasjon er viktig. Hvis databasen inneholder feil informasjon, vil alle rapporter som henter informasjon fra databasen, også inneholde feil informasjon. Som et resultat vil eventuelle beslutninger du tar som er basert på disse rapportene, deretter bli feilinformert.
En god databaseutforming er derfor en som:
-
Deler informasjonen inn i emnebaserte tabeller for å redusere overflødige data.
-
Gir Access informasjonen som kreves for å koble sammen informasjonen i tabellene etter behov.
-
Bidrar til å støtte og sikre nøyaktigheten og integriteten til informasjonen.
-
Imøtekommer behovene for databehandling og rapportering.
Utformingsprosessen
Utformingsprosessen består av følgende trinn:
-
Bestem formålet med databasen
Dette bidrar til å forberede deg på resten av trinnene.
-
Finn og organiser den nødvendige informasjonen
Samle inn alle typer informasjon du kanskje vil registrere i databasen, for eksempel produktnavn og ordrenummer.
-
Dele informasjonen inn i tabeller
Del informasjonselementene inn i hovedenheter eller emner, for eksempel Produkter eller Ordrer. Hvert emne blir deretter en tabell.
-
Gjøre informasjonselementer om til kolonner
Bestem hvilken informasjon du vil lagre i hver tabell. Hvert element blir et felt, og vises som en kolonne i tabellen. En Ansatte-tabell kan for eksempel inneholde felt som Etternavn og Ansettelsesdato.
-
Angi primærnøkler
Velg primærnøkkelen for hver tabell. Primærnøkkelen er en kolonne som brukes til å identifisere hver rad unikt. Et eksempel kan være produkt-ID eller ordre-ID.
-
Konfigurere tabellrelasjonene
Se på hver tabell, og bestem hvordan dataene i én tabell er relatert til dataene i andre tabeller. Legg til felt i tabeller eller opprett nye tabeller for å tydeliggjøre relasjonene etter behov.
-
Begrens utformingen
Analyser utformingen for feil. Opprett tabellene, og legg til noen poster med eksempeldata. Se om du kan få resultatene du ønsker fra tabellene. Foreta justeringer i utformingen etter behov.
-
Bruke normaliseringsreglene
Bruk datanormaliseringsreglene for å se om tabellene er strukturert riktig. Foreta justeringer i tabellene etter behov.
Fastslå formålet med databasen
Det er lurt å skrive ned formålet med databasen på papir – formålet med den, hvordan du forventer å bruke den, og hvem som skal bruke den. For en liten database for en hjemmebasert bedrift kan du for eksempel skrive noe enkelt, for eksempel «Kundedatabasen oppbevarer en liste over kundeinformasjon med det formål å produsere masseutsendelse og rapporter». Hvis databasen er mer kompleks eller brukes av mange personer, som ofte forekommer i en bedriftsinnstilling, kan formålet enkelt være et avsnitt eller mer, og bør inkludere når og hvordan hver person skal bruke databasen. Ideen er å ha en godt utviklet misjonserklæring som kan refereres til gjennom hele designprosessen. Å ha en slik uttalelse hjelper deg med å fokusere på målene dine når du tar avgjørelser.
Finne og organisere den nødvendige informasjonen
Hvis du vil finne og organisere informasjonen som kreves, starter du med den eksisterende informasjonen. Du kan for eksempel registrere innkjøpsordrer i en hovedbok eller beholde kundeinformasjon på papirskjemaer i et arkivskap. Samle inn disse dokumentene og vis hver type informasjon som vises (for eksempel hver boks du fyller ut i et skjema). Hvis du ikke har noen eksisterende skjemaer, kan du tenke deg i stedet at du må utforme et skjema for å registrere kundeinformasjonen. Hvilken informasjon vil du legge inn i skjemaet? Hvilke utfyllingsbokser ville du opprettet? Identifiser og list opp hvert av disse elementene. Anta for eksempel at du for øyeblikket har kundelisten på indekskort. Undersøkelse av disse kortene kan vise at hvert kort inneholder et kundenavn, adresse, poststed, delstat, postnummer og telefonnummer. Hvert av disse elementene representerer en potensiell kolonne i en tabell.
Når du klargjør denne listen, trenger du ikke å bekymre deg for å få den perfekt i begynnelsen. List i stedet opp hvert element som kommer til hjernen. Hvis noen andre skal bruke databasen, kan du også be om ideene deres. Du kan finjustere listen senere.
Vurder deretter hvilke typer rapporter eller masseutsendelse du kanskje vil produsere fra databasen. Du vil for eksempel kanskje at en produktsalgsrapport skal vise salg etter område eller en lagersammendragsrapport som viser produktlagernivåer. Det kan også hende du vil generere skjemabrev som skal sendes til kunder som annonserer et salgsarrangement eller tilbyr en premie. Utform rapporten i tankene dine, og tenk deg hvordan den vil se ut. Hvilken informasjon vil du plassere i rapporten? List opp hvert element. Gjør det samme for skjemabrevet og for alle andre rapporter du forventer å opprette.

Hvis du tenker på rapportene og masseutsenderingene du kanskje vil opprette, er det enklere å identifisere elementer du trenger i databasen. Anta for eksempel at du gir kundene muligheten til å melde seg på (eller av) periodiske e-postoppdateringer, og at du vil skrive ut en liste over de som har meldt seg på. Hvis du vil registrere denne informasjonen, legger du til en «Send e-post»-kolonne i kundetabellen. For hver kunde kan du angi feltet til Ja eller Nei.
Kravet om å sende e-postmeldinger til kunder foreslår et annet element å registrere. Når du vet at en kunde ønsker å motta e-postmeldinger, må du også vite e-postadressen de skal sendes til. Derfor må du registrere en e-postadresse for hver kunde.
Det er fornuftig å konstruere en prototype av hver rapport eller utdataliste og vurdere hvilke elementer du trenger for å produsere rapporten. Når du for eksempel undersøker et skjemabrev, kan et par ting komme til hjernen. Hvis du vil inkludere en riktig hilsen, for eksempel «Mr.», «Fru» eller «Fru» som starter en hilsen, må du opprette et hilsenselement. Du kan også vanligvis starte et brev med "Kjære Mr. Smith", i stedet for "Kjære. Mr. Sylvester Smith". Dette tyder på at du vanligvis vil lagre etternavnet atskilt fra fornavnet.
Et viktig poeng å huske er at du bør dele opp hver del av informasjonen i de minste nyttige delene. Hvis du vil gjøre etternavnet lett tilgjengelig når det gjelder et navn, deler du navnet opp i to deler – Fornavn og Etternavn. Hvis du for eksempel vil sortere en rapport etter etternavn, hjelper det å lagre kundens etternavn separat. Hvis du vil sortere, søke, beregne eller rapportere basert på et informasjonselement, bør du generelt plassere elementet i et eget felt.
Tenk på spørsmålene du kanskje vil at databasen skal svare på. Hvor mange salg av det utvalgte produktet avsluttet du forrige måned? Hvor bor de beste kundene dine? Hvem er leverandøren for ditt bestselgende produkt? Hvis du forventer disse spørsmålene, kan du få null på flere elementer du kan registrere.
Når du har samlet inn denne informasjonen, er du klar for neste trinn.
Dele informasjonen inn i tabeller
Hvis du vil dele informasjonen inn i tabeller, velger du hovedenhetene eller emnene. Når du for eksempel har funnet og organisert informasjon for en produktsalgsdatabase, kan den foreløpige listen se slik ut:

Hovedenhetene som vises her, er produktene, leverandørene, kundene og ordrene. Det er derfor fornuftig å starte med disse fire tabellene: én for fakta om produkter, én for fakta om leverandører, én for fakta om kunder og én for fakta om ordrer. Selv om dette ikke fullfører listen, er det et godt utgangspunkt. Du kan fortsette å begrense listen til du har en utforming som fungerer bra.
Når du først ser gjennom den foreløpige listen over elementer, kan du bli fristet til å plassere alle i én enkelt tabell, i stedet for de fire som vises i den foregående illustrasjonen. Du vil lære her hvorfor det er en dårlig idé. Vurder et øyeblikk, tabellen som vises her:
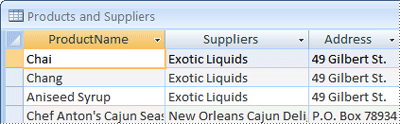
I dette tilfellet inneholder hver rad informasjon om både produktet og leverandøren. Fordi du kan ha mange produkter fra samme leverandør, må leverandørnavnet og adresseinformasjonen gjentas mange ganger. Dette opptar unødig diskplass. Registrering av leverandørinformasjon bare én gang i en separat leverandørtabell, og deretter koble tabellen til Produkter-tabellen, er en mye bedre løsning.
Et annet problem med denne utformingen oppstår når du trenger å endre informasjon om leverandøren. Anta for eksempel at du må endre adressen til en leverandør. Fordi adressen vises mange steder, kan det hende du ved et uhell endrer den på ett sted, men glemmer å endre den på de andre. Registrering av leverandørens adresse på bare ett sted løser problemet.
Når du utformer databasen, kan du alltid prøve å registrere hvert faktum bare én gang. Hvis du gjentar den samme informasjonen på mer enn ett sted, for eksempel adressen til en bestemt leverandør, plasserer du denne informasjonen i en egen tabell.
La oss til slutt anta at det bare er ett produkt levert av Coho Winery, og at du vil slette produktet, men beholde leverandørens navn og adresseinformasjon. Hvordan vil du slette produktposten uten også å miste leverandørinformasjonen? Det går ikke. Fordi hver post inneholder fakta om et produkt, i tillegg til fakta om en leverandør, kan du ikke slette den ene uten å slette den andre. Hvis du vil holde disse faktaene atskilt, må du dele den ene tabellen i to: én tabell for produktinformasjon og en annen tabell for leverandørinformasjon. Hvis du sletter en produktpost, slettes bare fakta om produktet, ikke fakta om leverandøren.
Når du har valgt emnet som representeres av en tabell, bør kolonnene i tabellen bare lagre fakta om emnet. Produkttabellen bør for eksempel bare lagre fakta om produkter. Fordi leverandøradressen er et faktum om leverandøren, og ikke et faktum om produktet, hører den til i leverandørtabellen.
Gjøre informasjonselementer om til kolonner
Hvis du vil fastslå kolonnene i en tabell, bestemmer du hvilken informasjon du trenger å spore om emnet som er registrert i tabellen. For kunder-tabellen, for eksempel Navn, Adresse, Poststed-Poststed, Send e-post, Hilsen og E-postadresse utgjør en god startliste med kolonner. Hver post i tabellen inneholder samme sett med kolonner, slik at du kan lagre navn, adresse, poststed-postnummer, send e-post, hilsen og e-postadresseinformasjon for hver post. Adressekolonnen inneholder for eksempel kundenes adresser. Hver post inneholder data om én kunde, og adressefeltet inneholder adressen til kunden.
Når du har bestemt det første settet med kolonner for hver tabell, kan du finjustere kolonnene ytterligere. Det er for eksempel fornuftig å lagre kundenavnet som to separate kolonner: fornavn og etternavn, slik at du kan sortere, søke og indeksere på bare disse kolonnene. På samme måte består adressen faktisk av fem separate komponenter, adresse, poststed, delstat, postnummer og land/område, og det er også fornuftig å lagre dem i separate kolonner. Hvis du for eksempel vil utføre en søke-, filter- eller sorteringsoperasjon etter delstat, trenger du tilstandsinformasjonen som er lagret i en egen kolonne.
Du bør også vurdere om databasen vil inneholde informasjon som bare er av innenlandsk opprinnelse, eller internasjonalt. Hvis du for eksempel planlegger å lagre internasjonale adresser, er det bedre å ha en områdekolonne i stedet for Delstat, fordi en slik kolonne kan gi plass til både nasjonale delstater og områder i andre land/områder. På samme måte gir postnummer mer mening enn postnummer hvis du skal lagre internasjonale adresser.
Listen nedenfor viser noen tips for å fastslå kolonnene.
-
Ikke inkluder beregnede data
I de fleste tilfeller bør du ikke lagre resultatet av beregninger i tabeller. I stedet kan du få Access til å utføre beregningene når du vil se resultatet. Anta for eksempel at det finnes en rapport om produkter på bestilling som viser delsummen for enheter i rekkefølge for hver produktkategori i databasen. Det finnes imidlertid ingen delsumkolonne for enheter i ordre i noen tabell. I stedet inneholder Produkter-tabellen en enhetsrekkefølge-kolonne som lagrer enhetene i ordre for hvert produkt. Ved hjelp av disse dataene beregner Access delsummen hver gang du skriver ut rapporten. Selve delsummen bør ikke lagres i en tabell.
-
Lagre informasjon i de minste logiske delene
Du kan bli fristet til å ha ett enkelt felt for fullt navn, eller for produktnavn sammen med produktbeskrivelser. Hvis du kombinerer mer enn én type informasjon i et felt, er det vanskelig å hente individuelle fakta senere. Prøv å dele opp informasjon i logiske deler. Du kan for eksempel opprette separate felt for fornavn og etternavn, eller for produktnavn, kategori og beskrivelse.

Når du har raffinert datakolonnene i hver tabell, er du klar til å velge primærnøkkelen for hver tabell.
Angi primærnøkler
Hver tabell bør inneholde en kolonne eller et sett med kolonner som unikt identifiserer hver rad som er lagret i tabellen. Dette er ofte et unikt identifikasjonsnummer, for eksempel et ansatt-ID-nummer eller et serienummer. I databaseterminologi kalles denne informasjonen primærnøkkelen for tabellen. Access bruker primærnøkkelfelt til raskt å knytte data fra flere tabeller og samle dataene for deg.
Hvis du allerede har en unik identifikator for en tabell, for eksempel et produktnummer som unikt identifiserer hvert produkt i katalogen, kan du bruke denne identifikatoren som primærnøkkelen for tabellen, men bare hvis verdiene i denne kolonnen alltid vil være forskjellige for hver post. Du kan ikke ha dupliserte verdier i en primærnøkkel. Du må for eksempel ikke bruke navn på personer som primærnøkkel, fordi navnene ikke er unike. Du kan enkelt ha to personer med samme navn i samme tabell.
En primærnøkkel må alltid ha en verdi. Hvis en kolonneverdi kan bli ikke-tilordnet eller ukjent (en manglende verdi) på et tidspunkt, kan den ikke brukes som en komponent i en primærnøkkel.
Du bør alltid velge en primærnøkkel hvis verdi ikke endres. I en database som bruker mer enn én tabell, kan primærnøkkelen for en tabell brukes som en referanse i andre tabeller. Hvis primærnøkkelen endres, må endringen også brukes overalt hvor nøkkelen refereres til. Hvis du bruker en primærnøkkel som ikke endres, reduseres sjansen for at primærnøkkelen blir synkronisert med andre tabeller som refererer til den.
Ofte brukes et vilkårlig unikt tall som primærnøkkel. Du kan for eksempel tilordne hver ordre et unikt ordrenummer. Det eneste formålet med ordrenummeret er å identifisere en ordre. Når den er tilordnet, endres den aldri.
Hvis du ikke har i tankene en kolonne eller et sett med kolonner som kan lage en god primærnøkkel, bør du vurdere å bruke en kolonne som har datatypen Autonummer. Når du bruker datatypen Autonummer, tilordner Access automatisk en verdi for deg. En slik identifikator er faktaløs; den inneholder ingen faktainformasjon som beskriver raden den representerer. Faktaløse identifikatorer er ideelle for bruk som primærnøkkel fordi de ikke endres. Det er mer sannsynlig at en primærnøkkel som inneholder fakta om en rad – et telefonnummer eller et kundenavn – endres, fordi den faktiske informasjonen i seg selv kan endres.
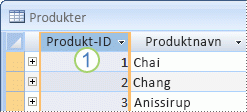
1. En kolonne som er satt til datatypen Autonummer, lager ofte en god primærnøkkel. Ingen produkt-ID-er er like.
I noen tilfeller vil du kanskje bruke to eller flere felt som sammen angir primærnøkkelen for en tabell. En Ordredetaljer-tabell som lagrer linjeelementer for ordrer, bruker for eksempel to kolonner i primærnøkkelen: Ordre-ID og Produkt-ID. Når en primærnøkkel bruker mer enn én kolonne, kalles den også en sammensatt nøkkel.
For produktsalgsdatabasen kan du opprette en Autonummerering-kolonne for hver av tabellene som skal fungere som primærnøkkel: Produkt-ID for Produkter-tabellen, OrdreID for ordretabellen, KundeID for Kunder-tabellen og LeverandørID for leverandører-tabellen.

Opprette tabellrelasjonene
Nå som du har delt informasjonen inn i tabeller, trenger du en måte å samle informasjonen på nytt på meningsfulle måter. Følgende skjema inneholder for eksempel informasjon fra flere tabeller.
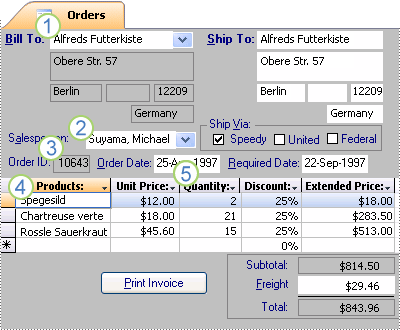
1. Informasjonen i dette skjemaet kommer fra Kunder-tabellen ...
2. ... Ansatte-tabellen...
3. ... Ordrer-tabellen...
4. ... Produkter-tabellen...
5. ... og Ordredetaljer-tabellen.
Access er et relasjonsdatabasebehandlingssystem. I en relasjonsdatabase deler du informasjonen inn i separate, emnebaserte tabeller. Deretter bruker du tabellrelasjoner til å samle informasjonen etter behov.
Opprette en én-til-mange-relasjon
Vurder dette eksemplet: Tabellene Leverandører og Produkter i databasen for produktordrer. En leverandør kan oppgi et hvilket som helst antall produkter. Det følgende gjelder for alle leverandører representert i leverandører-tabellen, det kan være mange produkter representert i Produkter-tabellen. Relasjonen mellom Leverandører-tabellen og Produkter-tabellen er derfor en én-til-mange-relasjon.
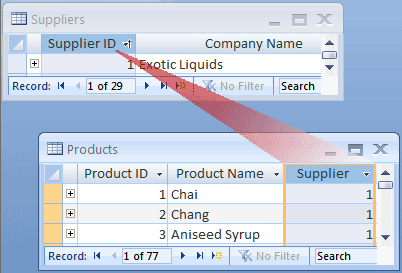
Hvis du vil representere en én-til-mange-relasjon i databaseutformingen, tar du primærnøkkelen på «én»-siden av relasjonen og legger den til som en ekstra kolonne eller kolonner i tabellen på «mange»-siden av relasjonen. I dette tilfellet legger du for eksempel til kolonnen Leverandør-ID fra Leverandører-tabellen i Produkter-tabellen. Access kan deretter bruke leverandør-ID-nummeret i Produkter-tabellen til å finne riktig leverandør for hvert produkt.
Kolonnen leverandør-ID i Produkter-tabellen kalles en sekundærnøkkel. En sekundærnøkkel er primærnøkkelen til en annen tabell. Kolonnen Leverandør-ID i Produkter-tabellen er en sekundærnøkkel fordi den også er primærnøkkelen i Leverandører-tabellen.

Du angir grunnlaget for sammenføyning av relaterte tabeller ved å opprette sammenkoblinger av primærnøkler og sekundærnøkler. Hvis du ikke er sikker på hvilke tabeller som skal dele en felles kolonne, sikrer identifisering av en én-til-mange-relasjon at de to tabellene som er involvert, faktisk krever en delt kolonne.
Opprette en mange-til-mange-relasjon
Vurder relasjonen mellom Produkter-tabellen og Ordrer-tabellen.
Én enkelt ordre kan inkludere mer enn én vare. På den andre siden kan én enkelt vare vises i mange ordrer. For hver post i ordretabellen kan det derfor være mange poster i varetabellen. Og for hver post i Produkter-tabellen kan det være mange poster i Ordrer-tabellen. Denne typen relasjon kalles en mange-til-mange-relasjon fordi for alle produkter kan det være mange ordrer. og for enhver ordre kan det være mange produkter. Vær oppmerksom på at hvis du vil oppdage mange-til-mange-relasjoner mellom tabellene, er det viktig at du vurderer begge sider av relasjonen.
Emnene for de to tabellene – ordrer og produkter – har en mange-til-mange-relasjon. Dette presenterer et problem. Hvis du vil forstå problemet, kan du tenke deg hva som ville skje hvis du prøvde å opprette relasjonen mellom de to tabellene ved å legge til Produkt-ID-feltet i Ordrer-tabellen. Hvis du vil ha mer enn ett produkt per ordre, trenger du mer enn én post i Ordrer-tabellen per ordre. Du gjentar ordreinformasjon for hver rad som er relatert til én enkelt rekkefølge, noe som resulterer i en ineffektiv utforming som kan føre til unøyaktige data. Du støter på det samme problemet hvis du legger feltet Ordre-ID i Produkter-tabellen – du vil ha mer enn én post i Produkter-tabellen for hvert produkt. Hvordan løser du dette problemet?
Svaret er å opprette en tredje tabell, ofte kalt en forbindelsestabell, som bryter ned mange-til-mange-relasjonen i to én-til-mange-relasjoner. Du setter inn primærnøkkelen fra hver av de to tabellene i den tredje tabellen. Som et resultat registrerer den tredje tabellen hver forekomst eller forekomst av relasjonen.
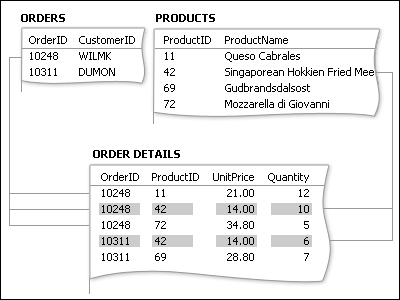
Hver post i Ordredetaljer-tabellen representerer ett linjeelement i en ordre. Primærnøkkelen for Ordredetaljer-tabellen består av to felt – sekundærnøklene fra tabellene Ordrer og Produkter. Bruk av ordre-ID-feltet alene fungerer ikke som primærnøkkel for denne tabellen, fordi én ordre kan ha mange linjeelementer. Ordre-IDen gjentas for hvert linjeelement i en ordre, slik at feltet ikke inneholder unike verdier. Bruk av produkt-ID-feltet alene fungerer heller ikke, fordi ett produkt kan vises på mange forskjellige ordrer. Men sammen produserer de to feltene alltid en unik verdi for hver post.
Ordrer-tabellen og Produkter-tabellen er ikke direkte relatert til hverandre i produktsalgsdatabasen. I stedet er de relatert indirekte gjennom Ordredetaljer-tabellen. Mange-til-mange-relasjonen mellom ordrer og produkter representeres i databasen ved hjelp av to én-til-mange-relasjoner:
-
Ordretabellen og Ordredetaljer-tabellen har en én-til-mange-relasjon. Hver ordre kan ha mer enn ett linjeelement, men hvert linjeelement er koblet til bare én ordre.
-
Produkter-tabellen og Ordredetaljer-tabellen har en én-til-mange-relasjon. Hvert produkt kan ha mange linjeelementer knyttet til seg, men hvert linjeelement refererer bare til ett produkt.
Fra Ordredetaljer-tabellen kan du bestemme alle produktene i en bestemt rekkefølge. Du kan også bestemme alle ordrene for et bestemt produkt.
Når du har inkorporert Ordredetaljer-tabellen, kan listen over tabeller og felt se omtrent slik ut:

Opprette en én-til-én-relasjon
En annen type relasjon er én-til-én-relasjonen. Anta for eksempel at du må registrere noen spesielle tilleggsproduktinformasjon som du trenger sjeldent, eller som bare gjelder for noen få produkter. Fordi du ikke trenger informasjonen ofte, og fordi lagring av informasjonen i Produkter-tabellen fører til tom plass for hvert produkt den ikke gjelder for, plasserer du den i en egen tabell. I likhet med Produkter-tabellen bruker du ProductID som primærnøkkel. Relasjonen mellom denne ekstra tabellen og produkttabellen er en én-til-én-relasjon. For hver post i Produkt-tabellen finnes det én enkelt samsvarende post i den supplerende tabellen. Når du identifiserer en slik relasjon, må begge tabellene dele et fellesfelt.
Når du oppdager behovet for en én-til-én-relasjon i databasen, bør du vurdere om du kan plassere informasjonen fra de to tabellene sammen i én tabell. Hvis du ikke vil gjøre dette av en eller annen grunn, kanskje fordi det vil resultere i mye tom plass, viser følgende liste hvordan du representerer relasjonen i utformingen:
-
Hvis de to tabellene har samme emne, kan du sannsynligvis konfigurere relasjonen ved hjelp av den samme primærnøkkelen i begge tabellene.
-
Hvis de to tabellene har ulike emner med ulike primærnøkler, velger du én av tabellene (én av dem) og setter inn primærnøkkelen i den andre tabellen som en sekundærnøkkel.
Hvis du fastslår relasjonene mellom tabeller, sikrer du at du har de riktige tabellene og kolonnene. Når det finnes en én-til-én- eller én-til-mange-relasjon, må de involverte tabellene dele en felles kolonne eller kolonner. Når det finnes en mange-til-mange-relasjon, kreves en tredje tabell for å representere relasjonen.
Finjustere utformingen
Når du har tabellene, feltene og relasjonene du trenger, bør du opprette og fylle ut tabellene med eksempeldata og prøve å arbeide med informasjonen: opprette spørringer, legge til nye poster og så videre. Når du gjør dette, kan det hende du må legge til en kolonne som du har glemt å sette inn i utformingsfasen, eller du kan ha en tabell som du bør dele opp i to tabeller for å fjerne duplisering.
Se om du kan bruke databasen til å få svarene du ønsker. Opprett grove kladder av skjemaer og rapporter, og se om de viser dataene du forventer. Se etter unødvendig duplisering av data og, når du finner noen, endre utformingen for å eliminere den.
Når du prøver ut den opprinnelige databasen, vil du sannsynligvis oppdage rom for forbedring. Her er noen ting du bør se etter:
-
Har du glemt noen kolonner? I så fall hører informasjonen til i de eksisterende tabellene? Hvis det er informasjon om noe annet, må du kanskje opprette en ny tabell. Opprett en kolonne for hvert informasjonselement du må spore. Hvis informasjonen ikke kan beregnes fra andre kolonner, er det sannsynlig at du trenger en ny kolonne for den.
-
Er noen kolonner unødvendige fordi de kan beregnes fra eksisterende felt? Hvis et informasjonselement kan beregnes fra andre eksisterende kolonner – en rabattert pris beregnet fra utsalgsprisen, er det vanligvis bedre å gjøre nettopp dette, og unngå å opprette en ny kolonne.
-
Skriver du inn duplisert informasjon gjentatte ganger i én av tabellene? I så fall må du sannsynligvis dele tabellen inn i to tabeller som har en én-til-mange-relasjon.
-
Har du tabeller med mange felt, et begrenset antall poster og mange tomme felt i individuelle poster? I så fall bør du tenke på å utforme tabellen på nytt, slik at den har færre felt og flere poster.
-
Har hvert informasjonselement blitt delt inn i de minste nyttige delene? Hvis du trenger å rapportere, sortere, søke eller beregne på et informasjonselement, legger du elementet i en egen kolonne.
-
Inneholder hver kolonne et faktum om tabellens emne? Hvis en kolonne ikke inneholder informasjon om emnet for tabellen, hører den til i en annen tabell.
-
Er alle relasjoner mellom tabeller representert, enten av fellesfelt eller en tredje tabell? Én-til-én og én-til-mange-relasjoner krever vanlige kolonner. Mange-til-mange-relasjoner krever en tredje tabell.
Begrens produkter-tabellen
Anta at hvert produkt i produktsalgsdatabasen faller under en generell kategori, for eksempel drikkevarer, krydder eller sjømat. Produkter-tabellen kan inneholde et felt som viser kategorien for hvert produkt.
La oss si at når du har undersøkt og finjustert utformingen av databasen, bestemmer du deg for å lagre en beskrivelse av kategorien sammen med navnet. Hvis du legger til et felt for kategoribeskrivelse i Produkter-tabellen, må du gjenta hver kategoribeskrivelse for hvert produkt som er under kategorien – dette er ikke en god løsning.
En bedre løsning er å gjøre Kategorier til et nytt emne for databasen å spore, med sin egen tabell og sin egen primærnøkkel. Deretter kan du legge til primærnøkkelen fra Kategorier-tabellen i Produkter-tabellen som en sekundærnøkkel.
Kategori- og produkttabellene har en én-til-mange-relasjon: en kategori kan inneholde mer enn ett produkt, men et produkt kan bare tilhøre én kategori.
Når du ser gjennom tabellstrukturene, må du være på utkikk etter gjentatte grupper. Vurder for eksempel en tabell som inneholder følgende kolonner:
-
Produkt-ID
-
Navn
-
Produkt-ID1
-
Navn1
-
Produkt-ID2
-
Navn 2
-
Produkt-ID3
-
Navn3
Her er hvert produkt en gjentakende gruppe med kolonner som er forskjellig fra de andre, bare ved å legge til et tall på slutten av kolonnenavnet. Når du ser kolonner nummerert på denne måten, bør du gå tilbake til utformingen.
Et slikt design har flere feil. For det første tvinger det deg til å sette en øvre grense på antall produkter. Så snart du overskrider denne grensen, må du legge til en ny gruppe kolonner i tabellstrukturen, som er en viktig administrativ oppgave.
Et annet problem er at de leverandørene som har færre enn maksimalt antall produkter, vil kaste bort litt plass, siden de ekstra kolonnene vil være tomme. Den mest alvorlige feilen med en slik utforming er at det gjør mange oppgaver vanskelige å utføre, for eksempel sortering eller indeksering av tabellen etter produkt-ID eller navn.
Når du ser gjentatte grupper, kan du se gjennom utformingen tett med et øye for å dele tabellen i to. I eksemplet ovenfor er det bedre å bruke to tabeller, én for leverandører og én for produkter, koblet av leverandør-ID.
Bruke normaliseringsreglene
Du kan bruke datanormaliseringsreglene (noen ganger bare kalt normaliseringsregler) som neste trinn i utformingen. Du bruker disse reglene for å se om tabellene er strukturert riktig. Prosessen med å bruke reglene på databaseutformingen kalles normalisering av databasen eller bare normalisering.
Normalisering er mest nyttig når du har representert alle informasjonselementene og har kommet frem til en foreløpig utforming. Tanken er å hjelpe deg med å sikre at du har delt informasjonselementene inn i de riktige tabellene. Det normaliseringen ikke kan gjøre, er å sikre at du har alle de riktige dataelementene til å begynne med.
Du bruker reglene i rekkefølge ved hvert trinn for å sikre at utformingen kommer til et av de «normale skjemaene». Fem normale skjemaer er allment godtatt – den første normale formen gjennom den femte normale formen. Denne artikkelen utvides på de tre første, fordi de er alt som kreves for de fleste databaseutforminger.
Første normale skjema
Første normale skjema sier at i hvert rad- og kolonneskjæringspunkt i tabellen der, finnes det én enkelt verdi, og aldri en liste med verdier. Du kan for eksempel ikke ha et felt kalt Pris der du plasserer mer enn én pris. Hvis du tenker på hvert skjæringspunkt mellom rader og kolonner som en celle, kan hver celle inneholde bare én verdi.
Andre normale skjema
Andre normale skjema krever at hver ikke-nøkkelkolonne er fullstendig avhengig av hele primærnøkkelen, ikke bare på en del av nøkkelen. Denne regelen gjelder når du har en primærnøkkel som består av mer enn én kolonne. Anta for eksempel at du har en tabell som inneholder følgende kolonner, der ordre-ID og produkt-ID utgjør primærnøkkelen:
-
Ordre-ID (primærnøkkel)
-
Produkt-ID (primærnøkkel)
-
Produktnavn
Denne utformingen bryter med andre normale skjema, fordi produktnavnet er avhengig av produkt-ID, men ikke på ordre-ID, så det er ikke avhengig av hele primærnøkkelen. Du må fjerne Produktnavn fra tabellen. Den hører hjemme i en annen tabell (Produkter).
Tredje normalform
Tredje normale form krever at ikke bare alle ikke-nøkkelkolonner er avhengige av hele primærnøkkelen, men at ikke-nøkkelkolonner er uavhengige av hverandre.
En annen måte å si dette på er at hver ikke-nøkkelkolonne må være avhengig av primærnøkkelen og bare primærnøkkelen. Anta for eksempel at du har en tabell som inneholder følgende kolonner:
-
ProductID (primærnøkkel)
-
Navn
-
SRP
-
Diskonto
Anta at rabatten avhenger av den foreslåtte utsalgsprisen (SRP). Denne tabellen bryter med tredje normale skjema fordi en ikke-nøkkelkolonne, Rabatt, avhenger av en annen ikke-nøkkelkolonne, SRP. Kolonneuavhengighet betyr at du skal kunne endre en ikke-nøkkelkolonne uten å påvirke noen annen kolonne. Hvis du endrer en verdi i SRP-feltet, endres rabatten tilsvarende, og bryter dermed denne regelen. I dette tilfellet bør Rabatt flyttes til en annen tabell som er inntastet i SRP.









