
Når du har overført dataene fra Access til SQL Server, har du nå en klient-/serverdatabase som kan være en lokal eller hybrid Azure Cloud-løsning. Uansett er Access nå presentasjonslaget og SQL Server er datalaget. Først er det lurt å tenke gjennom løsningens aspekter, spesielt spørringsytelse, sikkerhet, og forretningskontinuitet, slik at du kan forbedre og skalere databaseløsningen.
For en Access-bruker kan SQL Server- og Azure-dokumentasjonen virke overveldende til å begynne med. Derfor har vi laget en veiledning som forklarer deg de viktigste områdene. Når du er ferdig med denne veiledningen, er du klar til å se nærmere på databaseteknologien og komme i gang med å bruke den.
I denne artikkelen
|
Databasestyring Legge til rette for forretningskontinuitet Håndtering av personvernhensyn |
Spørringer og relatert |
Datatyper |
Diverse |
Legge til rette for forretningskontinuitet
Access-løsningen din bør fungere med minimale avbrytelser, men du har begrensede alternative med en Access-bakdatabase. Sikkerhetskopiering av Access-databasen er avgjørende for å beskytte dataene dine, men det krever at du bruker frakoblet modus. Så har du ikke-planlagt nedetid som skyldes vedlikeholdsoppgraderinger av maskinvare og programvare, nettverks- eller strømbrudd, maskinvarefeil, sikkerhetsbrudd eller cyberangrep. Hvis du vil redusere nedetid og innvirkning på bedriften, kan du sikkerhetskopiere en SQL Server-database mens den er i bruk. I tillegg har SQL Server også strategier for høy tilgjengelighet (HA) og nødgjenoppretting (DR). Disse to kombinerte teknologiene kalles HADR. Hvis du vil ha mer informasjon, kan du se Forretningkontinuitet og databasegjenoppretting og Legge til rette for forretningskontinuitet med SQL Server (e-bok).
Sikkerhetskopiering mens databasen er i bruk
SQL Server har en nettbasert sikkerhetskopieringprosess som kan brukes mens databasen kjører. Du kan utføre en fullstendig sikkerhetskopiering, en delvis sikkerhetskopiering eller en sikkerhetskopering av filen. En sikkerhetskopiering kopierer dataene og transaksjonsloggene for å sikre en fullstendig gjenoppretting. Spesielt i en lokal løsning må du være oppmerksom på forskjellene mellom enkle og fullstendige gjenopprettingsalternativer, og hvordan de påvirker transaksjonsloggveksten. Hvis du vil ha mer informasjon, kan du se Gjenopprettingsmodeller.
De fleste sikkerhetskopieringsoperasjoner starter med én gang, med unntak av filbehandling og redusering av database. Hvis du prøver å opprette eller slette en databasefil mens en sikkerhetskopiering pågår, mislykkes operasjonen. Hvis du vil ha mer informasjon, kan du se Oversikt over sikkerhetskopiering.
HADR
De to vanligste metodene for å oppnå høy tilgjengelighet og forretningskontinuitet er speiling og klynging. SQL Server integrerer speilings- og klyngeteknologi with Always On Failover-klyngeforekomster og Always On-tilgjengelighetsgrupper.
Speiling er en kontinuitetsløsning på databasenivå som støtter direkte failover ved å vedlikeholde en ventedatabase, en fullstendig kopi eller speiling av den aktive databasen på separat maskinvare. Den kan fungere i en synkron (høy sikkerhet) modus, der en innkommende transaksjon sendes til alle servere samtidig, eller i en asynkron (høy ytelse) modus, der en innkommende transaksjon sendes til den aktive databasen og deretter kopieres over til speilingen på et bestemt tidspunkt. Speiling er en løsning på databasenivå og fungerer bare med databaser som bruker den fullstendige gjenopprettingsmodellen.
Klynging er en løsning på servernivå som kombinerer servere til ett enkelt datalager som for brukeren ser ut som én enkelt forekomst. Brukerne kobler seg til forekomsten og trenger ikke å vite hvilken forekomst som er aktiv for øyeblikket. Hvis én eller flere servere må settes i frakoblet modus for vedlikehold, endres ikke brukeropplevelsen. Hver server i klyngen er overvåket av klyngeadministratoren som bruker et livstegn, som oppdager når den aktive serveren i klyngen er frakoblet og prøver å bytte sømløst til neste server i klyngen, selv om det er en variabel tidsforsinkelse når byttet skjer.
Hvis du vil ha mer informasjon, kan du se Always On Failover-klyngeforekomster og Always On-tilgjengelighetsgrupper: en løsning for høy tilgjengelighet og nødgjenoppretting.
Sikkerhet i SQL Server
Selv om du kan beskytte Access-databasen ved hjelp av klareringssenteret og ved å kryptere databasen, har SQL Server mer avanserte sikkerhetsfunksjoner. La oss se på tre muligheter som skiller seg ut for Access-brukeren. Hvis du vil ha mer informasjon, kan du se Sikre SQL Server.
Databasegodkjenning
Det finnes fire godkjenningsmetoder for database i SQL Server, som alle kan spesifiseres i en ODBC-tilkoblingsstreng. Hvis du vil ha mer informasjon, kan du se Koble til eller importere data fra en Azure SQL Server-database. Hver metode har sine fordeler.
Integrert Windows-godkjenning Bruk Windows-legitimasjon for brukergodkjenning, sikkerhetsroller og begrensing av brukere til funksjoner og data. Du kan dra nytte av domenelegitimasjon og enkelt administrere brukerrettigheter i programmet. Angi eventuelt et hovednavn for tjenesten (SPN). Hvis du vil ha mer informasjon, kan du se Velg en godkjenningsmodus.
SQL Server-godkjenning Brukere må koble til med legitimasjonen som er konfigurert i databasen, ved å angi påloggings-ID og passord første gang de åpner databasen i en økt. Hvis du vil ha mer informasjon, kan du se Velg en godkjenningsmodus.
Azure Active Directory integrert godkjenning Koble til Azure SQL Server-databasen ved bruk av Azure Active Directory. Når du har konfigurert Azure Active Directory-godkjenning, kreves ingen ekstra pålogging og passord. Hvis du vil ha mer informasjon, kan du se Koble til SQL Database ved bruk av Azure Active Directory-godkjenning.
Godkjenning av passord for Active Directory Koble med legitimasjon som er konfigurert i Azure Active Directory ved å skrive inn påloggingsnavn og passord. Hvis du vil ha mer informasjon, kan du se Koble til SQL Database ved bruk av Azure Active Directory-godkjenning.
Tips Bruke trusselgjenkjenning til å motta varsler om avvikende databaseaktivitet som indikerer mulige sikkerhetstrusler mot en Azure SQL Server-database. Hvis du vil ha mer informasjon, kan du se trusselgjenkjenning for SQL-database.
Applikasjonssikkerhet
SQL Server har to sikkerhetsfunksjoner på programnivå som du kan dra nytte av med Access.
Dynamisk datamaskering Skjul sensitive opplysninger ved å maskere dem fra brukere som ikke har tilstrekkelige tilgangsrettigheter. Du kan for eksempel maskere personnummer, enten delvis eller fullt ut.
 En delvis datamaske |
 En fullstendig datamaske |
Det finnes flere måter du kan angi en datamaske på, og du kan bruke dem på forskjellige datatyper. Datamaskering er policydrevet på tabell- og kolonnenivå for et definert sett med brukere og brukes i sanntid for spørring. Hvis du vil ha mer informasjon, kan du se Dynamisk datamaskering.
Sikkerhet på radnivå Du kan kontrollere tilgang til spesifikke databaserader med sensitiv informasjon basert på brukeregenskaper, ved å bruke sikkerhet på radnivå. Databasesystemet bruker disse tilgangsbegrensningene, og dette gjør sikkerhetssystemet mer pålitelig og robust.

Det finnes to typer sikkerhetspredikater:
-
Et filterpredikat filtrerer rader fra en spørring. Filteret er gjennomsiktig, og sluttbrukeren er ikke klar over at filtrering skjer.
-
Et blokkpredikat hindrer uautorisert handling og genererer et unntak hvis handlingen ikke kan utføres.
Hvis du vil ha mer informasjon, kan du se Sikkerhet på radnivå.
Beskytte data med kryptering
Beskytt data under lagring, i transitt og i bruk, uten å påvirke databaseytelsen. Hvis du vil ha mer informasjon, kan du se SQL Server-kryptering.
Kryptering under lagring Hvis du vil sikre personlige data mot frakoblede medieangrep på det fysiske lagringslaget, kan du bruke kryptering under lagring, også kalt gjennomsiktig datakryptering (TDE). Dette betyr at dataene er beskyttet selv om de fysiske mediene er stjålet eller fjernet på utilbørlig måte. TDE utfører kryptering og dekryptering i sanntid for databaser, sikkerhetskopier og transaksjonslogger uten at du trenger å endre programmene.
Kryptering i transitt Hvis du vil beskytte deg mot snooping-angrep og MITM-angrep (man-in-the-middle), kan du kryptere data som overføres på tvers av nettverket. SQL Server støtter Transport Layer Security (TLS) 1.2 for svært sikker kommunikasjon. TDS-protokollen (tabelldataflyt) brukes også til å beskytte kommunikasjon over uklarerte nettverk.
Kryptering i bruk på klienten Hvis du vil beskytte personlige data mens de er i bruk, velger du Always Encrypted-funksjonen. Personlige data krypteres og dekrypteres av en driver på klientdatamaskinen uten å avsløre krypteringsnøklene til databasemotoren. Som et resultat er krypterte data bare synlige for personer som er ansvarlige for å administrere disse dataene, og ikke andre brukere med høye tilgangsrettigheter som ikke skal ha tilgang til disse dataene. Avhengig av hvilken type kryptering som er valgt, kan Always Encrypted begrense noe databasefunksjonalitet, som for eksempel søking, gruppering og indeksering av krypterte kolonner.
Håndtering av personvernhensyn
Problemer med personvern er så omfattende at EU har definert juridiske krav gjennom EUs personvernforordning (GDPR). Heldigvis er det en SQL Server-backend som håndterer disse kravene på en god måte. Forestill deg at du skal implementere GDPR i et tretrinns rammeverk.

Trinn 1: Vurdere og håndtere risiko når det gjelder overholdelse av lover og regler
GDPR krever at du identifiserer og lager personlige opplysninger du har i tabeller og filer. Denne informasjonen kan være alt fra et navn, et bilde, en e-postadresse, bankdetaljer, innlegg på nettsteder for sosiale nettverk, medisinsk informasjon eller en IP-adresse.
Et nytt verktøy, SQL Data Discovery and Classification, som er innebygd i SQL Management Studio, hjelper deg med å oppdage, klassifisere, merke og rapportere om sensitive data ved å bruke to metadataattributter til kolonner:
-
Etiketter For å definere følsomhetsnivået til dataene.
-
Informasjonstyper For å gi mer detaljert informasjon om datatypene som er lagret i en kolonne.
En annen søke metode du kan bruke, er fulltekstsøk, som inkluderer bruken av CONTAINS- og FREETEXT-predikater, og verdifastsatte funksjoner på radsettnivå som CONTAINSTABLE og FREETEXTTABLE for bruk med SELECT-uttrykket. Hvis du bruker fulltekstsøk, kan du søke i tabeller for å oppdage ord, ordkombinasjoner eller varianter av et ord, for eksempel synonymer eller bøyningsformer. Hvis du vil ha mer informasjon, kan du se Fulltekstsøk.
Trinn 2: Beskytte personlige opplysninger
GDPR krever at du sikrer personlige opplysninger og begrenser tilgang til dem. I tillegg til standardfremgangsmåten du bruker for å administrere tilgang til nettverket og ressurser, som for eksempel brannmurinnstillinger, kan du bruke SQL Server-sikkerhetsinnstillinger til å kontrollere datatilgang:
-
SQL Server-godkjenning til å administrere brukeridentitet og forhindre uautorisert tilgang.
-
Sikkerhet på radnivå til å begrense tilgangen til rader i en tabell basert på relasjonen mellom brukeren og dataene.
-
Dynamisk datamaskering til å begrense engasjement til personlige data ved å maskere dem fra brukere som ikke er privilegerte.
-
Kryptering for å sikre at personlige data er beskyttet under overføring og lagring og er beskyttet mot kompromittering, inkludert på serversiden.
Hvis du vil ha mer informasjon, kan du se SQL Server-sikkerhet.
Trinn 3: Svare effektivt på forespørsler
GDPR krever at du registrerer oppføringer ved behandling av personlige data og gjør disse oppføringene tilgjengelige for overvåkende myndigheter på forespørsel. Hvis det er problemer med utilsiktet avgivelse av data, kan du bruke beskyttelseskontroller til å håndtere dette raskt. Data må være raskt tilgjengelig når rapportering er nødvendig. GDPR krever for eksempel at et brudd på personlige data blir rapportert til overvåkende myndigheter ikke senere enn 72 timer etter at du har blitt oppmerksom på bruddet.
SQL Server 2017 hjelper deg med rapportering på flere måter:
-
SQL Server-godkjenning hjelper deg med å sikre at det finnes faste oppføringer for tilgang til databaser og behandlingsaktiviteter. SQL Server-godkjenning utfører en finjusteringskontroll som sporer databaseaktiviteter for å hjelpe deg med å forstå og identifisere mulige trusler, mistenkelig misbruk eller sikkerhetsbrudd. Du kan enkelt utføre dataetterforskning.
-
SQL Server tidsbestemte tabeller er brukertabeller som er basert på systemversjoner, og som er utformet for å ha full logg over dataendringer. Du kan bruke disse for enkel rapportering og tidsbasert analyse.
-
SQL Vulnerability Assessment hjelper deg med å oppdage problemer med sikkerhet og tillatelser. Når et problem oppdages, kan du også drille nedover i databaseskanningsrapporter for å finne tiltak for løsning.
Hvis du vil ha mer informasjon, kan du se Create a platform of trust (Skap en plattform du kan stole på) (e-bok) og Journey to GDPR Compliance (Veien mot GPDR-overholdelse).
Opprette øyeblikksbilder av databaser
Et øyeblikksbilde av en database er en skrivebeskyttet, statisk visning av en SQL Server-database på et gitt tidspunkt. Selv om du kan kopiere en Access-databasefil for effektivt å opprette et øyeblikksbilde av en database, har ikke Access en innebygd metodologi slik SQL Server har. Du kan bruke et øyeblikksbilde av en database til å skrive rapporter basert på tidspunktet øyeblikksbildet av databasen ble opprettet. Du kan også bruke et øyeblikksbilde av en database til å vedlikeholde historiske data, for eksempel én for hvert finanskvartal til bruk i rapportering på slutten av en periode. Vi anbefaler følgende gode fremgangsmåter:
-
Gi navn til øyeblikksbildet Hvert øyeblikksbilde av en database krever et unikt databasenavn. Legg til formålet og tidspunktet i navnet, slik at det blir enklere å identifisere. Hvis du for eksempel vil ta et øyeblikksbilde av en AdventureWorks-database tre ganger om dagen, med seks timers mellomrom mellom kl. 06:00 og 18:00, basert på 24-timers klokke, kan du kalle øyeblikksbildene AdventureWorks_øyeblikksbilde_0600, AdventureWorks_øyeblikksbilde_1200 og AdventureWorks_øyeblikksbilde_1800.
-
Begrense antall øyeblikksbilder Hver øyeblikksbilde av en database opprettholdes til det blir uttrykkelig fjernet. Fordi hvert øyeblikksbilde fortsetter å vokse, bør du spare diskplass ved å slette et eldre øyeblikksbilde etter å ha opprettet et nytt øyeblikksbilde. Hvis du for eksempel lager daglige rapporter, må du holde øyeblikksbildet for databasen i 24 timer og deretter fjerne det og erstatte det med en nytt.
-
Koble til det riktige øyeblikksbildet Hvis du vil bruke et øyeblikksbilde av databasen, må Access-frontserveren vite riktig plassering. Når du bytter ut et eksisterende øyeblikksbilde med et nytt, må du omdirigere tilgangen til det nye øyeblikksbildet. Hvis du vil forsikre deg om at du kobler til det riktige øyeblikksbilde for databasen, kan du legge til logikk i Access-frontserveren.
Slik oppretter du et øyeblikksbilde av databasen:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Hvis du vil ha mer informasjon, kan du se Øyeblikksbilde av database (SQL Server).
Samtidighetskontroll
Når mange personer prøver å endre data i en database samtidig, er det en rekke kontroller som er nødvendige, slik at endringer fra én person ikke har negativ innvirkning på endringene gjort av en annen person. Dette kalles samtidighetskontroll, og det finnes to grunnleggende låsstrategier, pessimistisk og optimistisk. Låsing kan hindre brukere i å endre data på en måte som påvirker andre brukere. Låsing bidrar også til å sikre en integritet i databasen, spesielt med spørringer som ellers kan gi uventede resultater. Det finnes viktige forskjeller i måten Access og SQL Server implementerer disse kontrollstrategiene for samtidighet.
I Access er standard låsingsstrategi optimistisk og gir eierskap til låsen til den første personen som prøver å skrive til en post. Access viser dialogboksen Skrivekonflikt til den andre personen som prøver å skrive til den samme posten samtidig. Hvis du vil løse konflikten, kan den andre personen lagre posten og kopiere den til utklippstavlen eller slette endringene.
Du kan også bruke RecordLocks-egenskapen til å endre strategi for samtidighetskontroll. Denne egenskapen har innvirkning på skjemaer, rapporter og spørringer og har tre innstillinger:
-
Ingen låsing Brukerne kan prøve å redigere samme post i et skjema samtidig, men det kan hende at dialogboksen Skrivekonflikt vises. Postene i en rapport er ikke låst mens rapporten forhåndsvises eller skrives ut. Postene i en spørring er ikke låst mens spørringen kjører. Dette er Access-måten å implementere optimistisk lås på.
-
Alle poster Alle poster i den underliggende tabellen eller spørringen er låst mens skjemaet er åpent i skjemavisning eller dataarkvisning, mens rapporten forhåndsvises eller skrives ut, eller mens spørringen kjører. Brukerne kan lese postene under låsing.
-
Redigert post For skjemaer og spørringer låses en side med poster når en bruker begynner å redigere et felt i posten og forblir låst til brukeren flytter til en annen post. Derfor kan en post redigeres av bare én bruker om gangen. Dette er Access-måten å implementere pessimistisk lås på.
Hvis du vil ha mer informasjon, kan du se dialogboksen Skrivekonflikt og RecordLocks-egenskapen.
I SQL Server fungerer samtidighetskontroll på følgende måte:
-
Pessimistisk Når en bruker utfører en handling som fører til at en lås er i bruk, kan ikke andre brukere utføre handlinger som kommer i konflikt med låsen frem til eieren frigir den. Denne samtidighetskontrollen brukes hovedsakelig i miljøer der det er stor fare for datakonflikter.
-
Optimistisk I optimistisk samtidighetskontroll låser ikke brukerne data når de leser dem. Når en bruker oppdaterer data, kontrollerer systemet om en annen bruker endret dataene etter at de ble lest. Hvis en annen bruker har oppdatert dataene, oppstår det en feil. Vanligvis vil brukeren som mottar feilen rulle tilbake transaksjonen og starte på nytt. Denne samtidighetskontrollen brukes hovedsakelig i miljøer der det er liten fare for datakonflikter.
Du kan angi type samtidighetskontroll ved å velge flere nivåer for transaksjonsisolasjon, som definerer beskyttelsesnivået for transaksjonen fra endringer som er foretatt av andre transaksjoner ved bruk av SET TRANSACTION-uttrykket:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Isolasjonsnivå |
Beskrivelse |
|
Les ulagrede |
Transaksjoner er isolert bare nok til å forsikre deg om at fysisk ødelagte data ikke er lest. |
|
Les lagrede |
Transaksjoner kan lese data som tidligere er lest av en annen transaksjon, uten å vente på at den første transaksjonen ble fullført. |
|
Gjentatt lesing |
Lese- og skrivelåser brukes på utvalgte data frem til slutten av transaksjonen, men det kan hende at det forekommer fantomlesinger. |
|
Øyeblikksbilde |
Bruker radversjon for å sørge for lesekonsekvens på transaksjonsnivå. |
|
Serialiseres |
Transaksjoner er fullstendig isolert fra hverandre. |
Hvis du vil ha mer informasjon, kan du se Veiledning for transaksjonslåser og radversjonering.
Forbedre spørringsytelsen
Når du har en Access-direktespørring som fungerer, kan du dra nytte av de avanserte måtene SQL Server kan gjøre spørringen mer effektiv på.
I motsetning til en Access-database gir SQL Server parallelle spørringer for å optimalisere utføring av spørringer og indeksoperasjoner for datamaskiner som har mer enn én mikroprosessor (CPU). Fordi SQL Server kan utføre en spørring eller en indeksoperasjon parallelt med flere systemarbeidstråder, kan operasjonen fullføres raskt og effektivt.
Spørringer er en viktig komponent for å forbedre den generelle ytelsen til databaseløsningen. Feil spørringer kjører på ubestemt tid, det oppstår tidsavbrudd, og de bruker ressurser som for eksempel CPU-er, minne og nettverksbåndbredde. Dette hindrer tilgjengeligheten til viktig bedriftsinformasjon. Selv én feil spørring kan forårsake alvorlige ytelsesproblemer for databasen.
Hvis du vil ha mer informasjon, kan du se Faster querying with SQL Server (Raskere spørring med SQL Server) (e-bok).
Spørringsoptimalisering
Flere verktøy fungerer sammen for å hjelpe deg med å analysere ytelsen til en spørring og forbedre den: Spørringsoptimalisering, utførelsesplaner og spørringslager.
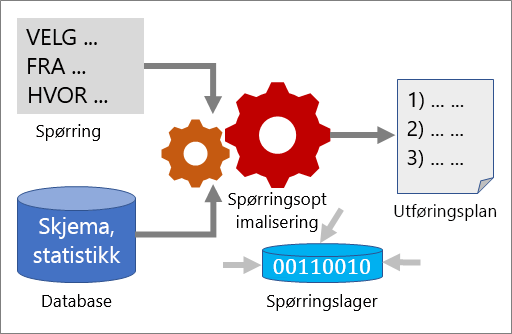
Spørringsoptimalisering
Spørringsoptimalisering er en av de viktigste komponentene i SQL Server. Bruk spørringsoptimalisering til å analysere en spørring og fastslå den mest effektive måten å få tilgang til de nødvendige dataene på. Inndata for spørringsoptimalisering består av spørringen, databaseskjemaet (tabell- og indeksdefinisjoner) og databasestatistikk. Utdataene for spørringsoptimalisering er en utførelsesplan.
Hvis du vil ha mer informasjon, kan du se SQL Server Query Optimizer.
Utførelsesplan
En utførelsesplan er en definisjon som sekvenserer kildetabellene til Access og metodene som brukes til å trekke ut data fra hver tabell. Optimalisering er prosessen med å velge én utførelsesplan fra potensielt mange mulige planer. Hver mulige utførelsesplan har en tilknyttet kostnad når det gjelder mengden databehandlingsressurser som brukes, og spørringsoptimalisering velger planen med minst estimert kostnad.
SQL Server må også justere dynamisk ut fra endrede betingelser i databasen. Regresjoner i utførelsesplaner for spørringer kan ha stor innvirkning på ytelsen. Visse endringer i en database kan føre til at en utførelsesplan enten er ineffektiv eller ugyldig, basert på den nye statusen til databasen. SQL Server oppdager endringene som gjør at en utførelsesplan ikke er gyldig og merker planen som ugyldig.
En ny plan må kompileres på nytt for den neste tilkoblingen som utfører spørringen. Betingelsene som gjør at en plan blir ugyldig, omfatter:
-
Endringer som er gjort i en tabell eller visning som det refereres til i spørringen (ALTER TABLE og ALTER VIEW).
-
Endringer i indekser som brukes av utførelsesplanen.
-
Oppdateringer i statistikk som brukes av utførelsesplanen, genereres enten eksplisitt fra et uttrykk, som for eksempel UPDATE STATISTICS, eller automatisk.
Hvis du vil ha mer informasjon, kan du se Utførelsesplaner.
Spørringslager
Spørringslageret gir innsikt i valg av utførelsesplan og ytelse. Det forenkler feilsøking av ytelse ved at du raskt kan finne ytelsesforskjeller som skyldes endringer i utførelsesplanen. Spørringslager samler inn telemetridata, for eksempel en logg over spørringer, planer, kjøretidsstatistikk og ventestatistikk. Bruk ALTER DATABASE-uttrykket til å implementere spørringslageret:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Hvis du vil ha mer informasjon, kan du se Overvåke ytelse ved bruk av spørringslager.
Automatisk korrigering av plan
Den enkleste måten å forbedre spørringsytelsen på, er med automatisk korrigering av plan, noe som er en funksjon som er tilgjengelig i Azure SQL Database. Det er bare å aktivere funksjonen og la den gjøre jobben sin. Den utfører kontinuerlig overvåking og analyse av utførelsesplan, oppdager problemer med utførelsesplaner og løser automatisk ytelsesproblemer. I bakgrunnen bruker automatisk korrigering av plan en firetrinns strategi for å lære, tilpasse, bekrefte og gjenta.
Hvis du vil ha mer informasjon, kan du se Automatisk justering.
Adaptiv spørringsbehandling
Du kan også få raskere spørringer bare ved å oppgradere til SQL Server 2017, som har en ny funksjon som kalles adaptiv spørringsbehandling. SQL Server tilpasser valg av spørringsplaner basert på kjøretidsegenskaper.
Kardinalitetsestimering beregner hvor mange rader som ble behandlet i hvert trinn i en utførelsesplan. Unøyaktige estimater kan gi tregere svartid, unødvendig ressursutnyttelse (minne, CPU og IU) og redusert gjennomstrømming og samtidighet. Tre teknikker brukes til å tilpasse til egenskaper for programarbeidsbelastning:
-
Tilbakemelding om minnetildeling for satsvis modus Dårlig kardinalitetsestimater kan føre til at spørringer «flyter over til disk» eller tar for mye minne. SQL Server 2017 justerer minnetildeling basert på tilbakemelding om gjennomføring, fjerner overflyt til disk og forbedrer samtidigheten for gjentatte spørringer.
-
Dynamiske sammenføyninger for satsvis modus Dynamiske sammenføyninger velger dynamisk en bedre intern sammenføyningstype (nestede løkkesammenføyninger, flettesammenføyninger eller nummererte sammenføyninger) under kjøretid, basert på faktiske inndatarader. Dermed kan en plan dynamisk bytte til en bedre sammenføyningsstrategi under kjøringen.
-
Innfelt utførelse Tabellverdier med flere uttrykk behandles tradisjonelt som en svart boks ved hjelp av spørringsbehandling. SQL Server 2017 kan bedre anslå antall rader som kan forbedre nedstrømsoperasjoner.
Du kan gjøre arbeidsbelastninger automatisk kvalifisert for dynamisk spørringsbehandling ved å aktivere et kompatibilitetsnivå på 140 for databasen:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Hvis du vil ha mer informasjon, kan du se Intelligent spørringsbehandling i SQL-databaser.
Måter å spørre på
I SQL Server er det flere måter du kan spørre på, og hver av dem har sine fordeler. Du bør kjenne til dem, slik at du kan gjøre det riktige valget for din Access-løsning. Den beste måten å opprette TSQL-spørringene dine på er å redigere og teste dem interaktivt ved hjelp av SQL Server Management Studio (SSMS) Transact-SQL Editor, som har IntelliSense for å hjelpe deg å velge riktige nøkkelord og se etter syntaksfeil.
Visninger
I SQL Server er en visning som en virtuell tabell der visningsdataene kommer fra én eller flere tabeller eller andre visninger. Visninger refereres imidlertid på samme måte som tabeller i spørringer. Visninger kan skjule kompleksiteten til spørringer og bidra til å beskytte data ved å begrense settet med rader og kolonner. Her er et eksempel på en enkel visning:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Hvis du vil ha optimal ytelse og redigere visningsresultatene, kan du opprette en indeksert visning, som fortsatt er i databasen som en tabell, har tildelt plass, og kan bli forespurt som en hvilken som helst tabell. Hvis du vil bruke den i Access, kan du koble til visningen på samme måte som du kobler til en tabell. Her er et eksempel på en indeksert visning:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Det finnes imidlertid begrensinger. Du kan ikke oppdatere data hvis mer enn én basistabell er påvirket, eller visningen inneholder mengdefunksjoner eller en DISTINCT-setning. Hvis SQL Server returnerer en feilmelding som sier at den ikke vet hvilken post du skal slette, må du kanskje legge til en sletteutløser i visningen. Du kan ikke bruke ORDER BY-setningen som du kan med en Access-spørring.
Hvis du vil ha mer informasjon, kan du se Visninger og Opprette indekserte visninger.
Lagrede prosedyrer
En lagret prosedyre er en gruppe med en eller flere TSQL-setninger som bruker inndataparametere, returnerer utdataparametere og angir suksess eller feil med en statusverdi. De fungerer som et mellomliggende lag mellom Access-frontserveren og SQL Server-backend. Lagrede prosedyrer kan være så enkle som et SELECT-uttrykk eller så omfattende som et program. Her er et eksempel:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Når du bruker en lagret prosedyre i Access, returnerer den vanligvis et resultatsett tilbake til et skjema eller en rapport. Det kan imidlertid utføre andre handlinger som ikke returnerer resultater, som for eksempel DDL- eller DML-setninger. Når du bruker en direktespørring, må du passe på at du angir egenskapen Returner poster på riktig måte.
Hvis du vil ha mer informasjon, kan du se Lagrede prosedyrer.
Vanlige tabelluttrykk
Et vanlig tabelluttrykk (CTE) er som en midlertidig tabell som genererer et navngitt resultatsett. Den finnes bare for kjøringen av én spørring eller ett DML-uttrykk. En CTE er laget i samme kodelinje som SELECT-uttrykket eller DML-uttrykket som bruker den, mens oppretting og bruk av midlertidig tabell eller visning vanligvis er en prosess med to trinn. Her er et eksempel:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
En CTE har flere fordeler, inkludert følgende:
-
Fordi CTE-er er midlertidige, trenger du ikke å opprette dem som permanente databaseobjekter, som for eksempel visninger.
-
Du kan referere til samme CTE mer enn én gang i en spørring eller DML-uttrykket og gjøre koden lettere å administrere.
-
Du kan bruke spørringer som refererer til en CTE, til å definere en markør.
Hvis du vil ha mer informasjon, kan du se Vanlig tabelluttrykk: WITH.
Brukerdefinerte funksjoner
En brukerdefinert funksjon (UDF) kan utføre spørringer og beregninger og returnerer enten skalaverdier eller dataresultatsett. De er som funksjoner i programmeringsspråk som godtar parametere, utfører en handling, for eksempel en kompleks beregning, og returnerer resultatet av den handlingen som en verdi. Her er et eksempel:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
En UDF har visse begrensninger. Den kan for eksempel ikke bruke bestemte systemfunksjoner som ikke er deterministiske, utføre DML- eller DDL-uttrykk eller utføre dynamiske SQL-spørringer.
Hvis du vil ha mer informasjon, kan du se Brukerdefinerte funksjoner.
Legge til nøkler og indekser
Uansett hvilket databasesystem du bruker, fungerer nøkler og indekser sammen.
Nøkler
Kontroller at du oppretter primærnøkler for hver tabell og sekundærnøkler for hver relatert tabell i SQL Server. Den tilsvarende funksjonen i SQL Server til datatypen Access AutoNumber er IDENTITY-egenskapen, som kan brukes til å opprette nøkkelverdier. Når du bruker denne egenskapen på en hvilken som helst numerisk kolonne, blir den skrivebeskyttet og vedlikeholdt av databasesystemet. Når du setter inn en post i en tabell som inneholder en IDENTITY-kolonne, øker systemet automatisk verdien for denne kolonnen med 1 og starter fra 1, men du kan kontrollere disse verdiene med argumenter.
Hvis du vil ha mer informasjon, kan du se CREATE TABLE, IDENTITY (egenskap).
Indekser
Utvalget av indekser avhenger som alltid av forholdet mellom spørringshastighet og oppdateringskostnad. I Access har du én indekstype, men i SQL Server har du tolv. Heldigvis kan du bruke spørringsoptimalisering til å velge den mest effektive indeksen på en pålitelig måte. Og i Azure SQL kan du bruke automatisk indeksbehandling, en funksjon i automatisk justering, som anbefaler at du legger til eller fjerner indekser. I motsetning til i Access må du opprette dine egne indekser for sekundærnøkler i SQL Server. Du kan også opprette indekser på en indeksert visning for å forbedre ytelsen til spørringer. Ulempen ved en indeksert visning er at det øker belastningen når du endrer data i visningens grunntabeller, fordi visningen også må oppdateres. Hvis du vil ha mer informasjon, kan du se Veiledning for SQL Server-indeksarkitektur og -design og Indekser.
Utføre transaksjoner
Det er vanskelig å utføre en nettbasert transaksjonsprosess (Online Transaction Process, OLTP) når du bruker Access, men det er forholdsvis enkelt med SQL Server. En transaksjon er én enkelt enhet med arbeid som utfører alle dataendringer når den er vellykket, men som tilbakestiller endringene når den mislykkes. En transaksjon må ha fire egenskaper, som ofte kalles ACID:
-
Atomisitet En transaksjon må være en atomisk arbeidsenhet, der enten alle dataendringer utføres, eller ingen.
-
Konsekvens Når en transaksjon er ferdig, må alle data forbli i en konsekvent tilstand. Dette betyr at alle regler for dataintegritet brukes.
-
Isolasjon Endringer gjort av samtidige transaksjoner er isolert fra den gjeldende transaksjonen.
-
Holdbarhet Når en transaksjon er fullført, er endringene permanente selv om det oppstår en systemfeil.
Du kan bruke en transaksjon til å sikre garantert dataintegritet, som for eksempel kontantuttak eller automatisk lønnsinnskudd. Du kan utføre eksplisitte, implisitte eller satsvise transaksjoner. Her er to TSQL-eksempler:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Hvis du vil ha mer informasjon, kan du se Transaksjoner.
Bruke begrensninger og utløsere
Alle databaser har måter å opprettholde dataintegritet på.
Begrensninger
I Access kan du fremtvinge referanseintegritet i en tabellrelasjon via sekundærnøkkel/primærnøkkel-par, gjennomgripende oppdateringer og slettinger og valideringsregler. Hvis du vil ha mer informasjon, kan du se Veiledning for tabellrelasjoner og Begrense inndata ved å bruke valideringsregler.
I SQL Server bruker du UNIQUE- og CHECK-begrensningene, som er databaseobjekter som fremtvinger dataintegritet i SQL Server-tabeller. Hvis du vil validere at en verdi er gyldig i en annen tabell, kan du bruke en sekundærnøkkelbegrensning. Hvis du vil validere at en verdi i en kolonnen er innenfor et spesifikt område, bruker du en CHECK-begrensning. Disse objektene er den første forsvarslinjen og er utformet for å fungere effektivt. Hvis du vil ha mer informasjon, kan du se UNIQUE- og CHECK-begrensninger.
Utløsere
Access har ikke databaseutløsere. Du kan bruke utløsere til å fremtvinge komplekse regler for dataintegritet i SQL Server, og for å kjøre denne forretningslogikken på serveren. En databaseutløser er en lagret prosedyre som kjører når bestemte handlinger skjer i en database. Utløseren er en hendelse, for eksempel å legge til eller slette en post i en tabell, som starter og kjører den lagrede prosedyren. Selv om Access-databaser kan sikre referanseintegritet når en bruker prøver å oppdatere eller slette data, har SQL Server et avansert sett med utløsere. Du kan for eksempel programmere en utløser til å slette poster samtidig og sikre dataintegritet. Du kan også legge til utløsere i tabeller og visninger.
Hvis du vil ha mer informasjon, kan du se Utløsere – DML, Utløsere – DDL og Utforme en T-SQL-utløser.
Bruk beregnede kolonner
I Access oppretter du en kalkulert kolonne ved å legge den til i en spørring og bygge et uttrykk, for eksempel:
Extended Price: [Quantity] * [Unit Price]
I SQL Server kalles den tilsvarende funksjonen en beregnet kolonne, som er en virtuell kolonne som ikke er lagret på en fysisk måte i tabellen, med mindre kolonnen er merket som fast (PERSISTED). I likhet med en kalkulert kolonne bruker en beregnet kolonne data fra andre kolonner i et uttrykk. Hvis du vil opprette en beregnet kolonne, kan du legge den til i en tabell. Eksempel:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Hvis du vil ha mer informasjon, kan du se Angi beregnede kolonner i en tabell.
Tidsangivelse av data
Noen ganger kan du legge til et tabellfelt for å registrere en tidsangivelse når en post er opprettet, slik at du kan logge dataregistreringen. I Access kan du ganske enkelt opprette en datokolonne med standardverdien for =Now(). Hvis du vil registrere en dato eller et klokkeslett i SQL Server, kan du bruke datatypen datetime2 med standardverdien SYSDATETIME().
Obs! Unngå å blande sammen ROWVERSION med å legge til et tidsstempel i dataene dine. Tidsstempelet for nøkkelord er et synonym for ROWVERSION i SQL Server, men du bør bruke nøkkelordet ROWVERSION. I SQL Server er ROWVERSION en datatype som bruker automatisk genererte, unike binære tall i en database, og brukes vanligvis som en mekanisme for versjonsstempling av tabellrader. Datypen ROWVERSION er imidlertid bare et økende nummer, og den beholder ikke en dato eller et klokkeslett og er ikke utformet for å tidsstemple en rad.
Hvis du vil ha mer informasjon, kan du se ROWVERSION. Hvis du vil ha mer informasjon om hvordan du bruker ROWVERSION til å minimere postkonflikter, kan du se Overføre en Access-database til SQL Server.
Behandle store objekter
I Access administrerer du ustrukturerte data, for eksempel filer, foto og bilder, ved å bruke datatypen Vedlegg. Strukturerte data i SQL Server kalles også en BLOB (Binary Large Object), og det finnes flere måter å arbeide med dem på:
FILESTREAM Bruker datatypen varbinary(max) til å lagre de ustrukturerte dataene i filsystemet i stedet for i databasen. Hvis du vil ha mer informasjon, kan du se Tilgang til FILESTREAM-data med Transact-SQL.
FileTable Lagrer BLOB-er i bestemte tabeller kalt FileTables, og gir kompatibilitet med Windows-programmer som om de er lagret i filsystemet og uten å gjøre noen endringer i klientprogrammene. FileTable krever bruk av FILESTREAM. Hvis du vil ha mer informasjon, kan du se FileTables.
Eksternt BLOB-lager (RBS) Lagrer binære store objekter (BLOB-er) i lagerløsninger i stedet for direkte på serveren. Dette sparer plass og reduserer maskinvareressurser. Hvis du vil ha mer informasjon, kan du se Binary Large Object (BLOB)-data.
Arbeide med hierarkiske data
Selv om relasjonsdatabaser, som for eksempel Access, er svært fleksible, er det å arbeide med hierarkiske relasjoner et unntak og krever ofte komplekse SQL-uttrykk eller kode. Eksempler på hierarkiske data omfatter: en organisasjonsstruktur, et filsystem, en klassifikasjon av språkvilkår og en graf med koblinger mellom nettsider. SQL Server har en innebygd hierarchyid-datatype og et sett med hierarkiske funksjoner som enkelt kan lagre, spørre og behandle hierarkiske data.
Hvis du vil ha mer informasjon, kan du se Hierarkiske data og Opplæring: Bruke hierarchyid-datatypen.
Manipulere JSON-tekst
JavaScript Object Notation (JSON) er en nettbasert tjeneste som bruker lesbar tekst til å overføre data som attributt/verdi-par i asynkron nettleser/server-kommunikasjon. Eksempel:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Access har ikke innebygde JSON-data som kan leses, men i SQL Server kan du glatte ut lagring, indeks, spørring og trekke ut JSON-data. Du kan konvertere og lagre JSON-tekst i en tabell eller formatere data som JSON-tekst. Det kan for eksempel hende at du vil formatere resultatene av spørringen som JSON for en app eller legge til JSON-datastrukturer i rader og kolonner.
Obs! JSON støttes ikke i VBA. Som et alternativ kan du bruke XML i VBA ved hjelp av MSXML-biblioteket.
Hvis du vil ha mer informasjon, kan du se JSON data i SQL Server.
Ressurser
Nå passer det godt å lære mer om SQL Server og Transact SQL (TSQL). Som du har sett, er mange funksjoner de samme som i Access, men det er også funksjoner som Access ikke har. Her er noen opplæringsressurser som hjelper deg å utforske enda mer:
|
Ressurs |
Beskrivelse |
|
Videobasert kurs |
|
|
Opplæring i SQL Server 2017 |
|
|
Praktisk opplæring for Azure |
|
|
Bli en ekspert |
|
|
Hovedlandingsside |
|
|
Hjelpeinformasjon |
|
|
Hjelpeinformasjon |
|
|
The essential guide to data in the cloud (Den grunnleggende veiledningen til data i skyen) (e-bok) |
Oversikt over skyen |
|
En visuell oversikt over nye funksjoner |
|
|
Et sammendrag av funksjoner etter versjon |
|
|
Last ned SQL Server Express 2017 |
|
|
Last ned eksempeldatabaser |









