
ここでは、Microsoft Excel の LINEST 関数の構文および使用法について説明します。 回帰分析のグラフ化および実行の詳細については、[参照] セクションのリンク先を参照してください。
説明
LINEST 関数は、"最小二乗法" を使って指定したデータに最もよく適合する直線を算出し、この直線を記述する配列を返すことによって直線の補正項を計算します。 LINEST 関数を他の関数と共に使用して、多項式近似、対数近似、指数近似、べき級数をはじめとする、不明なパラメーター内で線形近似を示す他の種類のモデルの統計を計算することもできます。 この関数は値の配列を返すため、配列数式として入力する必要があります。 方法については、この記事の「使用例」の後に示します。
直線は次の方程式で表されます。
y = mx + b
または
y = m1x1 + m2x2 + ... + b
これは、x の値が複数の範囲にある場合に適用されます (ここで、従属変数 y は独立変数 x の関数です)。 m の値はそれぞれの x の値に対応する係数であり、b は定数です。 y、x、および m がベクトル (1 次元配列) であり得ることに注意してください。 LINEST 関数が返す配列は、{mn,mn-1,...,m1,b} となります。 また、回帰直線の補正項も追加情報として返されます。
書式
LINEST(既知の y, [既知の x], [定数], [補正])
LINEST 関数の書式には、次の引数があります。
構文
-
既知の y 必ず指定します。 既にわかっている y の値の系列であり、y = mx + b という関係が成り立ちます。
-
"既知の y" の配列が 1 つの列に入力されている場合、"既知の x" の各列はそれぞれ異なる変数であると見なされます。
-
"既知の y" の配列が 1 つの行に入力されている場合、"既知の x" の各行はそれぞれ異なる変数であると見なされます。
-
-
既知の x 省略可能です。 既にわかっている x の値の系列であり、y = mx + b という関係が成り立ちます。
-
"既知の x" の配列には、1 つまたは複数の変数の系列を指定できます。 変数の系列が 1 つである場合、既知の y と既知の x は、それぞれの次元が同じであれば、どのような形の範囲であってもかまいません。 変数の系列が複数である場合、既知の y はベクトル (高さが 1 行、または幅が 1 列のセル範囲) でなければなりません。
-
既知の x を省略すると、既知の y と同じサイズの {1,2,3...} という配列を指定したと見なされます。
-
-
定数 省略可能です。 定数 b を 0 にするかどうかを論理値で指定します。
-
定数 を TRUE に設定するか省略すると、b の値も計算されます。
-
"定数" に FALSE を指定すると、b の値が 0 に設定され、y = mx となるように m の値が調整されます。
-
-
補正 省略可能です。 回帰直線の補正項を追加情報として返すかどうかを論理値で指定します。
-
統計 が TRUE の場合、LINEST は追加の回帰統計を返します。その結果、返される配列は {mn,mn-1,...,m1,b です。sen,sen-1,...,se1,seb;r2,sey;F,df;ssreg,ssresid}.
-
"補正"にFALSEを指定するか省略すると、m 係数と定数 b のみが返されます。
次のような回帰直線の補正項が追加情報として返されます。
-
|
補正項 |
説明 |
|---|---|
|
se1,se2,...,sen |
係数 m1,m2,...,mn に対する標準誤差の値です。 |
|
seb |
定数 b に対する標準誤差の値です ("定数" が FALSE の場合、seb = #N/A となります)。 |
|
r2 |
決定係数。 推定値と実際の y 値、および 0 から 1 までの値の範囲を比較します。 1 の場合、サンプルには完全な相関関係があります。推定 y 値と実際の y 値には違いはありません。 もう一方の極端な場合、決定係数が 0 の場合、回帰式は y 値を予測するのに役立ちません。 2 の計算方法については、このトピックの「解説」を参照してください。 |
|
sey |
予測される y の値に対する標準誤差です。 |
|
F |
F 補正項または F 観測値。 F 補正項を利用すると、独立変数と従属変数の間で観察された関係が偶然によるものかどうかを判定できます。 |
|
df |
自由度です。 自由度を利用すると、統計表の中で F の臨界値を見つけるのに役立ちます。 統計表の中で見つけた値と、LINEST 関数が返す F 補正項を比較すると、モデルの信頼性の度合いを決めることができます。 df の計算方法については、後の「解説」を参照してください。 下記の「使用例 4」は、F と df の使い方を示しています。 |
|
ssreg |
回帰の平方和です。 |
|
ssresid |
残余の平方和です。 ssreg と ssresid の計算方法については、後の「解説」を参照してください。 |
次の図は、回帰直線の追加の補正項が返される順序を示します。

解説
-
傾きと y 切片を使って任意の直線を記述できます。
スロープ (m):
多くの場合、m と書かれた線の傾きを見つけるには、行の 2 つの点 (x1,y1) と (x2,y2) を取ります。傾きは (y2 - y1)/(x2 - x1) と等しくなります。Y インターセプト (b):
線の y 切片は、多くの場合、b と書き込まれますが、線が y 軸と交差する位置の y の値です。直線の方程式は y = mx + b で表されます。 m と b の値がわかれば、y または x の値をこの方程式に代入して、直線上の任意の点の座標を計算できます。 この計算に、TREND 関数を使用することもできます。
-
独立変数 x が 1 つしかわからないときは、次の数式を使用すると、傾きと y 切片を計算することができます。
斜面:
=INDEX(LINEST(known_y,known_x),1)Y インターセプト:
=INDEX(LINEST(known_y,known_x),2) -
LINEST 関数で計算した直線の精度は、指定したデータのばらつきによって決まります。 データの分布がより直線に近ければ、LINEST 関数のモデルの精度はそれだけ向上します。 LINEST 関数では、データに最もよく合う直線を見つけるために最小二乗法を使用しています。 独立変数 x の値が 1 つしかわからないときは、次の数式を使って m と b の値が計算されます。
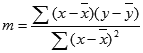
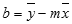
ここで、x は標本平均 "AVERAGE(既知の x)"、y は標本平均 "AVERAGE(既知の y)" です。
-
Line-and curve-fitting 関数 LINEST と LOGEST では、データに適合する最適な直線または指数曲線を計算できます。 ただし、2 つの結果のうち、データに最適な結果を決定する必要があります。 直線の TREND(known_y,known_x)、指数曲線の GROWTH(known_y,known_x) を計算できます。 これらの関数は、 new_xの 引数を指定せずに、実際のデータ ポイントでその線または曲線に沿って予測された y 値の配列を返します。 その後、予測値と実際の値を比較できます。 視覚的な比較のために、両方のグラフを作成することもできます。
-
回帰分析では、直線上の各点ごとに、予測される y の値と実際の y の値との平方差が計算されます。 このようにして計算した平方差の合計を "残余の平方和" (ssresid) と呼びます。 次に、"総平方和" (sstotal) が計算されます。 "定数" に TRUE を指定するか省略すると、総平方和は、実際の y の値と y の平均値の平方差の合計となります。 "定数" に FALSE を指定すると、総平方和は、(個々の y の値から y の平均値を引いたものではなく) 実際の y の値の平方和となります。 回帰の平方和 ssreg は、ssreg = sstotal - ssresid として計算されます。 残差平方和が小さい方が、平方和の合計と比較して、決定係数の値が大きいほど、r2 は、回帰分析に起因する数式が変数間の関係をどの程度説明しているかを示す指標です。 r2 の値は ssreg/sstotal と等しくなります。
-
場合によっては、1 つ以上の X 列 (Y と X が列にあると仮定) に、他の X 列が存在する場合に追加の予測値がない場合があります。 言い換えると、1 つ以上の X 列を削除すると、同じように正確な予測 Y 値が発生する可能性があります。 その場合、これらの冗長 X 列は回帰モデルから省略する必要があります。 冗長 X 列は、冗長でない X 列の倍数の合計として表すことができるため、この現象は "共線性" と呼ばれます。 LINEST 関数は共線性をチェックし、重複する X 列を識別するときに回帰モデルから削除します。 削除された X 列は、 LINEST 出力で、0 se 値に加えて 0 個の係数を持つものとして認識できます。 1 つ以上の列が冗長として削除された場合、df は予測目的で実際に使用される X 列の数に依存するため、df は影響を受けます。 df の計算の詳細については、 例 4 を参照してください。 冗長 X 列が削除されるために df が変更された場合、sey と F の値も影響を受けます。 共線性は、実際には比較的まれである必要があります。 ただし、発生する可能性が高いケースの 1 つは、一部の X 列に、実験の対象が特定のグループのメンバーであるかどうかを示すインジケーターとして 0 と 1 の値しか含まれていない場合です。 const = TRUE または を省略した場合、LINEST 関数は実質的に、インターセプトをモデル化するために、1 つの値すべてを含む追加の X 列を挿入します。 各サブジェクトに 1 (男性の場合は 1、そうでない場合は 0) があり、女性の場合は各サブジェクトに 1、そうでない場合は 0 の列がある場合、この後者の列は冗長になります。これは、 LINEST 関数によって追加されたすべての値の追加列のエントリから "男性インジケーター" 列のエントリを減算することによって取得できるためです。
-
df の値は、共線性のためにモデルから X 列が削除されない場合、次のように計算されます。 known_x と const = TRUE の k 列がある場合、または省略された場合は、df = n – k – 1 です。 const = FALSE の場合、df = n - k。 どちらの場合も、共線性のために削除された各 X 列は、df の値を 1 ずつ増やします。
-
"既知の x" などで引数に配列定数を指定するとき、同じ行の値を区切るには半角のコンマ (,) を使い、各行を区切るには半角のセミコロン (;) を使います。 区切り記号は、地域設定によって異なる場合があります。
-
回帰方程式によって予測計算された y の値が、方程式を決定するときに使用した y の値の範囲では、適切な値にならない場合があります。
-
LINEST 関数の基になるアルゴリズムは、SLOPE 関数や INTERCEPT 関数の基になるアルゴリズムとは異なります。 そのため、データが不定で共線性がある場合に、結果が異なることがあります。 たとえば、"既知の y" 引数のデータ要素が 0、"既知の x" 引数のデータ要素が 1 の場合、次のような動作になります。
-
LINEST 関数では値 0 が返されます。 "LINEST" のアルゴリズムでは、共線性があるデータに対して適切な結果を返すようになっており、この場合は少なくとも 1 つの答えが見つかります。
-
SLOPE 関数と INTERCEPT 関数では、エラー #DIV/0! が返されます。 SLOPE 関数と INTERCEPT 関数のアルゴリズムは唯一の答えを見つけるようになっており、この場合は複数の答えがあり得ます。
-
-
LOGEST を使用して他の種類の回帰分析の統計を計算することに加えて、LINEST を使用すると、x 変数と y 変数の関数を LINEST の x 系列と y 系列として入力することによって、他の一連の回帰分析を計算できます。 例として、次の数式を参照してください。
=LINEST(yvalues, xvalues^COLUMN($A:$C))
この数式では、単一列の x 値と y 値を使用して、次の形式の立方体 (3 次多項式) の近似値を計算できます。
y = m1*x + m2*x^2 + m3*x^3 + b
この式を調整することによって、他の種類の回帰分析を計算できますが、出力値およびその他の統計値の調整が必要になる場合もあります。
-
LINEST 関数から返される F 検定の値は、FTEST 関数から返される F 検定の値と異なります。 LINEST 関数は F 補正項を返し、FTEST 関数は確率を返します。
使用例
使用例 1: 傾きと y 切片
次の表のサンプル データをコピーし、新しい Excel ワークシートのセル A1 に貼り付けます。 数式を選択して、F2 キーを押し、さらに Enter キーを押すと、結果が表示されます。 必要に応じて、列幅を調整してすべてのデータを表示してください。
|
既知の y |
既知の x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
結果 (傾き) |
結果 (y 切片) |
|
2 |
1 |
|
数式 (セル A7:B7 に含まれる配列数式) |
|
|
=LINEST(A2:A5,B2:B5,,FALSE) |
使用例 2: 変数の線形回帰
次の表のサンプル データをコピーし、新しい Excel ワークシートのセル A1 に貼り付けます。 数式を選択して、F2 キーを押し、さらに Enter キーを押すと、結果が表示されます。 必要に応じて、列幅を調整してすべてのデータを表示してください。
|
月 |
売上 |
|---|---|
|
1 |
¥310,000 |
|
2 |
¥450,000 |
|
3 |
¥440,000 |
|
4 |
¥540,000 |
|
5 |
¥750,000 |
|
6 |
¥810,000 |
|
数式 |
結果 |
|
=SUM(LINEST(B1:B6, A1:A6)*{9,1}) |
¥1,100,000 |
|
1 ~ 6 月の売上に基づいて 9 番目の月の売上の推定値を計算します。 |
使用例 3: 多変数の線形回帰
次の表のサンプル データをコピーし、新しい Excel ワークシートのセル A1 に貼り付けます。 数式を選択して、F2 キーを押し、さらに Enter キーを押すと、結果が表示されます。 必要に応じて、列幅を調整してすべてのデータを表示してください。
|
床面積 (x1) |
オフィスの数 (x2) |
入口の数 (x3) |
築年数 (x4) |
評価額 (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
¥14,200,000 |
|
2333 |
2 |
2 |
12 |
¥14,400,000 |
|
2356 |
3 |
1.5 |
33 |
¥15,100,000 |
|
2379 |
3 |
2 |
43 |
¥15,000,000 |
|
2402 |
2 |
3 |
53 |
¥13,900,000 |
|
2425 |
4 |
2 |
23 |
¥16,900,000 |
|
2448 |
2 |
1.5 |
99 |
¥12,600,000 |
|
2471 |
2 |
2 |
34 |
¥14,290,000 |
|
2494 |
3 |
3 |
23 |
¥16,300,000 |
|
2517 |
4 |
4 |
55 |
¥16,900,000 |
|
2540 |
2 |
3 |
22 |
¥14,900,000 |
|
-234.2371645 |
||||
|
13.26801148 |
||||
|
0.996747993 |
||||
|
459.7536742 |
||||
|
1732393319 |
||||
|
数式 (A19 で入力された動的配列式) |
||||
|
=LINEST(E2:E12,A2:D12,TRUE,TRUE) |
例 4 - F 統計と r2 統計の使用
前の例では、決定係数 r2 は 0.99675 です ( LINEST の出力のセル A17 を参照)。これは、独立変数と販売価格の間の強い関係を示します。 F 補正項を利用すると、このように高い r2 の値が偶然の結果であるかどうかを調べることができます。
実際には変数間に相関関係など存在せず、選択した 11 のオフィス ビルがたまたま特異な例であり、強い相関関係を示す統計分析をもたらしたと仮定します。 このように、相関関係が存在すると誤って結論づける確率を "アルファ" と称します。
LINEST 関数からの出力の F 値と df 値を使用して、発生する可能性が高い F 値が発生する可能性を評価できます。 F は、パブリッシュされた F 分布テーブルの重要な値と比較することも、Excel の FDIST 関数を使用して、大きな F 値が偶然発生する確率を計算することもできます。 適切な F 分布には、v1 と v2 の自由度があります。 n がデータ ポイントの数で const = TRUE または省略された場合、v1 = n – df – 1 および v2 = df。 (const = FALSE の場合、v1 = n – df および v2 = df。 FDIST 関数は、FDIST(F,v1,v2) という構文を使用して、偶然より高い F 値が発生する確率を返します。 この例では、df = 6 (セル B18) と F = 459.753674 (セル A18) です。
α値 0.05、v1 = 11 - 6 - 1 = 4、および v2 = 6 とすると、F の臨界値は 4.53 です。 459.753674 という F 値は 4.53 を大幅に超えているので、このように大きな F 値が偶然に発生する可能性は非常に低くなります。 α = 0.05 のとき、F 値が臨界値 4.53 を超えると、既知の y と既知の x の間に関連がないという仮定は成り立ちません。 Excel の FDIST 関数を使用して、この高い F 値が偶然に発生する確率を計算できます。 FDIST(459.753674, 4, 6) = 1.37E-7 となり、これは非常に低い確率です。 F 確率分布表の臨界値と比較するか、Excel の FDIST 関数を使用すると、オフィス ビルの評価額を予測するうえで回帰方程式が有効かどうかを判断できます。 ここで、v1 および v2 には、前の段落で計算した正しい値を使用することが重要です。
使用例 5: t 補正項の計算
もう 1 つの仮説検定を使うと、直線の傾きを表すそれぞれの係数が「使用例 3」のオフィス ビルの評価額の予測に有効であるかどうかを調べることができます。 たとえば、築年数の係数が統計的に有意であるかどうかを調べるには、-234.24 (築後年数の係数) を 13.268 (セル A15 に表示されている築後年数の係数についての標準誤差の予測値) で除算します。 次の数式により、t の観測値を計算できます。
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
t の絶対値が十分に大きい場合は、「使用例 3」のオフィス ビルの評価額を予測するうえで、直線の傾きを表す係数が有効であると判断できます。 次に、4 t の観測値の絶対値の一覧を示します。
統計学の教科書の一覧表を参照すると、自由度 6、アルファ 0.05 として、t の臨界値 (両側) は 2.447 であることがわかります。 この臨界値は、Excel の TINV 関数を使用して計算することもできます。 TINV(0.05,6) = 2.447 とします。 t の絶対値は 17.7 で臨界値の 2.447 よりも大きいため、オフィス ビルの評価額を予測するとき、築後年数が重要な変数であることがわかります。 その他の各独立変数についても、同様の方法で統計的な有意性を調べることができます。 次に、それぞれの独立変数に対する t の観測値の一覧を示します。
|
変数 |
t の観測値 |
|---|---|
|
床面積 |
5.1 |
|
オフィスの数 |
31.3 |
|
入口の数 |
4.8 |
|
築年数 |
17.7 |
これらの値の絶対値はすべて 2.447 よりも大きくなるため、回帰方程式のすべての変数が、オフィス ビルの評価額を予測するうえで有効であることを確認できます。









