
2013 Excelでは、数百万行を含むデータ モデルを作成し、これらのモデルに対して強力なデータ分析を実行できます。 データ モデルは、同じワークブックで任意の数のピボットテーブル、チャート、Power View の可視化をサポートする、PowerPivot アドインを使用して作成することも、使用せずに作成することもできます。
注: この記事では、Excel 2013 のデータ モデルについて説明します。 ただし、Excel 2013 で導入された同じデータ モデリング機能と Power Pivot 機能は、Excel 2016。 これらのバージョンのバージョンの間には実質的にほとんど違いExcel。
Excel では大量のデータ モデルを簡単に構築できますが、いくつかの理由で作成できない場合もあります。 まず、複数のテーブルと列を含む大きなモデルはほとんどの分析の限界を超えるもので、厄介なフィールド リストが作成されます。 次に、貴重なメモリを消費する大きなモデルは、他のアプリケーションに悪影響を及ぼし、同じシステム リソースを共有していることが報告されます。 最後に、 Microsoft 365では、SharePoint Online と Excel Web App の両方で、Excel ファイルのサイズを 10 MB に制限します。 膨大な数の行を含むワークブックのデータ モデルでは、すぐに 10 MB の制限に達してしまいます。 詳細については、「データ モデルの仕様と制限」を参照してください。
この記事では、作業が容易でメモリの使用量が少ない、緊密に構成されたモデルの構築方法について説明します。 効率的なモデル設計のベスト プラクティスを学ぶ時間を取って、Excel 2013、 Microsoft 365 SharePoint Online、 Office Online Server、または SharePoint 2013 で表示する場合でも、作成して使用するモデルに対する道のりを見過ごします。
Workbook Size Optimizer の実行も検討してください。 Excel ブックを分析し、可能な場合は圧縮してくれるツールです。 Workbook Size Optimizer は、こちらからダウンロードできます。
この記事の内容
比率とメモリ内分析エンジンの比較
Excel のデータ モデルは、メモリ内分析エンジンを使用してデータをメモリに格納します。 このエンジンは強力な圧縮技術を搭載していて、記憶域の要件を削減し、記憶域の元のサイズの分数となるまで、一連の結果を縮小します。
概して、同じデータの元の状態に比べて、データ モデルは 7 倍から 10 倍小さくなります。 たとえば、SQL Server データベースから 7 MB のデータをインポートする場合、Excel では 1 MB 以下となります。 圧縮の程度は、実際には主にそれぞれの列の一意の値の数によって決まります。 一意の値が多い場合は、保存するのにより多くのメモリが必要になります。
圧縮と一意の値について話す理由 メモリ使用量を最小限に抑える効率的なモデルを構築する方法はすべて圧縮の最大化であり、最も簡単な方法は、特にそれらの列に多数の一意の値が含まれる場合に、本当に必要ない列を削除する方法です。
注: 個別の列によって、記憶域要件の違いは大きなものになります。 場合によっては、一意の値が多い 1 つの列よりも、一意の値が少ない複数の列のほうが好ましい場合もあります。 Datetime 最適化のセクションで、この手法の詳細を説明します。
メモリ使用量を減らすには、列の数を少なくする
メモリにとって最も効率的な列は、最初にインポートされることはありません。 効率的なモデルを構築する場合は、それぞれの列に注目して、実行する分析でそれが役立つがどうかを検討します。 役立たない場合またはわからない場合、その列は使用しません。 必要な場合は、常に新しい列を追加できます。
常に実行すべき列の 2 つの例
最初の例は、データ ウェアハウスからのデータに関連するものです。 データ ウェアハウスでは、ウェアハウスにデータを読み込んで更新する ETL プロセスのアイテムがあるのが一般的です。 「作成日」、[更新日」、「ETL 実行」のような列は、データが読み込まれたときに作成されます。 これらの列はいずれもモデルでは不要で、データをインポートするときには選択を解除する必要があります。
2 番目の例には、ファクト テーブルのインポート時の主キー列の省略が含まれます。
ファクト テーブルなどの多くのテーブルには、主キーがあります。 顧客、従業員、または販売データなどが含まれるほとんどのテーブルでは、テーブルの主キーをモデル内での関係を作成するのに使用します。
ファクト テーブルの場合は異なります。 ファクト テーブルでは、主キーはそれぞれの行を一意に識別するのに使用されます。 正規化の目的で必要であっても、それらの列を分析のみに使用するか、テーブルの関係の確立にのみ使用する場合は、データ モデルでは役に立ちません。 そのため、ファクト テーブルからインポートする場合、その主キーは含めません。 ファクト テーブルの主キーはモデルのスペースを大量に消費しますが、関係の作成には使用できないため、そのメリットはありません。
注: データ ウェアハウスと多次元データベースでは、主に数値データで構成される大きなテーブルは、"ファクト テーブル" と呼ばれることが多い。 ファクト テーブルには、通常、組織単位、製品、市場セグメント、地理的地域などと集計および調整された売上およびコスト データ ポイントなどのビジネス パフォーマンスデータやトランザクション データが含まれます。 ビジネス データを含むファクト テーブルの列、または他のテーブルに格納されているデータを相互参照するために使用できる列はすべて、データ分析をサポートするためにモデルに含める必要があります。 除外する列は、ファクト テーブルの主キー列であり、ファクト テーブルにのみ存在する一意の値で構成され、それ以外の場所には存在しません。 ファクト テーブルは非常に大きいので、モデルの効率の最大の向上の一部は、ファクト テーブルから行または列を除外する方法から得られたものになります。
不要な列の除外方法
効率的なモデルに含まれる列は使用するワークブックで実際に必要となる列のみです。 モデルに含める列を指定したい場合は、Excel の [データのインポート] ダイアログ ボックスではなく、Power Pivot アドインでテーブルのインポート ウィザードを使用してデータをインポートする必要があります。
テーブルのインポート ウィザードを起動したら、インポートするデータを選びます。
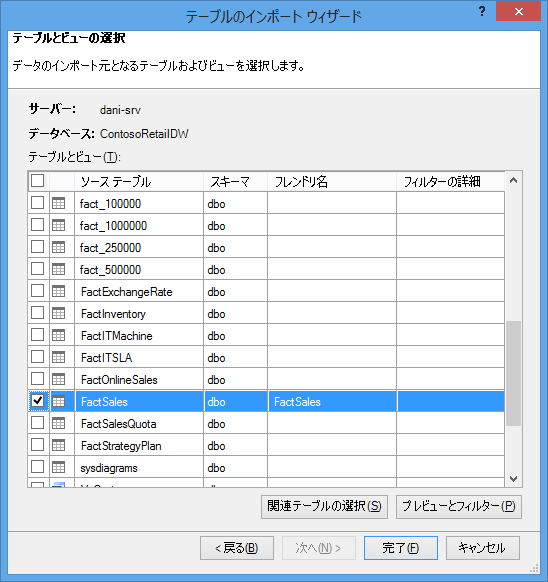
それぞれのテーブルで、[プレビュー] と [フィルター] をクリックして、本当に必要なテーブルの一部を選びます。 分析が必要であるかどうかを考慮した後で、最初にすべての列の選択を解除してから、必要な列をチェックすることをお勧めします。
![テーブルのインポート ウィザードの [プレビュー] ウィンドウ](https://support.content.office.net/ja-jp/media/f726888f-edd1-4021-a257-bbd77e4597f2.png)
必要な行をフィルター処理する場合
会社のデータベースには数多くのテーブルがあり、データ ウェアハウスには長期間にわたる履歴データが蓄積されています。 また、関心のあるテーブルには、特定の分析には必要のない地域のビジネス情報が含まれている場合もあります。
テーブルのインポート ウィザードを使用して、履歴データまたは関連のないデータを除外し、モデルに大きなスペースを確保します。 次の画像は、今年のデータのみを含む行のみを取得して不要な履歴データを除外するのに使用する日付フィルターです。
![テーブルのインポート ウィザードの [フィルター] ウィンドウ](https://support.content.office.net/ja-jp/media/68643daf-6b4c-41a0-a1c0-cd22f6ab198a.png)
列が必要な場合に、その容量を削減する方法
列をさらに圧縮して整理するのに使用できる方法がいくつかあります。 圧縮に影響を与える列の唯一の特性は、一意の値の数であることを思い出してください。 このセクションでは、いくつかの列を変更して、一意の値の数を削減する方法を学習します。
[Datetime] 列の変更
多くの場合、[Datetime] 列は多くのスペースをとります。 この日付タイプに必要な記憶域を削減する方法がいくつかあります。 この手法は列をどのように使用するのかと、SQL クエリ構築の快適さのレベルによって変わります。
[Datetime] 列には日付部分と時刻部分があります。 列が自分にとって必要であるかどうかを考えるときに、同じく [Datetime] 列に複数の時刻部分が必要であるかどうかも考えます。
-
時間は必要ですか。
-
時間のレベルで時刻が必要ですか。 分は必要ですか。 秒は必要ですか。 ミリ秒は必要ですか。
-
複数の [Datetime] 列の差異を計算するため、またはデータを年別、月別、四半期別などで集計するために、それを必要としていますか。
それぞれの質問に答えていくことで、[Datetime] 列を処理するオプションが決まります。
これらの解決方法のすべてで、SQL クエリの変更が必要になります。 クエリの変更を簡単に行うためには、すべてのテーブルで少なくとも 1 つの列を除外する必要があります。 列を除外することで、クエリの構造を省略された形式 (SELECT *) から、変更がはるかに容易な完全修飾列名を含む SELECT ステートメントに変更します。
作成されたクエリを見てみましよう。 [表のプロパティ] ダイアログ ボックスでクエリ エディターに切り替えて、それぞれのテーブルの現在の SQL クエリを表示できます。
![[表のプロパティ] コマンドが表示された [Power Pivot] ウィンドウ](https://support.content.office.net/ja-jp/media/656839be-6720-46d9-b418-733b1e82ae18.png)
[表のプロパティ] で、[クエリ エディター] を選びます。
![[表のプロパティ] ダイアログ ボックスでクエリ エディターを開く](https://support.content.office.net/ja-jp/media/c415a01d-9213-429f-b949-3f006710a759.png)
クエリ エディターには、テーブルの入力に使用される SQL クエリが表示されます。 インポート中に列を除外した場合は、クエリに完全修飾列名が含まれます。
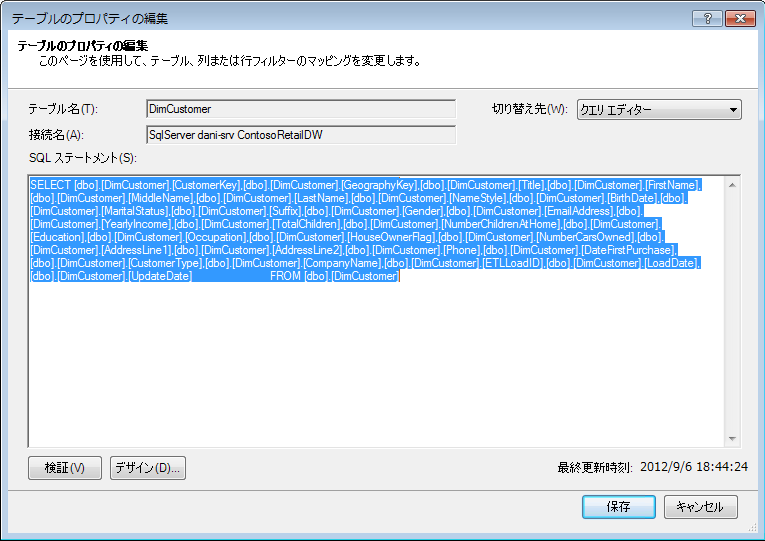
|
一方、列をすべて選択した状態またはフィルターを適用せずにテーブル全体をインポートした場合は、クエリが「Select * from (から選択)」で表示されます。これは変更がより困難です。
|
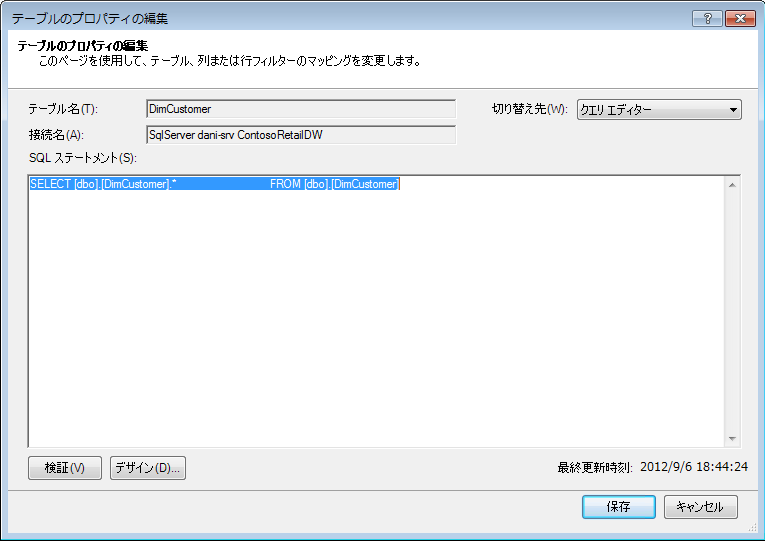
SQL クエリの変更
これで、クエリを見つける方法がわかりました。さらにクエリを変更して、モデルのサイズを小さくしていきます。
-
通貨または小数点付きデータを含む列の場合、小数点以下を必要としない場合は、次の構文を使用して小数点以下を除外します。
"SELECT ROUND([Decimal_column_name],0)... .”
セントが必要な場合で、セントの小数点以下が不要な場合は、0 を 2 に置き換えます。 負の数字を使用する場合は、一の位、十の位、百の位に丸めることができます。
-
dbo.Bigtable.[Date Time] という名前の [Datetime] 列があり、時刻部分が不要な場合は、この構文を使用して時刻を除外します。
“SELECT CAST (dbo.Bigtable.[Date time] as date) AS [Date time]) “
-
dbo.Bigtable.[Date Time] という名前の [Datetime] 列があり、日付部分と時刻部分が必要な場合は、SQL クエリで単一の [Datetime] 列の代わりに複数の [Datetime] 列を使用します。
“SELECT CAST (dbo.Bigtable.[Date Time] as date ) AS [Date Time],
datepart(hh, dbo.Bigtable.[Date Time]) as [Date Time Hours],
datepart(mi, dbo.Bigtable.[Date Time]) as [Date Time Minutes],
datepart(ss, dbo.Bigtable.[Date Time]) as [Date Time Seconds],
datepart(ms, dbo.Bigtable.[Date Time]) as [Date Time Milliseconds]”
必要なだけの列を使用して、個別の列の必要な部分を保存します。
-
時間と分が必要な場合で、それらをまとめて 1 つの時刻列として参照する場合は、次の構文を使用します。
Timefromparts(datepart(hh, dbo.Bigtable.[Date Time]), datepart(mm, dbo.Bigtable.[Date Time])) as [Date Time HourMinute]
-
[Start Time] と [End Time] のような 2 つの [Datetime] 列があり、それらの時刻の差 [Duration] という列に秒単位で必要としている場合は、リストから両方の列を削除して、次の構文を追加します。
“datediff(ss,[Start Date],[End Date]) as [Duration]”
ss の代わりに ms をキーワードとして使用すると、期間がミリ秒単位で得られます。
列の代わりに DAX 計算メジャーを使用する
これまでに DAX 記述言語を使用して作業したことがある場合は、モデル内の他の列に基づいて、既に計算された列を使用して新しい列が作成されることを知っていると思います。計算メジャーはモデルで定義されていますが、ピボットテーブルまたは他のレポートで使用された場合のみ評価されます。
メモリ節約の技法は、正規の列または計算された列を計算メジャーで置き換えることにあります。 典型的な例として、単価、数量、合計などがあります。 3 つの列のすべてがある場合は、DAX を使用して合計を計算することで、2 つの列だけを維持してスペースを節約できます。
どの 2 つの列を維持すべきでしょうか。
上記の例では、数量と単価を維持します。 これら 2 つの列は、合計よりも値の数が少なくなっています。 合計を計算するには、次のように計算メジャーを追加します。
“TotalSales:=sumx(‘Sales Table’,’Sales Table’[Unit Price]*’Sales Table’[Quantity])”
計算された列は、モデルで両方のスペースを使用した正規の列のように表示されます。 一方で、計算メジャーは簡易計算されてスペースを使用しません。
結論
この記事では、メモリをより効率的に使用できるモデルを構築するための、いくつかの方法について説明しました。 ファイルのサイズとデータ モデルで必要となるメモリ要件を減らすための方法とは、全体的な列と行の数を減らし、それぞれの列の一意の値の数を減らすことにあります。 下記に、説明した技法をまとめます。
-
列を減らすことは、言うまでもなくスペース節約のベストの方法です。 本当に必要な列を判断します。
-
テーブルで、列を削除して計算メジャーに置き換えることが可能な場合もあります。
-
テーブルにすべての行が必要なわけではありません。 テーブルのインポート ウィザードで行を除外することができます。
-
一般に、単一の列を複数の個別部分に分割することは、列の一意の値を減らす有効な方法となります。 各部分にはそれぞれ少数の一意の値があり、それらを合算した合計は元の列をまとめたものよりも小さくなります。
-
多くの場合、個別部分はレポートのスライサーとして使用する必要もあります。 部分から、時間、分、秒のような階層を適宜作成できます。
-
多くの場合、列には必要としているもの以上の情報が含まれています。 たとえば、列に小数点が格納されているが、すべての小数点以下を非表示にする書式設定を適用したとします。 小数点以下を丸めることは、数値列のサイズを減らすのにとても効果的です。
これで、ブックのサイズを小さくするために実行できる操作が完了しました。また、ブック サイズ オプティマイザーの実行も検討してください。 Excel ブックを分析し、可能な場合は圧縮してくれるツールです。 Workbook Size Optimizer は、こちらからダウンロードできます。









