
Dopo aver eseguito la migrazione dei dati da Access a SQL Server, è disponibile un database client/server, che potrebbe essere una soluzione locale o ibrida nel cloud di Azure. In entrambi i casi, Access è ora il livello di presentazione e SQL Server è il livello dei dati. Ora è il momento giusto per riconsiderare gli aspetti della soluzione, soprattutto le prestazioni delle query, la sicurezza e la continuità aziendale, per poter migliorare e ridimensionare la soluzione di database.
La documentazione di SQL Server e Azure può a tutta prima scoraggiare un utente di Access. È per questo motivo che è necessaria una guida che illustri le caratteristiche più importanti per l'utente. Al termine della panoramica, sarà possibile esplorare i progressi della tecnologia di database e proseguire nel percorso di apprendimento.
Contenuto dell'articolo
|
Gestione dei database |
Query e argomenti correlati |
Tipi di dati |
Varie |
Stimolare la continuità aziendale
Per la soluzione di Access, è consigliabile mantenerne l'operatività con interruzioni minime, ma le opzioni con un database back-end di Access sono limitate. Il backup del database di Access è essenziale per proteggere i dati, ma occorre tenere offline gli utenti. C'è poi da considerare il tempo di inattività non pianificato causato da aggiornamenti di manutenzione hardware e/o software, interruzioni di rete o di alimentazione, errori hardware, violazioni della sicurezza o anche attacchi cibernetici. Per ridurre al minimo i tempi di inattività e l'impatto sull'azienda, è possibile eseguire il backup di un database di SQL Server mentre è in uso. In più, SQL Server offre anche strategie per la disponibilità elevata e il ripristino di emergenza. Queste due tecnologie combinate sono denominate HADR. Per altre informazioni, vedere Continuità aziendale e recupero del database e Stimolare la continuità aziendale con SQL Server (e-book).
Backup in uso
SQL Server usa un processo di backup online che può verificarsi durante l'esecuzione del database. È possibile eseguire un backup completo, un backup parziale o una copia di backup del file. Una copia di backup copia i dati e i log delle transazioni per garantire un'operazione di ripristino completa. Soprattutto in una soluzione locale, è importante tenere presenti le differenze tra opzioni di ripristino semplici e complete e il modo in cui influiscono sulla crescita del log delle transazioni. Per altre informazioni, vedere Modelli di recupero.
La maggior parte delle operazioni di backup avviene subito, ad eccezione delle operazioni di gestione dei file e di compattazione database. Al contrario, se si prova a creare o eliminare un file di database mentre è in corso un'operazione di backup, l'operazione non riesce. Per altre informazioni, vedere Panoramica del backup.
HADR
Le due tecniche più comuni per raggiungere la disponibilità elevata e la continuità aziendale sono il mirroring e il clustering. SQL Server integra la tecnologia di mirroring e clustering con le "istanze del cluster di failover Always On" e i "gruppi di disponibilità Always On".
Il mirroring è una soluzione di continuità a livello di database che supporta il failover quasi immediato, mantenendo un database in standby, una copia completa o mirror del database attivo su hardware distinto. Può operare in modalità sincrona (protezione elevata), in cui una transazione in ingresso viene impegnata in tutti i server contemporaneamente, oppure in modalità asincrona (prestazioni elevate), in cui una transazione in ingresso viene impegnata nel database attivo e quindi, in un punto predefinito, copiata nel mirror. Il mirroring è una soluzione a livello di database e funziona solo con database che usano il modello di ripristino completo.
Il clustering è una soluzione a livello di server che combina i server in un unico spazio di archiviazione dati che all'utente compare come una singola istanza. Gli utenti si connettono all'istanza e non devono mai sapere quale server nell'istanza è effettivamente attivo. Se si verifica un errore oppure un server deve essere messo offline per la manutenzione, l'esperienza utente non cambia. Ogni server nel cluster viene monitorato dalla gestione cluster con un heartbeat, in modo da rilevare quando il server attivo nel cluster è offline e prova a passare facilmente al server successivo nel cluster, anche se è presente un intervallo di tempo variabile per il passaggio.
Per altre informazioni, vedere Istanze del cluster di failover Always On e Gruppi di disponibilità Always On: una soluzione per la disponibilità elevata e il ripristino di emergenza.
Sicurezza di SQL Server
Anche se è possibile proteggere il database di Access usando il Centro protezione e crittografando il database, SQL Server offre funzionalità di sicurezza più avanzate. Esaminiamo tre funzionalità disponibili per l'utente di Access. Per altre informazioni, vedere Sicurezza di SQL Server.
Autenticazione del database
In SQL Server sono disponibili quattro metodi di autenticazione del database, ognuno dei quali può essere specificato in una stringa di connessione ODBC. Per altre informazioni, vedere Collegare o importare dati da un server di database SQL di Azure. Ogni metodo presenta vantaggi specifici.
Autenticazione integrata di Windows Usare le credenziali di Windows per la convalida degli utenti, i ruoli di sicurezza e la limitazione degli utenti alle funzionalità e ai dati. È possibile usare le credenziali di dominio e gestire facilmente i diritti degli utenti nell'applicazione. Facoltativamente, immettere un nome dell'entità servizio (SPN). Per altre informazioni, vedere Scegliere una modalità di autenticazione.
Autenticazione di SQL Server Gli utenti devono connettersi con le credenziali configurate nel database immettendo ID di accesso e password al primo accesso al database in una sessione. Per altre informazioni, vedere Scegliere una modalità di autenticazione.
Autenticazione integrata di Azure Active Directory Connettersi al database del server SQL di Azure usando Azure Active Directory. Dopo aver configurato l'autenticazione di Azure Active Directory, non sono necessarie altre informazioni di accesso e password. Per altre informazioni, vedere Usare l'autenticazione di Azure Active Directory per connettersi a un database SQL.
Autenticazione con password di Active Directory Connettersi con credenziali configurate in Azure Active Directory immettendo il nome di accesso e la password. Per altre informazioni, vedere Usare l'autenticazione di Azure Active Directory per connettersi a un database SQL.
Suggerimento Usare il Rilevamento delle minacce per ricevere avvisi riguardanti azioni anomale del database che indicano potenziali minacce per la sicurezza di un database del server SQL di Azure. Per altre informazioni, vedere Rilevamento delle minacce al database SQL.
Sicurezza delle applicazioni
SQL Server offre due funzionalità di sicurezza a livello di applicazione, che è possibile sfruttare con Access.
Dynamic Data Masking Nasconde mascherandole le informazioni riservate agli utenti non privilegiati. Ad esempio, è possibile mascherare i numeri di previdenza sociale, sia parzialmente che integralmente.
 Una maschera dati parziale |
 Una maschera dati totale |
È possibile definire una maschera di dati in diversi modi ed applicarli a tipi di dati diversi. La maschera dati è basata sui criteri a livello di tabella e colonna per un gruppo di utenti definito e viene applicata in tempo reale alle query. Per altre informazioni, vedere Mascheramento dati dinamici.
Sicurezza a livello di riga È possibile controllare l'accesso a specifiche righe di database con informazioni riservate in base alle caratteristiche dell'utente usando la sicurezza a livello di riga. Il sistema di database applica queste restrizioni di accesso, rendendo il sistema di sicurezza più affidabile e solido.

Sono disponibili due tipi di predicati di sicurezza:
-
Il predicato di filtro filtra le righe da una query. Il filtro è trasparente e l'utente finale non è al corrente della presenza di filtri.
-
Il predicato di blocco impedisce le azioni non autorizzate e genera un'eccezione se non è possibile eseguire l'azione.
Per altre informazioni, vedere Sicurezza a livello di riga.
Protezione dei dati con crittografia
È possibile proteggere i dati inattivi, in transito e in uso senza influire sulle prestazioni del database. Per altre informazioni, vedere Crittografia di SQL Server.
Crittografia dei dati inattivi Per proteggere i dati personali dagli attacchi dei supporti offline al livello di archiviazione fisico, usare la crittografia dei dati inattivi, nota anche come TDE (Transparent Data Encryption, crittografia dati trasparente). Ciò significa che i dati sono protetti anche se il supporto fisico viene rubato o non è stato adeguatamente smaltito. La tecnologia TDE esegue la crittografia e la decrittografia in tempo reale di database, backup e log delle transazioni senza richiedere alcuna modifica delle applicazioni.
Crittografia in transito Per proteggersi da spionaggio e "attacchi man-in-the-middle", è possibile crittografare i dati trasmessi in rete. SQL Server supporta TLS (Transport Layer Security) 1.2 per comunicazioni altamente protette. Viene anche usato il protocollo TDS (Tabular Data Stream) per proteggere le comunicazioni su reti non attendibili.
Crittografia in uso nel client Per proteggere i dati personali in uso, la funzionalità giusta è "Always Encrypted". I dati personali sono crittografati e decrittografati da un driver nel computer client senza rivelare le chiavi di crittografia al motore di database. Di conseguenza, i dati crittografati sono visibili solo alle persone responsabili della relativa gestione e non agli utenti con privilegi elevati che non devono accedervi. A seconda del tipo di crittografia selezionato, Always Encrypted potrebbe limitare alcune funzionalità di database, ad esempio la ricerca, il raggruppamento e l'indicizzazione delle colonne crittografate.
Gestire i problemi di privacy
I problemi relativi alla privacy sono così diffusi che l'Unione europea ha definito i requisiti legali attraverso il Regolamento generale sulla protezione dei dati (GDPR). Fortunatamente, un back-end di SQL Server è ideale per rispondere a questi requisiti. L'implementazione del GDPR richiede tre passaggi.

Passaggio 1: Valutare e gestire i rischi di conformità
Il GDPR richiede di identificare e inventariare le informazioni personali presenti in tabelle e file. Queste informazioni possono essere qualsiasi cosa, da un nome, una foto, un indirizzo di posta elettronica, dettagli bancari, post sui siti Web di social networking, informazioni mediche o anche un indirizzo IP.
Un nuovo strumento, Individuazione dati e classificazione di SQL, incorporato in SQL Server Management Studio, consente di individuare, classificare, etichettare e segnalare i dati riservati applicando due attributi di metadati alle colonne:
-
Etichette Per definire la riservatezza dei dati.
-
Tipi di informazioni Per fornire una granularità aggiuntiva sui tipi di dati archiviati in una colonna.
Un altro meccanismo di individuazione che può essere usato è la ricerca full-text, che include l'uso dei predicati CONTAINS e FREETEXT e delle funzioni con valori di set di righe come CONTAINSTABLE e FREETEXTTABLE per l'uso con l'istruzione SELECT. Se si usa la ricerca full-text, è possibile eseguire ricerche nelle tabelle per individuare parole, combinazioni di parole o variazioni di una parola, come sinonimi o forme flessive. Per altre informazioni, vedere Ricerca full-text.
Passaggio 2: Proteggere le informazioni personali
Il GDPR richiede di proteggere le informazioni personali e limitarne l'accesso. Oltre ai passaggi standard necessari per gestire l'accesso alla rete e alle risorse, ad esempio le impostazioni del firewall, è possibile usare le funzionalità di sicurezza di SQL Server per controllare l'accesso ai dati:
-
Autenticazione di SQL Server per gestire le identità degli utenti e impedire l'accesso non autorizzato.
-
Sicurezza a livello di riga per limitare l'accesso alle righe in una tabella in base alla relazione tra l'utente e i dati.
-
Maschera dati dinamica per limitare l'esposizione dei dati personali mascherandoli agli utenti non privilegiati.
-
Crittografia per assicurare che i dati personali siano protetti durante la trasmissione e l'archiviazione e dalla violazione, anche sul lato server.
Per altre informazioni, vedere Sicurezza di SQL Server.
Passaggio 3: Rispondere in modo efficiente alle richieste
Il GDPR richiede di mantenere i record di trattamento dei dati personali e di renderli disponibili alle autorità di vigilanza su richiesta. Se si verificano problemi come il rilascio accidentale di dati, i controlli di protezione consentono di rispondere rapidamente. I dati devono essere subito disponibili per la creazione di report. Ad esempio, il GDPR richiede che la violazione dei dati personali venga segnalata all'autorità di vigilanza entro 72 ore dal momento in cui se ne è venuti a conoscenza.
SQL Server 2017 supporta la creazione di report in vari modi:
-
SQL Server Audit consente di verificare che siano presenti record permanenti di accesso al database e attività di elaborazione. Esegue un controllo con granularità fine che tiene traccia delle attività di database per comprendere e identificare potenziali minacce, presunti abusi o violazioni della sicurezza. È possibile eseguire facilmente analisi dei dati.
-
Le tabelle temporali di SQL Server sono tabelle di utenti con versioni di sistema che consentono di mantenere una cronologia completa dei dati. È possibile usarle per semplificare la creazione di report e l'analisi temporizzata.
-
Valutazione della vulnerabilità di SQL consente di rilevare i problemi di sicurezza e autorizzazioni. Se viene rilevato un problema, è anche possibile eseguire il drill-down dei report di analisi del database per scoprire come agire per risolverlo.
Per altre informazioni, vedere l'e-book Create a platform of trust e Journey to GDPR Compliance.
Creare snapshot di database
Uno snapshot del database è una visualizzazione statica di sola lettura di un database di SQL Server in un certo momento. Anche se è possibile copiare un file di database di Access per creare in modo efficace uno snapshot del database, Access non ha una metodologia predefinita come SQL Server. È possibile usare uno snapshot del database per la scrittura di report in base ai dati al momento della creazione di snapshot del database. È anche possibile usare uno snapshot di database per gestire i dati cronologici, ad esempio uno per ogni trimestre finanziario che si usa per eseguire il roll up dei report di fine periodo. Ecco le procedure consigliate:
-
Assegnare un nome allo snapshot Ogni snapshot del database richiede un nome di database univoco. Aggiungere lo scopo e l'intervallo di tempo al nome per semplificare l'identificazione. Ad esempio, per eseguire lo snapshot del database AdventureWorks tre volte al giorno a intervalli di 6 ore tra le 6.00 e le 18.00 in base a un orologio di 24 ore, denominarli AdventureWorks_snapshot_0600, AdventureWorks_snapshot_1200 e AdventureWorks_snapshot_1800.
-
Limitare il numero di snapshot Ogni snapshot del database persiste finché non viene eliminato esplicitamente. Poiché ogni snapshot continuerà a essere incrementato, è consigliabile risparmiare spazio su disco eliminando uno snapshot meno recente dopo aver creato un nuovo snapshot. Ad esempio, se si effettuano report quotidiani, mantenere lo snapshot del database per 24 ore e quindi eliminarlo e sostituirlo con uno nuovo.
-
Connettersi allo snapshot corretto Per usare uno snapshot del database, è necessario che il front-end di Access conosca il percorso corretto. Quando si sostituisce un nuovo snapshot con uno esistente, è necessario reindirizzare Access al nuovo snapshot. Aggiungere la logica al front-end di Access per assicurarsi che ci si connetta al database corretto.
Ecco come creare uno snapshot del database:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Per altre informazioni, vedere Snapshot del database (SQL Server).
Controllo della concorrenza
Se molti utenti provano a modificare contemporaneamente i dati di un database, è necessario un sistema di controlli, in modo che le modifiche apportate da una persona non influiscano negativamente su quelle di altre persone. Questa operazione è detta controllo della concorrenza e comporta due strategie di blocco di base: pessimistico e ottimistico. Il blocco può impedire agli utenti di modificare i dati in un modo che influisca sugli altri utenti. Il blocco consente inoltre di garantire l'integrità del database, soprattutto con le query che altrimenti potrebbero generare risultati imprevisti. Esistono importanti differenze nel modo in cui Access e SQL Server implementano queste strategie di controllo della concorrenza.
In Access, la strategia di blocco predefinita è ottimistica e assegna la proprietà del blocco al primo utente che prova a scrivere in un record. Access visualizza la finestra di dialogo Conflitto di scrittura all'altro utente che prova a scrivere nello stesso record contemporaneamente. Per risolvere il conflitto, l'altro utente può salvare il record, copiarlo negli Appunti o eliminare le modifiche.
È anche possibile usare la proprietà RecordLocks per cambiare la strategia di controllo della concorrenza. Questa proprietà influisce su maschere, report e query e include tre impostazioni:
-
Nessun blocco In una maschera, gli utenti possono provare a modificare contemporaneamente lo stesso record, ma potrebbe comparire la finestra di dialogo Conflitto di scrittura. In un report, i record non vengono bloccati durante la visualizzazione dell'anteprima o la stampa del report. In una query, i record non vengono bloccati durante l'esecuzione della query. Si tratta del modo in cui Access implementa il blocco ottimistico.
-
Tutti i record Tutti i record nella tabella o nella query sottostante vengono bloccati mentre la maschera è aperta in visualizzazione Maschera o visualizzazione Foglio dati, durante la visualizzazione dell'anteprima o la stampa del report o durante l'esecuzione della query. Gli utenti possono leggere i record durante il blocco.
-
Record modificati Per maschere e query, una pagina di record viene bloccata non appena un utente inizia a modificare qualsiasi campo nel record e rimane bloccata finché l'utente non passa a un altro record. Di conseguenza, un record può essere modificato da un solo utente alla volta. Si tratta del modo in cui Access implementa il blocco pessimistico.
Per altre informazioni, vedere Finestra di dialogo Conflitto di scrittura e Proprietà RecordLocks.
In SQL Server il controllo della concorrenza funziona in questo modo:
-
Pessimistica Dopo che un utente esegue un'azione che causa l'applicazione di un blocco, gli altri utenti non possono eseguire azioni che comportano conflitti con il blocco finché il proprietario non lo rimuove. Questo controllo di concorrenza viene usato principalmente negli ambienti in cui è presente un elevato conflitto dei dati.
-
Ottimistica Nel controllo della concorrenza ottimistica gli utenti non bloccano i dati quando li leggono. Quando un utente aggiorna i dati, il sistema verifica se un altro utente ha modificato i dati dopo che sono stati letti. Se un altro utente ha aggiornato i dati, viene generato un errore. In genere, l'utente che riceve l'errore ripristina la transazione e ricomincia. Questo controllo di concorrenza viene usato principalmente negli ambienti in cui è presente un basso conflitto dei dati.
È possibile specificare il tipo di controllo di concorrenza selezionando diversi livelli di isolamento delle transazioni, che definiscono il livello di protezione per la transazione in base alle modifiche apportate da altre transazioni con l'istruzione SET TRANSACTION:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Livello di isolamento |
Descrizione |
|
Lettura senza commit |
Le transazioni sono isolate solo per evitare che i dati fisicamente danneggiati vengano letti. |
|
Lettura commit |
Le transazioni possono leggere i dati letti in precedenza da un'altra transazione senza attendere il completamento della prima transazione. |
|
Lettura ripetibile |
I blocchi di lettura e scrittura si applicano a dati selezionati fino al termine della transazione, ma possono verificarsi letture fittizie. |
|
Snapshot |
Usa la versione di riga per garantire la coerenza delle letture a livello di transazione. |
|
Serializzabile |
Le transazioni sono completamente isolate l'una dall'altra. |
Per altre informazioni, vedere Guida per il controllo delle versioni delle righe e il blocco della transazione.
Migliorare le prestazioni delle query
Una volta avviata una query pass-through di Access, è possibile usare i metodi avanzati di SQL Server per renderne più efficiente l'esecuzione.
A differenza di un database di Access, SQL Server include query parallele per ottimizzare l'esecuzione di query e le operazioni di indicizzazione per computer con più microprocessori (CPU). Dal momento che SQL Server può eseguire una query o un'operazione di indicizzazione in parallelo usando diversi thread di lavoro del sistema, è possibile completare l'operazione in modo rapido ed efficiente.
Le query sono un componente fondamentale per migliorare le prestazioni complessive della soluzione di database. Le query errate vengono eseguite a tempo indeterminato, scadono e consumano risorse come le CPU, la memoria e la banda della rete. Questo impedisce la disponibilità di informazioni aziendali cruciali. Anche una sola query errata può causare problemi di prestazioni gravi per il database.
Per altre informazioni, vedere l'e-book Faster querying with SQL Server.
Ottimizzazione delle query
Sono disponibili diversi strumenti che consentono di analizzare le prestazioni di una query e di migliorarla: Query Optimizer, piani di esecuzione e Query Store.
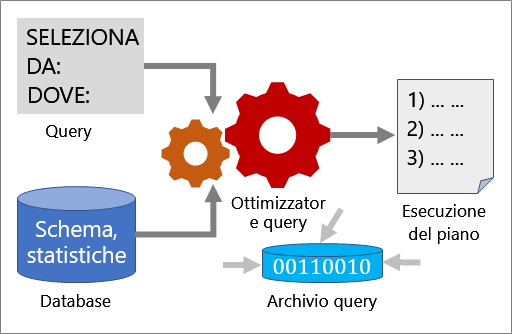
Query Optimizer
Query Optimizer è uno dei componenti più importanti di SQL Server. Usare Query Optimizer per analizzare una query e determinare il modo più efficiente per accedere ai dati necessari. L'input di query Optimizer è costituito dalla query, dallo schema di database (definizioni di tabelle e indice) e dalle statistiche di database. L'output di Query Optimizer è un piano di esecuzione.
Per altre informazioni, vedere The SQL Server Query Optimizer.
Piano di esecuzione
Un piano di esecuzione è una definizione che sequenzia le tabelle di origine a cui accedere e i metodi usati per estrarre i dati da ogni tabella. L'ottimizzazione è il processo di selezione di un piano di esecuzione, potenzialmente in base a molti possibili piani. Ogni piano di esecuzione possibile ha un costo associato nella quantità di risorse di calcolo usate e Query Optimizer sceglie quello con il costo stimato minimo.
SQL Server deve anche adattarsi in modo dinamico alle condizioni variabili nel database. Le regressioni nei piani di esecuzione delle query possono avere un impatto notevole sulle prestazioni. Alcune modifiche apportate a un database possono essere inefficienti o non valide, in base al nuovo stato del database. SQL Server rileva le modifiche che invalidano un piano di esecuzione e contrassegna il piano come non valido.
Per la connessione successiva che esegue la query, è necessario ricompilare un nuovo piano. Le condizioni che invalidano un piano includono:
-
Le modifiche apportate a una tabella o a una visualizzazione a cui fa riferimento la query (ALTER TABLE e ALTER VIEW).
-
Modifiche agli indici usati dal piano di esecuzione.
-
Aggiornamenti alle statistiche usate dal piano di esecuzione, generate esplicitamente da un'istruzione, ad esempio UPDATE STATISTICS, o automaticamente.
Per altre informazioni, vedere Piani di esecuzione.
Query Store
Query Store fornisce informazioni sulle opzioni e sulle prestazioni del piano di esecuzione. Semplifica la risoluzione dei problemi di prestazioni, facilitando la ricerca di differenze di prestazioni dovute alle modifiche al piano di esecuzione. Query Store raccoglie i dati di telemetria, ad esempio una cronologia di query, piani, statistiche di runtime e statistiche di attesa. Usare l'istruzione ALTER DATABASE per implementare Query Store:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Per altre informazioni, vedere Monitoraggio delle prestazioni con Query Store.
Correzione automatica del piano
Il modo più semplice per migliorare le prestazioni della query è la correzione automatica del piano, una funzionalità disponibile con il database SQL di Azure. Basta attivarla per consentirne il funzionamento. Esegue continuamente il monitoraggio e l'analisi del piano di esecuzione, rileva i piani di esecuzione problematici e corregge automaticamente i problemi di prestazioni. Dietro le quinte, la correzione automatica del piano usa una strategia in quattro passaggi per apprendere, adattarsi, verificare e ripetere.
Per altre informazioni, vedere Ottimizzazione automatica.
Elaborazione adattiva delle query
È anche possibile ottenere query più veloci semplicemente eseguendo l'aggiornamento a SQL Server 2017, che contiene una nuova funzionalità denominata elaborazione adattiva delle query. SQL Server modifica le opzioni del piano di query in base alle caratteristiche di runtime.
La stima di cardinalità approssima il numero di righe elaborate a ogni passaggio di un piano di esecuzione. Le stime inesatte possono comportare tempi di risposta lenti della query, utilizzo delle risorse non necessarie (memoria, CPU e IO) e velocità di trasmissione e di concorrenza ridotte. Per adattarsi alle caratteristiche del carico di lavoro delle applicazioni vengono usate tre tecniche:
-
Feedback della concessione di memoria in modalità batch La scarsa stima di cardinalità può causare la "distribuzione sul disco" delle query o l'utilizzo di una quantità eccessiva di memoria. SQL Server 2017 modifica le concessioni di memoria in base al feedback sull'esecuzione, rimuove le distribuzioni sul disco e migliora la concorrenza per le query ripetute.
-
Join adattivi in modalità batch I join adattivi selezionano in modo dinamico un tipo di join interno migliore (join a cicli annidati, merge join o hash join) in fase di esecuzione, in base alle righe di input effettive. Di conseguenza, un piano può passare in modo dinamico a una strategia di join migliore durante l'esecuzione.
-
Esecuzione interleaved Da sempre, le funzioni con valori di tabella con più istruzioni vengono considerate come una black box dall'elaborazione di query. SQL Server 2017 può stimare meglio i conteggi delle righe per migliorare le operazioni a valle.
È possibile rendere automaticamente i carichi di lavoro idonei per l'elaborazione di query adattive abilitando un livello di compatibilità di 140 per il database:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Per altre informazioni, vedere Elaborazione di query intelligenti nei database SQL.
Metodi di query
In SQL Server esistono diversi modi per eseguire query, ognuno dei quali ha i suoi vantaggi. Per fare la scelta giusta per la soluzione di Access, è necessario saperne di più. Il modo migliore per creare le query TSQL consiste nel modificarle e testarle in modo interattivo con l'editor Transact-SQL di SQL Server Management Studio (SSMS), con funzioni IntelliSense che aiutano a scegliere le parole chiave corrette e verificare la presenza di errori di sintassi.
Visualizzazioni
In SQL Server una visualizzazione è simile a una tabella virtuale in cui i dati di visualizzazione provengono da una o più tabelle o da altre visualizzazioni. Tuttavia, le visualizzazioni sono referenziate esattamente come le tabelle nelle query. Le visualizzazioni possono nascondere la complessità delle query e proteggere i dati limitando il set di righe e colonne. Ecco un esempio di visualizzazione semplice:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Per ottenere prestazioni ottimali e modificare i risultati della visualizzazione, creare una visualizzazione indicizzata con spazio di archiviazione allocato, che viene mantenuta nel database come una tabella e in cui è possibile eseguire una query come in qualsiasi tabella. Per usarla in Access, collegarsi alla visualizzazione nello stesso modo in cui si crea un collegamento a una tabella. Ecco un esempio di visualizzazione indicizzata:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Esistono tuttavia alcune restrizioni. Non è possibile aggiornare i dati se sono interessate più tabelle di base o se la visualizzazione contiene funzioni di aggregazione o una clausola DISTINCT. Se SQL Server restituisce un messaggio di errore che indica che non sa quale record eliminare, potrebbe essere necessario aggiungere un trigger DELETE nella visualizzazione. Infine, non è possibile usare la clausola ORDER BY come normalmente si farebbe con una query di Access.
Per altre informazioni, vedere Visualizzazioni e Creare visualizzazioni indicizzate.
Stored procedure
Una stored procedure è costituita da un gruppo di una o più istruzioni TSQL che accettano parametri di input, restituiscono parametri di output e indicano il risultato positivo o negativo con un valore di stato. Fungono da livello intermedio tra il front-end di Access e il back-end di SQL Server. Le stored procedure possono essere semplici come un'istruzione SELECT o complesse come qualsiasi programma. Ecco un esempio:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Se si usa una stored procedure in Access, in genere restituisce un set di risultati in una maschera o un report. Tuttavia, potrebbe eseguire altre azioni che non restituiscono risultati, come le istruzioni DDL o DML. Se si usa una query pass-through, assicurarsi di impostare la proprietà Restituisci record in modo appropriato.
Per altre informazioni, vedere Stored procedure.
Espressioni di tabella comuni
Un'espressione di tabella comune è simile a una tabella temporanea che genera un set di risultati denominato. Esiste solo per l'esecuzione di una query o di una singola istruzione DML. Un'espressione di tabella comune è costituita dalla stessa riga di codice dell'istruzione SELECT o dell'istruzione DML che la usa, mentre la creazione e l'uso di una tabella o di una visualizzazione temporanea è in genere un processo in due passaggi. Ecco un esempio:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
Un'espressione di tabella comune ha diversi vantaggi, tra cui:
-
Poiché le espressioni di tabella comuni sono transitorie, non è necessario crearle come oggetti di database permanenti come le visualizzazioni.
-
È possibile fare riferimento alla stessa espressione di tabella comune più volte in una query o un'istruzione DML, rendendo il codice più gestibile.
-
È possibile usare query che fanno riferimento a un'espressione di tabella comune per definire un cursore.
Per altre informazioni, vedere WITH common_table_expression.
Funzioni definite dall'utente
Una funzione definita dall'utente può eseguire query e calcoli e restituire valori scalari o set di risultati dei dati. Sono simili alle funzioni nei linguaggi di programmazione che accettano parametri, eseguono un'azione, ad esempio un calcolo complesso, e restituiscono il risultato dell'azione come valore. Ecco un esempio:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Una funzione definita dall'utente ha alcune limitazioni. Ad esempio, non può usare alcune funzioni di sistema non deterministiche, eseguire istruzioni DML o DDL o eseguire query SQL dinamiche.
Per altre informazioni, vedere Funzioni definite dall'utente,
Aggiungere chiavi e indici
In qualsiasi sistema di database in uso, le chiavi e gli indici vengono usati in parallelo.
Chiavi
In SQL Server assicurarsi di creare chiavi primarie per ogni tabella e chiavi esterne per ogni tabella correlata. La funzionalità di SQL Server equivalente al tipo di dati Numerazione automatica di Access è la proprietà IDENTITY, che può essere usata per la creazione di valori chiave. Dopo l'applicazione di questa proprietà a qualsiasi colonna numerica, questa diventa di sola lettura e gestita dal sistema di database. Quando si inserisce un record in una tabella che contiene una colonna IDENTITY, il sistema incrementa automaticamente il valore della colonna IDENTITY di 1 e a partire da 1, ma è possibile controllare questi valori con gli argomenti.
Per altre informazioni, vedere CREATE TABLE (Transact-SQL) IDENTITY (proprietà).
Indici
Come sempre, la selezione degli indici è un esercizio di equilibrio tra la velocità della query e il costo di aggiornamento. In Access è presente un solo tipo di indice, ma in SQL Server ne sono disponibili dodici. Fortunatamente, è possibile usare Query Optimizer per scegliere con certezza l'indice più efficace. In Azure SQL è poi possibile usare la gestione automatica degli indici, una funzionalità di ottimizzazione automatica che consiglia l'aggiunta o la rimozione di indici. Diversamente da Access, è necessario creare indici personalizzati per le chiavi esterne in SQL Server. È anche possibile creare indici in una visualizzazione indicizzata per migliorare le prestazioni delle query. Il lato negativo di una visualizzazione indicizzata è il maggiore costo di modifica dei dati nelle tabelle base della visualizzazione, perché è necessario aggiornare anche quest'ultima. Per altre informazioni, vedere Architettura e guida per la progettazione degli indici di SQL Server e Indici.
Eseguire transazioni
L'esecuzione di un processo di transazione online (OTP) è una procedura complessa quando si usa Access, ma relativamente facile con SQL Server. Una transazione è una singola unità di lavoro che esegue il commit di tutte le modifiche ai dati in caso di esito positivo, ma ripristina le modifiche in caso di esito negativo. Una transazione deve avere quattro proprietà, spesso denominate con l'acronimo ACID:
-
Atomicità Una transazione deve essere un'unità atomica di lavoro, cioè vengono eseguite tutte le modifiche ai dati, o nessuna di esse.
-
Coerenza Una volta completata, una transazione deve lasciare tutti i dati in uno stato coerente. Ciò significa che verranno applicate tutte le regole di integrità dei dati.
-
Isolamento Le modifiche apportate da transazioni concomitanti vengono isolate dalla transazione corrente.
-
Durabilità Una volta completata la transazione, le modifiche sono permanenti anche in caso di errori di sistema.
È possibile usare una transazione per garantire l'integrità dei dati, ad esempio un prelievo di contanti da un distributore automatico o il deposito automatico di uno stipendio. È possibile eseguire transazioni esplicite, implicite o con ambito batch. Ecco due esempi di TSQL:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Per altre informazioni, vedere Transazioni.
Uso di vincoli e trigger
Tutti i database hanno modi per mantenere l'integrità dei dati.
Vincoli
In Access è possibile applicare l'integrità referenziale in una relazione tra tabelle con coppie di chiave esterna-chiave primaria, aggiornamenti ed eliminazioni a catena e regole di convalida. Per altre informazioni, vedere Guida alle relazioni tra tabelle e Creare una regola di convalida per convalidare i dati in un campo.
In SQL Server si usano i vincoli UNIQUE e CHECK, ossia oggetti di database che applicano l'integrità dei dati nelle tabelle di SQL Server. Per verificare che un valore sia valido in un'altra tabella, usare un vincolo di chiave esterna. Per verificare che un valore in una colonna sia incluso in un intervallo specifico, usare un vincolo CHECK. Questi oggetti rappresentano la prima linea di difesa e sono stati sviluppati per funzionare in modo efficiente. Per altre informazioni, vedere Vincoli UNIQUE e CHECK.
Trigger
Access non include trigger di database. In SQL Server è possibile usare i trigger per applicare regole di integrità dei dati complesse ed eseguire la logica aziendale nel server. Un trigger di database è una stored procedure che viene eseguita quando si verificano determinate azioni all'interno di un database. Il trigger è un evento, ad esempio l'aggiunta o l'eliminazione di un record in una tabella, che viene generato e quindi esegue la stored procedure. Anche se un database di Access può garantire l'integrità referenziale quando un utente prova ad aggiornare o eliminare dati, SQL Server offre un set di trigger sofisticato. Ad esempio, è possibile programmare un trigger per eliminare i record in blocco e garantire l'integrità dei dati. È anche possibile aggiungere trigger alle tabelle e alle visualizzazioni.
Per altre informazioni, vedere Trigger DML, Trigger DDL e Progettazione di un T-SQL trigger.
Usare le colonne calcolate
In Access è possibile creare una colonna calcolata aggiungendola a una query e generando un'espressione, ad esempio:
Extended Price: [Quantity] * [Unit Price]
Anche in SQL Server la funzionalità equivalente è denominata colonna calcolata, ossia una colonna virtuale non archiviata fisicamente nella tabella, a meno che la colonna non venga contrassegnata come PERSISTENTE. Come per Access, una colonna calcolata di SQL Server usa i dati di altre colonne in un'espressione. Per creare una colonna calcolata, aggiungerla a una tabella. Ad esempio:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Per altre informazioni, vedere Specificare le colonne calcolate in una tabella.
Timestamp dei dati
A volte è possibile aggiungere un campo di tabella per registrare un indicatore data e ora durante la creazione di un record, in modo da poter registrare l'immissione dei dati. In Access è possibile semplicemente creare una colonna data con il valore predefinito di =Now(). Per registrare una data o un'ora in SQL Server, usare il tipo di dati datetime2 con il valore predefinito di SYSDATETIME().
Nota Evitare di confondere rowversion con l'aggiunta di un timestamp ai dati. La parola chiave timestamp è un sinonimo di rowversion in SQL Server, ma è consigliabile usare la parola chiave rowversion. In SQL Server, rowversion è un tipo di dati che espone numeri binari generati automaticamente e univoci in un database e in genere viene usato come meccanismo per le righe della tabella con il contrassegno delle versioni. Tuttavia, il tipo di dati rowversion è solo un numero incrementale, non mantiene una data o un'ora e non è stato sviluppato per l'aggiunta di timestamp a una riga.
Per altre informazioni, vedere rowversion. Per altre informazioni sull'uso di rowversion per ridurre al minimo i conflitti, vedere Eseguire la migrazione di un database di Access a SQL Server.
Gestire oggetti di grandi dimensioni
In Access è possibile gestire i dati non strutturati, ad esempio file, foto e immagini, usando il tipo di dati Allegato. Nella terminologia di SQL Server i dati non strutturati sono detti BLOB (Binary Large Object) e esistono diversi modi per usarli:
FILESTREAM Usa il tipo di dati varbinary(max) per archiviare i dati non strutturati nel file system anziché nel database. Per altre informazioni, vedere Accedere a Dati FILESTREAM con Transact-SQL.
FileTable Archivia i BLOB nelle tabelle speciali denominate FileTable e garantisce la compatibilità con le applicazioni di Windows come se fossero archiviate nel file system, senza apportare modifiche alle applicazioni client. FileTable richiede l'uso di FILESTREAM. Per altre informazioni, vedere FileTable.
Archivio BLOB remoto (RBS) Archivia oggetti binari di grandi dimensioni (BLOB) nelle soluzioni di archiviazione di commodity anziché direttamente nel server. Ciò consente di risparmiare spazio e ridurre le risorse hardware. Per altre informazioni, vedere Dati BLOB (Binary Large Object) (SQL Server).
Lavorare con i dati gerarchici
Anche se i database relazionali come Access sono molto flessibili, l'uso delle relazioni gerarchiche rappresenta un'eccezione e spesso richiede istruzioni SQL o codice complessi. Tra gli esempi di dati gerarchici: una struttura organizzativa, un file system, una tassonomia di termini linguistici e un grafico di collegamenti tra pagine Web. SQL Server include un tipo di dati hierarchyid predefinito e un set di funzioni gerarchiche che consentono di archiviare, eseguire query e gestire facilmente dati gerarchici.
Per altre informazioni, vedere Dati gerarchici ed Esercitazione: Utilizzo del tipo di dati hierarchyid.
Modificare il testo JSON
JSON (JavaScript Object Notation) è un servizio Web che usa testo leggibile per la trasmissione dei dati come coppie attributo-valore nella comunicazione asincrona browser-server. Ad esempio:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Access non ha alcun metodo predefinito per gestire i dati JSON, ma in SQL Server è possibile archiviare, indicizzare, eseguire query ed estrarre dati JSON in modo semplice. È possibile convertire e archiviare il testo JSON in una tabella o formattare i dati come testo JSON. Ad esempio, è consigliabile formattare i risultati della query come JSON per un'app Web o aggiungere strutture di dati JSON in righe e colonne.
Nota JSON non è supportato in VBA. In alternativa, è possibile usare il linguaggio XML in VBA usando la libreria MSXML.
Per altre informazioni, vedere Dati JSON in SQL Server.
Risorse
Ora è il momento giusto per ottenere altre informazioni su SQL Server e Transact SQL (TSQL). Come illustrato prima, Access offre molte funzionalità, ma difetta di altre capacità. Per procedere nell'apprendimento, ecco alcune risorse:
|
Risorsa |
Descrizione |
|
Corso basato su video |
|
|
Esercitazioni su SQL Server 2017 |
|
|
Apprendimento pratico per Azure |
|
|
Per diventare esperti |
|
|
Pagina di destinazione principale |
|
|
Informazioni della Guida |
|
|
Informazioni della Guida |
|
|
Panoramica del cloud |
|
|
Riepilogo visivo delle nuove funzionalità |
|
|
Riepilogo delle funzionalità per versione |
|
|
Download di SQL Server Express 2017 |
|
|
Scaricare database di esempio |









