
Un database progettato correttamente consente l'accesso a informazioni aggiornate e accurate. Dal momento che una progettazione corretta è essenziale per raggiungere gli obiettivi per cui si usa un database, può essere utile investire il tempo necessario per apprendere i principi di una buona progettazione. In definitiva, sarà molto più probabile ottenere un database che soddisfi esigenze specifiche e che supporti facilmente le modifiche.
Questo articolo contiene le linee guida per la pianificazione di un database desktop. Verrà anche illustrato come identificare le informazioni necessarie e come suddividerle in tabelle e colonne appropriate, nonché come si imposta una correlazione tra di esse. Prima di procedere alla creazione del primo database desktop, è consigliabile leggere il presente articolo.
In questo articolo
Terminologia di database che è utile conoscere
Access organizza le informazioni in tabelle: elenchi di righe e colonne che ricordano gli appunti di un commercialista o di un foglio di calcolo. In un database semplice potrebbe essere presente una sola tabella. Per la maggior parte dei database sono necessari più database. Ad esempio, si potrebbe avere una tabella in cui sono archiviate le informazioni sui prodotti, un'altra tabella in cui sono archiviate le informazioni sugli ordini e un'altra con informazioni sui clienti.
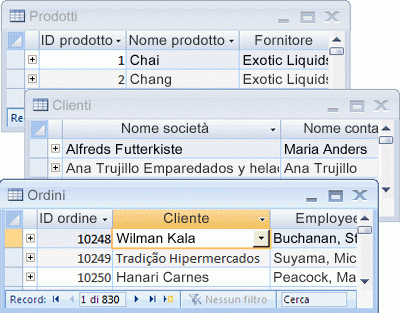
Ogni riga viene più correttamente definita record e ogni colonna è detta campo. Un record costituisce un modo significativo e coerente di combinare informazioni su vari elementi. Un campo è un singolo elemento di informazioni, ovvero un tipo di elemento che viene visualizzato in ogni record. Nella tabella Prodotti, ad esempio, ogni riga o record contiene informazioni su un prodotto. Ogni colonna o campo contiene un tipo di informazioni sul prodotto, ad esempio il nome o il prezzo.
Quando una progettazione di database è appropriata?
Alcuni principi guidano il processo di progettazione del database. Il primo principio è che le informazioni duplicate ( dette anche dati ridondanti) sono cattive, perché sprecare spazio e aumentare la probabilità di errori e incoerenze. Il secondo principio è che la correttezza e la completezza delle informazioni è importante. Se il database contiene informazioni non corrette, anche i report che recuperano informazioni dal database conterranno informazioni errate. Di conseguenza, tutte le decisioni prese in base a tali report verranno disinformate.
Una progettazione di database corretta consentirà quindi di:
-
Dividere le informazioni in tabelle basate su un argomento per ridurre i dati ridondanti.
-
Immettere in Access le informazioni necessarie per unire le informazioni nelle tabelle secondo le esigenze.
-
Supportare e assicurare l'accuratezza e l'integrità delle informazioni.
-
Soddisfare le esigenze di elaborazione dei dati e di creazione di report.
Processo di progettazione
Il processo di progettazione è costituito dai passaggi seguenti:
-
Determinare lo scopo del database
È utile per prepararsi ai passaggi rimanenti.
-
Trovare e organizzare le informazioni necessarie
Raccogliere tutti i tipi di informazioni che si potrebbe voler registrare nel database, come nomi di prodotto e numeri di ordine.
-
Suddividere le informazioni in tabelle
Suddividere le informazioni in entità o argomenti principali, come prodotti o ordini. Ogni argomento diventa quindi una tabella.
-
Trasformare le informazioni in colonne
Stabilire quali informazioni si vogliono archiviare in ogni tabella. Ogni elemento diventa un campo e viene visualizzato sotto forma di colonna nella tabella. Ad esempio, una tabella Dipendenti può includere campi come Cognome e Data assunzione.
-
Specificare le chiavi primarie
Scegli la chiave primaria di ogni tabella. La chiave primaria è una colonna usata per identificare in modo univoco ogni riga. Un esempio può essere l'ID prodotto o l'ID ordine.
-
Impostare le relazioni tra tabelle
Esaminare ogni tabella e decidere in che modo i dati presenti in una tabella sono correlati ai dati in altre tabelle. Aggiungere campi alle tabelle o creare nuove tabelle per chiarire le relazioni, se necessario.
-
Ottimizzare la progettazione
Analizzare la progettazione per verificare se sono presenti errori. Creare le tabelle e aggiungere alcuni record di dati di esempio. Controllare se è possibile ottenere i risultati desiderati da tali tabelle. Apportare modifiche alla progettazione, se necessario.
-
Applicare le regole di normalizzazione
Applicare le regole di normalizzazione dei dati per verificare se le tabelle sono strutturate correttamente. Apportare modifiche alle tabelle, se necessario.
Identificazione dello scopo del database
È consigliabile annotare su carta lo scopo del database, ovvero qual è lo scopo, come si prevede di usarlo e chi lo userà. Per un piccolo database per un'azienda a conduzione familiare, ad esempio, si potrebbe scrivere qualcosa di semplice come "Il database dei clienti mantiene un elenco di informazioni sui clienti allo scopo di produrre la corrispondenza e i report". Se il database è più complesso o viene usato da molte persone, come accade spesso in una configurazione aziendale, lo scopo può facilmente richiedere uno o più paragrafi e dovrebbe includere l'indicazione su quando o come ogni persona userà il database. L'idea è di avere una dichiarazione di intenti ben sviluppata a cui sia possibile fare riferimento durante tutto il processo di progettazione. La presenza di tale dichiarazione consente di concentrarsi sugli obiettivi quando si assumono decisioni.
Individuazione e organizzazione delle informazioni necessarie
Per trovare e organizzare le informazioni necessarie, iniziare con le informazioni esistenti. Ad esempio, è possibile registrare gli ordini di acquisto in un libro mastro o mantenere le informazioni sui clienti in moduli cartacei in uno schedario. Raccogliere i documenti ed elencare ogni tipo di informazioni visualizzato, ad esempio ogni casella compilata in un modulo. Se non si hanno maschere esistenti, si supponga di dover progettare una maschera per registrare le informazioni sul cliente. Quali informazioni inseriresti nel modulo? Quali caselle di riempimento crearesti? Identificare ed elencare ognuno di questi elementi. Si supponga, ad esempio, di mantenere attualmente l'elenco dei clienti nelle schede indice. L'esame di queste schede potrebbe indicare che ogni scheda contiene il nome, l'indirizzo, la città, lo stato, il codice postale e il numero di telefono di ogni carta. Ognuno di questi elementi rappresenta una potenziale colonna in una tabella.
Mentre prepari questo elenco, non preoccuparti di averlo perfetto all'inizio. Elencare invece ogni elemento che viene in mente. Se il database verrà usato da un altro utente, chiedere le proprie idee. È possibile ottimizzare l'elenco in un secondo momento.
Considerare quindi i tipi di report o lettere che si potrebbe voler produrre dal database. Ad esempio, si potrebbe voler visualizzare un report vendite prodotto in base all'area geografica o un report di riepilogo dell'inventario che mostri i livelli di inventario dei prodotti. È anche possibile generare lettere tipo da inviare ai clienti che annunciano un evento di vendita o offrono un premio. Progettare il report nella mente e immaginarne l'aspetto. Quali informazioni inseriresti nel report? Elencare ogni voce. Eseguire la stessa operazione per la lettera di modulo e per qualsiasi altro report che si prevede di creare.

Pensare ai report e alle lettere che si potrebbe voler creare consente di identificare gli elementi necessari nel database. Si supponga ad esempio di offrire ai clienti l'opportunità di acconsentire esplicitamente ad aggiornamenti periodici tramite posta elettronica e di voler stampare un elenco di utenti che hanno acconsentito esplicitamente a partecipare. Per registrare tali informazioni, aggiungere una colonna "Invia messaggio di posta elettronica" alla tabella clienti. Per ogni cliente, è possibile impostare il campo su Sì o No.
Il requisito di inviare messaggi di posta elettronica ai clienti suggerisce un altro elemento da registrare. Dopo avere ricevuto la conferma che un cliente vuole ricevere messaggi di posta elettronica, si dovrà conoscere l'indirizzo di posta elettronica a cui inviarli. È quindi necessario registrare un indirizzo di posta elettronica per ogni cliente.
È consigliabile creare un prototipo di ogni report o elenco di output e considerare gli elementi necessari per produrre il report. Ad esempio, quando si esamina una lettera, potrebbero venire in mente alcuni aspetti. Se si vuole includere una formula di apertura appropriata, ad esempio la stringa "Sig.", "Signora" o "Sig." che inizia una formula di apertura, è necessario creare una formula di apertura. Inoltre, è in genere possibile iniziare una lettera con "Gentile Signor Smith" anziché "Gentile. Mr. Sylvester Smith". Questo suggerisce che in genere si vuole archiviare il cognome separatamente dal nome.
Un punto chiave da ricordare è la necessità di suddividere ogni informazione nelle relative parti utili più piccole. Nel caso di un nome, per render immediatamente disponibile il cognome, è opportuno dividere il nome in due parti, Nome e Cognome. Per ordinare un report in base al cognome, ad esempio, è utile archiviare separatamente il cognome del cliente. È in genere consigliabile inserire in un campo separato le informazioni in base alle quali si vogliono applicare criteri di ordinamento, ricerca e calcolo oppure creare un report.
Pensa alle domande a cui potresti voler rispondere al database. Ad esempio, quante vendite del prodotto in primo piano hai chiuso il mese scorso? Dove vivono i tuoi clienti migliori ? Chi è il fornitore del tuo prodotto più venduto? Anticipare queste domande consente di inserire altri elementi da registrare.
Dopo avere raccolto queste informazioni, è possibile procedere al passaggio successivo.
Suddivisione delle informazioni in tabelle
Per suddividere le informazioni in tabelle, scegliere le entità o gli argomenti principali. Dopo avere trovato e organizzato le informazioni, ad esempio, per un database relativo alle vendite di prodotti, l'elenco preliminare potrebbe avere l'aspetto seguente:

Le principali entità qui illustrate sono i prodotti, i fornitori, i clienti e gli ordini. È quindi consigliabile iniziare con queste quattro tabelle: una per le informazioni sui prodotti, una per le informazioni sui fornitori, una per le informazioni sui clienti e una per le informazioni sugli ordini. Anche se l'elenco non è completo, è un buon punto di partenza. È possibile continuare a ottimizzare questo elenco finché non si ottiene una progettazione appropriata.
Quando inizialmente si esamina l'elenco di elementi preliminare, si potrebbe essere tentati di inserirli tutti in un'unica tabella, anziché le quattro illustrate nella figura precedente. Di seguito viene spiegato perché non è opportuno procedere in questo modo. Si consideri per un momento la tabella illustrata di seguito:
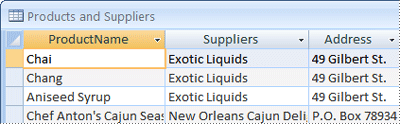
In questo caso, ogni riga contiene informazioni sul prodotto e sul suo fornitore. Dal momento che possono essere presenti molti prodotti dello stesso fornitore, le informazioni su nome e indirizzo del fornitore devono essere ripetute molte volte. Questo provoca uno spreco dello spazio su disco. In alternativa, è possibile registrare le informazioni sul fornitore una sola volta in una tabella Fornitori separata e quindi collegare questa tabella alla tabella Prodotti.
Un secondo problema in questa progettazione si presenta quando si devono modificare le informazioni sul fornitore. Si supponga di dover modificare l'indirizzo di un fornitore. Dal momento che è visualizzato in molti punti, si potrebbe accidentalmente modificare l'indirizzo in un punto dimenticando di modificarlo negli altri. La registrazione dell'indirizzo del fornitore in un'unica posizione risolve il problema.
Quando si progetta un database, è sempre opportuno cercare di registrare ogni dato una sola volta. Se si rileva che la stessa informazione viene ripetuta in più posizioni, ad esempio l'indirizzo di un particolare fornitore, inserire tale informazione in una tabella distinta.
Si supponga infine che Coho Winery fornisca un solo prodotto e che si voglia eliminare il prodotto conservando le informazioni relative al nome e all'indirizzo del fornitore. Come elimineresti il record del prodotto senza perdere anche le informazioni sul fornitore? No, non potresti. Poiché ogni record contiene dati su un prodotto e informazioni su un fornitore, non è possibile eliminarli senza eliminarli. Per mantenere separati questi dati, è necessario dividere una tabella in due: una per le informazioni sui prodotti e un'altra per le informazioni sul fornitore. L'eliminazione di un record di prodotto dovrebbe eliminare solo i fatti sul prodotto, non i fatti sul fornitore.
Dopo avere scelto l'argomento rappresentato da una tabella, nelle relative colonne dovranno essere archiviati solo dati su tale argomento. La tabella di prodotti, ad esempio, deve archiviare solo dati sui prodotti. Dal momento che l'indirizzo del fornitore è un dato relativo al fornitore e non al prodotto, appartiene alla tabella dei fornitori.
Trasformazione di informazioni in colonne
Per determinare le colonne di una tabella, è opportuno stabilire quali sono le informazioni relative all'argomento registrato nella tabella di cui è necessario tenere traccia. Per la tabella Clienti, ad esempio, Nome, Indirizzo, Città-Stato-CAP, Invio messaggio di posta elettronica, Formula di apertura e Posta elettronica sono un buon elenco di colonne da cui iniziare. Ogni record nella tabella contiene lo stesso set di colonne, quindi è possibile archiviare informazioni relative a Nome, Indirizzo, Città-Stato-CAP, Invio messaggio di posta elettronica, Formula di apertura e Posta elettronica per ogni record. La colonna Indirizzo, ad esempio, contiene l'indirizzo per quel cliente. Ogni record contiene dati relativi a un cliente e il campo indirizzo contiene l'indirizzo per quel cliente specifico.
Dopo avere determinato il set iniziale di colonne per ogni tabella, è possibile definire le colonne con precisione ancora maggiore. È consigliabile, ad esempio, archiviare il nome del cliente in due colonne distinte, nome e cognome, per poter eseguire operazioni di ordinamento, ricerca e indicizzazione solo su tali colonne. In modo analogo, l'indirizzo è in effetti composto da cinque componenti distinti, ovvero indirizzo, città, provincia, CAP e paese, e anche in questo caso è consigliabile archiviarli in colonne distinte. Se si vuole eseguire un'operazione di ricerca o di ordinamento oppure applicare un filtro in base, ad esempio, alla provincia, è necessario archiviare le informazioni corrispondenti in una colonna distinta.
È opportuno considerare anche se il database conterrà informazioni solo di origine nazionale o anche internazionale. Se si prevede, ad esempio, di archiviare indirizzi internazionali, è preferibile creare una colonna Paese anziché provincia, per potervi inserire sia la provincie nazionali sia le aree di altri paese. Una colonna CAP sarà invece appropriata anche per archiviare indirizzi internazionali.
L'elenco seguente contiene alcuni suggerimenti utili per determinare quali colonne creare.
-
Non includere dati calcolati
Nella maggior parte dei casi, è consigliabile non archiviare risultati di calcoli nelle tabelle. Al contrario, è possibile fare in modo che i calcoli vengano eseguiti da Access quando si vuole visualizzare il risultato. Si supponga, ad esempio, di avere un report Prodotti ordinati in cui viene visualizzato il subtotale delle unità ordinate per ogni categoria di prodotto nel database. Non è tuttavia presente una colonna di subtotale Unità ordinate in alcuna tabella. La tabella Prodotti include invece una colonna Unità ordinate in cui sono archiviate le unità ordinate per ogni prodotto. Usando questi dati, Access calcola il subtotale ogni volta che si stampa il report. È consigliabile non archiviare il subtotale stesso in una tabella.
-
Archiviare le informazioni nelle relative parti logiche più piccole
Si potrebbe essere tentati di avere un singolo campo per i nomi completi o per i nomi di prodotto insieme alle descrizioni dei prodotti. Se si combinano più tipi di informazioni in un campo, è difficile recuperare i singoli fatti in un secondo momento. Provare a suddividere le informazioni in parti logiche; Ad esempio, creare campi separati per nome e cognome oppure per il nome, la categoria e la descrizione del prodotto.

Dopo avere ottimizzato le colonne dati in ogni tabella, è possibile scegliere la relativa chiave primaria.
Specifica di chiavi primarie
Ogni tabella deve includere una colonna (o set di colonne) che identifichi in modo univoco ogni riga archiviata nella tabella. Si tratta spesso di un numero di identificazione univoco, ad esempio il numero ID di un dipendente o un numero di serie. Nella terminologia di database queste informazioni sono definite chiave primaria della tabella. Access usa i campi di chiavi primarie per associare rapidamente dati di più tabelle e unire i dati automaticamente.
Se si ha già un identificatore univoco per una tabella, ad esempio un numero di prodotto che identifica in modo univoco ogni prodotto nel catalogo, è possibile usarlo come chiave primaria della tabella, ma solo se i valori in questa colonna saranno sempre diversi per ogni record. Non è possibile usare valori duplicati in una chiave primaria. Non usare, ad esempio, nomi di persone come chiave primaria, perché i nomi non sono univoci. È molto facile che due persone abbiano lo stesso nome nella stessa tabella.
Una chiave primaria deve avere sempre un valore. Se il valore di una colonna può diventare a un certo punto non assegnato o sconosciuto (valore mancante), non può essere usato come componente di una chiave primaria.
È consigliabile scegliere sempre una chiave primaria il cui valore non venga modificato. In un database che usa più di una tabella, è possibile usare la chiave primaria di una tabella come riferimento in altre tabelle. Se la chiave primaria viene modificata, tale modifica dovrà essere applicata anche a qualsiasi altro elemento in cui viene fatto riferimento a tale chiave. L'uso di una chiave primaria non soggetta a modifiche riduce la possibilità che non sia più sincronizzata con altre tabelle che vi fanno riferimento.
Spesso come chiave primaria viene utilizzato un numero univoco arbitrario. Ad esempio, è possibile assegnare a ogni ordine un numero di ordine univoco. L'unico scopo del numero d'ordine è quello di identificare un ordine. Una volta assegnato, non cambia mai.
Se non si ha una colonna o un set di colonne adatte a costituire la chiave primaria, è possibile usare una colonna con tipo di dati Numerazione automatica. Quando si usa questo tipo di dati, viene assegnato automaticamente un valore. Tale identificatore non rappresenta un dato effettivo, ovvero non contiene alcuna informazione effettiva che descriva la riga a cui è associato. L'uso di questo tipo di identificatori come chiave primaria è ideale perché non vengono modificati. Una chiave primaria che contiene dati relativi a una riga, ad esempio un numero di telefono o il nome di un cliente, è più facilmente soggetta a modifiche, perché i dati stessi che contiene potrebbero variare nel tempo.
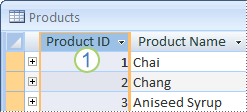
1. Una colonna impostata sul tipo di dati Numerazione automatica spesso costituisce una chiave primaria valida. Non esistono due ID prodotto uguali.
In alcuni casi è possibile usare due o più campi che insieme costituiscono la chiave primaria di una tabella. Una tabella Dettagli sugli ordini che memorizza le voci d'ordine potrebbe, ad esempio, usare come chiave primaria due colonne, ovvero ID ordine e ID prodotto. Le chiavi primarie costituite da più colonne vengono anche definite chiavi composte.
Per il database relativo alle vendite di prodotti è possibile creare una colonna Numerazione automatica per ognuna delle tabelle usate come chiave primaria: IDProdotto per la tabella Prodotti, IDOrdine per la tabella Ordini, IDCliente per la tabella Clienti e IDFornitore per la tabella Fornitori.

Creazione di relazioni tra tabelle
Dopo avere suddiviso le informazioni in tabelle, è necessario riunire di nuovo tali informazioni nei modi appropriati. La maschera seguente, ad esempio, include informazioni recuperate da diverse tabelle.
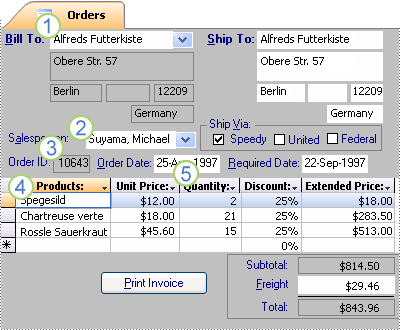
1. Le informazioni nella maschera provengono dalla tabella Clienti...
2. ...dalla tabella Dipendenti...
3. ...dalla tabella Ordini...
4. ...dalla tabella Prodotti...
5. ...e dalla tabella Dettagli sugli ordini.
Access è un sistema di gestione di database relazionali. In un database relazionale le informazioni vengono suddivise in tabelle distinte in base all'argomento. Le relazioni tra tabelle vengono quindi usate per riunire le informazioni secondo le esigenze.
Creazione di una relazione uno-a-molti
Si consideri l'esempio seguente, in cui il database relativo ai prodotti ordinati include le tabelle Fornitori e Prodotti. Un fornitore può fornire una quantità qualsiasi di prodotti. Di conseguenza, per qualsiasi fornitore rappresentato nella tabella Fornitori possono essere rappresentati molti prodotti nella tabella Prodotti. Tra la tabella Fornitori e la tabella Prodotti esiste quindi una relazione uno-a-molti.
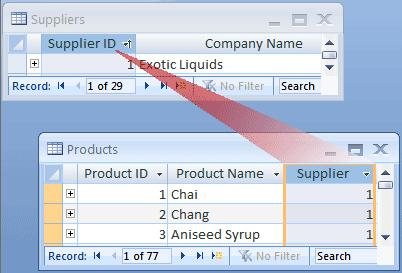
Per rappresentare una relazione uno-a-molti nella progettazione del database, aggiungere la chiave primaria del lato "uno" della relazione come colonna o colonne aggiuntive alla tabella sul lato "molti" della relazione. In questo caso, ad esempio, si aggiunge la colonna ID fornitore dalla tabella fornitori alla tabella Prodotti. Il numero di ID fornitore potrà quindi essere usato da Access nella tabella Prodotti per trovare il fornitore corretto per ogni prodotto.
La colonna ID fornitore nella tabella Prodotti è detta chiave esterna. Una chiave esterna è un'altra chiave primaria della tabella. La colonna ID fornitore nella tabella Prodotti è una chiave esterna, perché è anche la chiave primaria della tabella Fornitori.

Per creare le basi per unire in join tabelle correlate, è necessario definire coppie di chiavi primarie e chiavi esterne. Se non si è certi delle tabelle che dovrebbero condividere una colonna comune, identificare una relazione uno-a-molti per assicurare che le due tabelle interessate richiedano in effetti una colonna condivisa.
Creazione di una relazione molti-a-molti
Si consideri la relazione tra una tabella Prodotti e una tabella Ordini.
Un singolo ordine può includere più prodotti. D'altra parte, un singolo prodotto può comparire in molti ordini. Di conseguenza, per ogni record nella tabella Ordini, possono esistere molti record nella tabella Prodotti. E per ogni record nella tabella Prodotti possono essere presenti molti record nella tabella Ordini. Questo tipo di relazione è detta relazione molti-a-molti perché per qualsiasi prodotto possono essere presenti molti ordini; e per qualsiasi ordine, ci possono essere molti prodotti. Per rilevare le relazioni molti-a-molti tra le tabelle, è importante considerare entrambi i lati della relazione.
Gli argomenti delle due tabelle, ordini e prodotti, hanno una relazione molti-a-molti. Questo presenta un problema. Per comprendere il problema, immagina cosa succederebbe se provassi a creare la relazione tra le due tabelle aggiungendo il campo ID prodotto alla tabella Ordini. Per avere più di un prodotto per ordine, è necessario più di un record nella tabella Ordini per ordine. Si ripeterebbero informazioni sull'ordine per ogni riga correlata a un singolo ordine, creando una progettazione inefficiente che potrebbe causare dati non accurati. Si verifica lo stesso problema se si inserisce il campo ID ordine nella tabella Prodotti, ovvero si hanno più record nella tabella Prodotti per ogni prodotto. Come si risolve questo problema?
La risposta consiste nel creare una terza tabella, spesso denominata tabella di collegamento, che suddivide la relazione molti-a-molti in due relazioni uno-a-molti. Inserire in questa terza tabella la chiave primaria di ognuna delle due tabelle. Di conseguenza, la terza tabella registra ogni occorrenza o istanza della relazione.
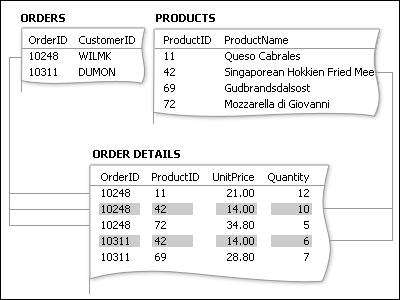
Ogni record nella tabella Dettagli sugli ordini rappresenta una voce in un ordine. La chiave primaria della tabella Dettagli sugli ordini è costituita da due campi, le chiavi esterne delle tabelle Ordini e Prodotti. Non è possibile usare il campo ID ordine da solo come chiave primaria per questa tabella, perché a un ordine possono corrispondere più voci. L'ID ordine viene ripetuto per ogni voce di un ordine, di conseguenza il campo non contiene valori univoci. Non è possibile usare nemmeno il campo ID prodotto da solo, perché un prodotto può essere presente in molti ordini diversi. Usati insieme, tuttavia, i due campi generano sempre un valore univoco per ogni record.
Nel database relativo alle vendite di prodotti, la tabella Ordini e la tabella Prodotti non sono direttamente correlate tra loro. Sono invece correlate indirettamente tramite la tabella Dettagli ordine. La relazione molti-a-molti tra ordini e prodotti è rappresentata nel database mediante due relazioni uno-a-molti:
-
Tra la tabella Ordini e la tabella Dettagli sugli ordini è presente una relazione uno-a-molti. A ogni ordine può corrispondere più di una voce, ma ognuna è collegata a un solo ordine.
-
Tra la tabella Prodotti e la tabella Dettagli sugli ordini è presente una relazione uno-a-molti. A ogni prodotto possono essere associate molte voci, ma ogni voce si riferisce a un solo prodotto.
Dalla tabella Dettagli sugli ordini è possibile determinare tutti i prodotti di un ordine specifico. È anche possibile determinare tutti gli ordini per un determinato prodotto.
Dopo avere incorporato la tabella Dettagli sugli ordini, l'elenco delle tabelle e dei campi potrebbe avere un aspetto analogo al seguente:

Creazione di una relazione uno-a-uno
Un altro tipo di relazione disponibile è la relazione uno-a-uno. Si supponga, ad esempio, di avere l'esigenza di registrare speciali informazioni supplementari sui prodotti, che saranno usate raramente o applicabili solo a pochi prodotti. Dal momento che tali informazioni sono raramente necessarie e che la loro archiviazione nella tabella Prodotti comporterebbe la presenta di spazio vuoto per ogni prodotto a cui tali informazioni non sono applicabili, si userà una tabella distinta. In modo analogo alla tabella Prodotti, verrà usato IDProdotto come chiave primaria. La relazione tra questa tabella supplementare e la tabella Prodotto costituisce una relazione uno-a-uno. Per ogni record nella tabella Prodotto è presente un unico record corrispondente nella tabella supplementare. Quando si identifica tale relazione, entrambe le tabelle devono condividere un campo comune.
Quando si rileva l'esigenza di impostare una relazione uno-a-uno nel database, verificare che sia possibile inserire le informazioni dalle due tabelle in una sola. Se non si vuole effettuare questa operazione per qualsiasi motivo, ad esempio perché rimarrebbe parecchio spazio vuoto, nell'elenco seguente è illustrato come verrebbe rappresentata la relazione nella progettazione:
-
Se le due tabelle condividono lo stesso argomento, è probabilmente possibile impostare la relazione usando la stessa chiave primaria in entrambe le tabelle.
-
Se le due tabelle includono argomenti diversi con chiavi primarie diverse, scegliere una delle due tabelle (una qualsiasi) e inserire la relativa chiave primaria nell'altra tabella come chiave esterna.
La capacità di determinare le relazioni tra tabelle assicura che vengano usata le tabelle e le colonne corrette. Quando è presente una relazione uno-a-uno o uno-a-molti, le tabelle interessate devono condividere una colonna o più colonne comuni. Quando è presente una relazione molti-a-molti, per rappresentare la relazione è necessaria una terza tabella.
Ottimizzazione della progettazione
Dopo avere definito le tabelle, i campi e le relazioni necessari, è consigliabile creare e popolare le tabelle con dati di esempio e provare a usare tali informazioni, creando query, aggiungendo nuovi record e così via. In questo modo è possibile evidenziare i potenziali problemi, ad esempio, potrebbe essere necessario aggiungere una colonna che si è dimenticato di inserire durante la fase di progettazione oppure dividere una tabella per rimuovere la duplicazione.
Verificare se è possibile usare il database per ottenere le risposte desiderate. Creare bozze di maschere e report e verificare se vengono visualizzati i dati previsti. Cercare le eventuali inutili duplicazioni dei dati e, se vengono trovate, modificare la progettazione per eliminarle.
Mentre si prova a usare il database iniziale, si scopriranno con tutta probabilità aree soggette a miglioramento. Di seguito sono elencati alcuni aspetti da verificare:
-
Verificare se sono state dimenticate colonne. In tal caso controllare se le informazioni sono presenti nelle tabelle esistenti. Se si tratta di informazioni relative ad altri argomenti, potrebbe essere necessario creare un'altra tabella. Creare una colonna per ogni informazione di cui è necessario tenere traccia. Se non è possibile calcolare le informazioni da altre colonne, è probabile che sia necessario creare una nuova colonna a tale scopo.
-
Stabilire se sono presenti colonne non necessarie, perché possono essere calcolate da campi esistenti. Se un'informazione può essere calcolata da altre colonne esistenti, ad esempio un prezzo scontato calcolato dal prezzo al dettaglio, è in genere preferibile procedere in tal modo, evitando di creare nuove colonne.
-
Verificare se vengono immesse ripetutamente informazioni duplicate in una delle tabelle. In tal caso è probabilmente necessario dividere la tabella in due tabelle con una relazione uno-a-molti.
-
Verificare se nelle tabelle sono presenti molti campi, un numero limitato di record e molti campi vuoti nei singoli record. In tal caso, considerare la possibilità di riprogettare la tabella in modo che contenga meno campi e record.
-
Verificare se ogni informazione è stata suddivisa in parti utili più piccole. Se è necessario creare report oppure applicare criteri di ordinamento o eseguire ricerche o calcoli su un elemento di informazioni, inserire tale elemento in una colonna corrispondente.
-
Verificare se ogni colonna contiene dati relativi all'argomento della tabella. Se una colonna non contiene informazioni sull'argomento di una tabella, appartiene a una tabella diversa.
-
Verificare che tutte le relazioni tra tabelle siano rappresentate da campi comuni o da una terza tabella. Le relazioni uno-a-uno e uno-a-molti- richiedono colonne comuni. Le relazioni molti a molti richiedono una terza tabella.
Ottimizzazione della tabella Prodotti
Si supponga che ogni prodotto nel database relativo alle vendite di prodotti rientri in una categoria generale, ad esempio Bevande, Condimenti o Pesce. La tabella Prodotti può includere un campo che visualizza la categoria per ogni prodotto.
Si supponga che dopo avere esaminato e ottimizzato la progettazione del database si decida di archiviare una descrizione della categoria insieme al relativo nome. Se si aggiunge un campo Descrizione categoria alla tabella Prodotti, sarà necessario ripetere ogni descrizione di categoria per ogni prodotto che rientra in tale categoria, una soluzione non certo ottimale.
Una soluzione migliore consiste nell'impostare Categorie come nuovo argomento di cui tenere traccia nel database, con una tabella e una chiave primaria personalizzate. Sarà quindi possibile aggiungere la chiave primaria dalla tabella Categorie alla tabella Prodotti come chiave esterna.
Le tabelle Categorie e Prodotti sono collegate con una relazione uno-a-molti, infatti una categoria può includere più prodotti, ma un prodotto può appartenere a una sola categoria.
Quando si esaminano le strutture delle tabelle, prestare attenzione agli eventuali gruppi ripetuti. Si consideri ad esempio una tabella contenente le colonne seguenti:
-
ID prodotto
-
Nome
-
ID Prodotto1
-
Nome1
-
ID Prodotto2
-
Nome2
-
ID Prodotto3
-
Nome3
Ogni prodotto è un gruppo ripetuto di colonne che differiscono dalle altre solo aggiungendo un numero alla fine del nome della colonna. Se si osservano colonne con questa numerazione, è consigliabile rivedere la progettazione.
Tale design ha diversi difetti. Per cominciare, ti impone di posizionare un limite superiore sul numero di prodotti. Non appena si supera questo limite, è necessario aggiungere un nuovo gruppo di colonne alla struttura della tabella, che rappresenta un'attività amministrativa importante.
Un altro problema è dovuto allo spreco di spazio per i fornitori con un una quantità di prodotti inferiore al numero massimo, perché le colonne aggiuntive saranno vuote. Il difetto più grave di tale progettazione è che rende difficile l'esecuzione di molte attività, ad esempio l'ordinamento o l'indicizzazione della tabella per ID prodotto o per nome.
Ogni volta che si rilevano gruppi ripetuti, è consigliabile rivedere attentamente la progettazione considerando la possibilità di dividere la tabella in due. Nell'esempio precedente è preferibile usare due tabelle, una per i fornitori e una per i prodotti, collegate con l'ID fornitore.
Applicazione delle regole di normalizzazione
È possibile applicare le regole di normalizzazione dei dati, a volte denominate semplicemente regole di normalizzazione, come passaggio successivo della progettazione. Usare queste regole per verificare se le tabelle sono strutturate correttamente. Il processo di applicazione delle regole alla progettazione del database è detto normalizzazione del database o semplicemente normalizzazione.
La normalizzazione è particolarmente utile dopo aver rappresentato tutte le informazioni e aver creato una progettazione preliminare. L'idea è quella di garantire che le informazioni siano state suddivise nelle tabelle appropriate. Ciò che la normalizzazione non può fare è assicurarsi di avere tutti gli elementi di dati corretti per iniziare.
Applicare le regole in successione, verificando a ogni passaggio che la progettazione raggiunga una di quelle che vengono definite "forme normali". In genere vengono ampiamente accettate cinque forme normali, dalla prima alla quinta. Questo articolo considera solo le prime tre, perché rappresentano i requisiti necessari per la maggior parte delle progettazioni di database.
Prima forma normale
La prima forma normale specifica che a ogni intersezione di riga e colonna nella tabelle è presente un singolo valore e mai un elenco di valori. Ad esempio non è possibile avere un campo denominato Prezzo con cui siano presenti più prezzi. Se si considera ogni intersezione di riga e colonna come una cella, ogni cella può contenere un solo valore.
Seconda forma normale
La seconda forma normale richiede che ogni colonna non chiave sia completamente dipendente dall'intera chiave primaria e non solo da una parte di tale chiave. Questa regola viene applicata in presenza di una chiave primaria composta da più colonne. Si supponga ad esempio di avere una tabella contenente le colonne seguenti, dove ID ordine o ID prodotto costituisce la chiave primaria:
-
ID ordine (chiave primaria)
-
ID prodotto (chiave primaria)
-
Nome prodotto
Questa progettazione viola la seconda forma normale, perché Il nome prodotto dipende dall'ID prodotto, ma non da ID ordine, quindi non dipende dall'intera chiave primaria. È necessario rimuovere Nome prodotto dalla tabella. Appartiene a una tabella diversa (Prodotti).
Terza forma normale
La terza forma normale richiede non solo che ogni colonna non chiave sia dipendente dall'intera chiave primaria, ma che le colonne non chiave siano indipendenti le une dalle altre.
In altre parole, ogni colonna non chiave deve essere dipendente dalla chiave primaria ed esclusivamente dalla chiave primaria. Si supponga ad esempio di avere una tabella che contiene le colonne seguenti:
-
ID prodotto (chiave primaria)
-
Nome
-
PDC
-
Sconto
Si supponga che la colonna Sconto dipenda dal prezzo al dettaglio consigliato (PDC). Questa tabella viola la terza forma normale perché una colonna non chiave, Sconto, dipende da un'altra colonna non chiave, PDC. Indipendenza delle colonne significa che deve essere possibile modificare qualsiasi colonna non chiave senza influire su qualsiasi altra colonna. Se si modifica un valore nel campo PDC, il valore di Sconto verrebbe modificato di conseguenza, violando in tal modo la regola. In questo caso è necessario spostare la colonna Sconto in un'altra tabella la cui chiave primaria è basata sulla colonna PDC.









