
A Excel 2013-as vagy újabb, több millió sort tartalmazó adatmodelleket hozhat létre, majd hatékony adatelemzést végezhet ezekkel a modellekkel. Az adatmodellek a bővítményekkel és Power Pivot nélkül is hozhatók létre, hogy ugyanabban a munkafüzetben bármilyen számú kimutatást, diagramot és Power View képes legyen támogatni.
Megjegyzés: Ez a cikk a 2013-as Excel ismerteti. A 2013-as Excel bevezetett adatmodellezés és Power Pivot-funkciók azonban a Excel 2016. A két verzió között nincs Excel.
Bár a nagy adatmodelleket egyszerűen felépítheti Excel, számos oka lehet annak, ha nem. Első lépésként a rengeteg táblázatot és oszlopot tartalmazó nagy modellek a legtöbb elemzéshez túl vannak edzve, és kényelmetlen mezőlistát hoznak létre. Másodikként a nagy modellek értékes memóriát használnak, negatív hatással vannak az azonos rendszererőforrásokkal osztozó más alkalmazásokra és jelentésekre. Végül a Microsoft 365 alkalmazásban a SharePoint Online és Excel Web App is 10 MB-ra korlátozza a Excel-fájlok méretét. A több millió sort tartalmazó munkafüzet-adatmodellekben elég gyorsan belefut a 10 MB-os korlát. Lásd: Adatmodell specifikációja és korlátai.
Ebből a cikkből megtudhatja, hogy miként építhet egy könnyebben kezelhető és kevesebb memóriát használó, szorosan felépítésű modellt. Ha időt vesz arra, hogy megtanulja az ajánlott eljárásokat a hatékony modelltervezésben, minden létrehozott és használt modellhez időt vesz majd, függetlenül attól, hogy Excel 2013-ban, az Microsoft 365 SharePoint Online-ban, egy Office Web Apps-kiszolgálón vagy egy SharePoint 2013-as verzióban használja azt.
Fontolja meg a Munkafüzetméret-optimalizáló futtatását is. Elemzi a Excel, és ha lehetséges, további tömörítést is tartalmaz. Töltse le a Workbook Size Optimizer (Munkafüzetméret-optimalizáló) gombra.
Tartalom
A tömörítési arányok és a memória-elemzési motor
Az adatmodellek Excel a memóriabeli elemzési motorral tárolja az adatokat a memóriában. A motor hatékony tömörítési technikákat alkalmaz a tárolási követelmények csökkentéséhez, az eredményhalmaz zsugorítását, amíg az az eredeti méret töredékére nem csökken.
Az adatmodellek átlagosan 7–10-szer kisebbek lesznek a forrásnál. Ha például 7 MB adatot importál egy SQL Server-adatbázisból, az Excel adatmodell könnyen 1 MB vagy kevesebb lehet. A ténylegesen elérhető tömörítési mértéke elsősorban az egyes oszlopok egyedi értékeinek számától függ. Minél több egyedi értéket ad meg, annál több memóriára van szükség a tárolásukhoz.
Miért a tömörítésről és az egyedi értékekről van szó? Mivel a memóriahasználatot minimalizáló hatékony modell kiépítése mindössze a tömörítési maximalizálásról szól, és a legegyszerűbb módja ennek az, ha eltünteti azokat az oszlopokat, amelyekre nincs igazán szüksége, különösen ha ezek az oszlopok sok egyedi értéket tartalmaznak.
Megjegyzés: Az egyes oszlopok tárterületkövetelményei nagyok lehet. Bizonyos esetekben jobb, ha több oszlopban alacsony az egyedi értékek száma, és nem egy magas számú egyedi értékkel. A Datetime-optimalizálások szakasza részletesen ismerteti ezt a módszert.
Semmi sem jobb, mint egy nem létező oszlop a kis memóriahasználat esetén
A leghatékonyabb memória-hatékony oszlop az az oszlop, amelyből soha nem importált. Ha hatékony modellt szeretne felépíteni, nézze meg az egyes oszlopokat, és kérdezze meg magát, hogy az hozzájárul-e az elvégezni kívánt elemzéshez. Ha nem, vagy nem biztos benne, hagyja ki. Szükség esetén később is hozzáadhat új oszlopokat.
Két példa olyan oszlopokra, amelyekből mindig ki kell zárni
Az első példa egy adattárházból származó adatokra vonatkozik. Az adattárhelyen gyakori, hogy az ETL-folyamatoknak olyan eltérései vannak, amelyek a raktárban adatokat töltnek be és frissítnek. A "létrehozás dátuma", a "frissítés dátuma" és az "ETL-futtatás" hasonló oszlopok az adatok betöltésekor jön létre. Ezek közül az oszlopok közül egyikre sincs szükség a modellben, ezért az adatok importálásakor ezeket az oszlopokat üresen kell lennie.
A második példa azt jelenti, hogy kihagyja az elsődlegeskulcs-oszlopot egy ténytábla importálása során.
Sok tábla, beleértve a ténytáblákat, elsődleges kulcsokkal is van. A legtöbb tábla esetében, például az ügyfelek, alkalmazottak vagy értékesítési adatok esetében a tábla elsődleges kulcsát szeretné használni a modellben kapcsolatok létrehozásához.
A ténytáblák különböznek. Ténytáblában az elsődleges kulcs az egyes sorok egyedi azonosítására használható. Habár normalizálási célokra van szükség, kevésbé hasznos olyan adatmodell esetén, ahol csak az elemzéshez vagy a táblakapcsolatok létesítése céljából használt oszlopokat szeretné használni. Ezért a ténytáblából történő importáláskor ne szerepeljen az elsődleges kulcs. Az elsődleges kulcsok a ténytáblákban hatalmas mennyiségű helyet foglalnak el a modellben, de nem nyújtanak előnyöket, mivel nem használhatók kapcsolatok létrehozására.
Megjegyzés: Az adat raktárakban és a többdimenziós adatbázisokban a főleg numerikus adatokat tartalmazó nagyméretű táblákat gyakran "ténytábláknak" nevezik. A ténytáblák általában üzleti teljesítmény- vagy tranzakcióadatokat, például a szervezeti egységekhez, termékekhez, piaci szegmenshez, földrajzi régiókhoz és így tovább összesített értékesítési és költségadatpontokat tartalmaznak. Az adatelemzés támogatására az üzleti adatokat tartalmazó vagy más táblákban tárolt adatok kereszthivatkozásra használható összes oszlopát fel kell venni a modellbe. Az kizárni kívánt oszlop a ténytábla elsődleges kulcsoszlopa, amely olyan egyedi értékekből áll, amelyek csak a ténytáblában léteznek, máshol nem. Mivel a ténytáblák nagyon nagyok, a modellhatékonyság legnagyobb előnye abból származik, hogy kizár sorokat vagy oszlopokat a ténytáblákból.
A felesleges oszlopok kizárása
A hatékony modellek csak azokat az oszlopokat tartalmazzák, amelyekre valóban szüksége lesz a munkafüzetben. Ha szabályozni szeretné, hogy mely oszlopok tartoznak a modellbe, az adatok importálásához a Power Pivot bővítmény Tábla importálása varázslóját kell használnia az Adatok importálása párbeszédpanel helyett Excel.
Amikor elindítja a Tábla importálása varázslót, kiválaszthatja, hogy mely táblákat importálja.
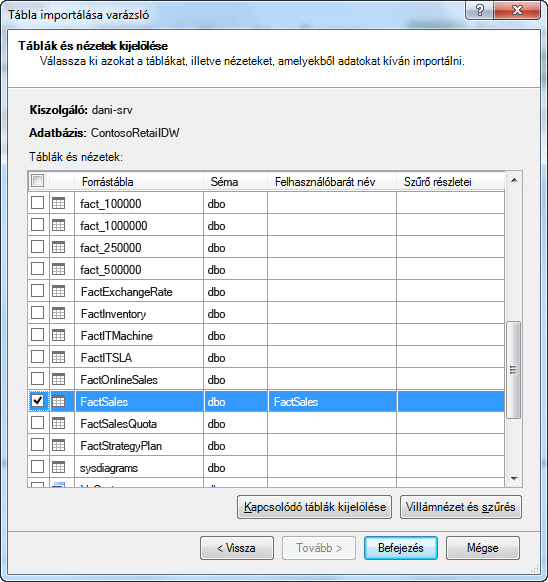
Az egyes táblázatokat a Szűrő előnézete & választva kiválaszthatja a táblázatnak azokat a részeit, amelyekre valóban szüksége van. Azt javasoljuk, hogy először törölje az összes oszlop jelölését, majd folytassa a kívánt oszlopok ellenőrzésével, miután azt fontolgatja, hogy szükségesek-e az elemzéshez.
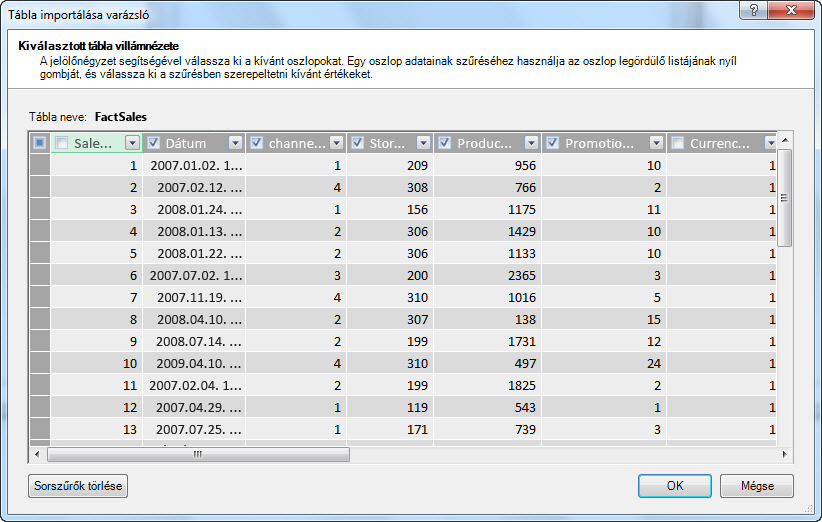
Mi a helyzet a csak a szükséges sorok szűrése esetén?
A vállalati adatbázisokban és adat raktárakban sok tábla tartalmaz hosszabb időszakra felgyakorlott előzményadatokat. Emellett azt is előfordulhat, hogy a kívánt táblák olyan üzleti területeket tartalmaznak, amelyek nem szükségesek az adott elemzéshez.
A Tábla importálása varázslóval kiszűrheti az előzmény- vagy nem kapcsolódó adatokat, így nagy helyet takaríthat meg a modellben. Az alábbi képen egy dátumszűrőt használva lehet csak az aktuális évre vonatkozó adatokat tartalmazó sorokat beolvasni, kivéve azokat az előzményadatokat, amelyekre nincs szükség.
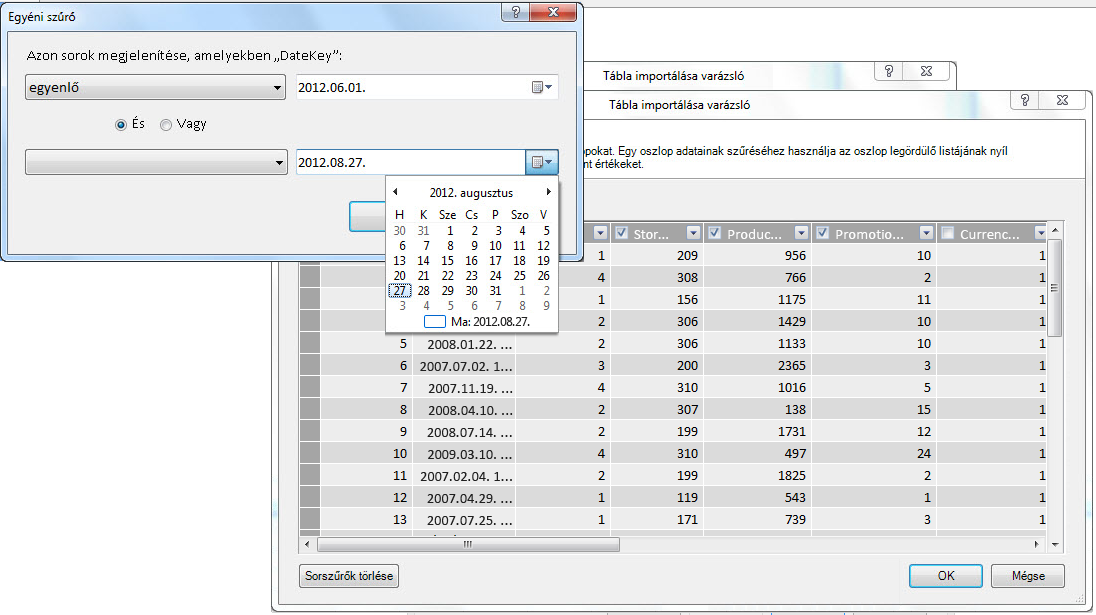
Mi történik, ha szükségünk van az oszlopra; továbbra is csökkenthetik a tárhelyköltséget?
Íme néhány további módszer, amelyek segítségével az oszlopokat tömörítésre jobb módszerre lehet alkalmazni. Ne feledje, hogy a tömörítést befolyásoló oszlop egyetlen jellemző tulajdonsága az egyedi értékek száma. Ebből a szakaszból megtudhatja, hogyan lehet néhány oszlopot módosítani az egyedi értékek számának csökkentése érdekében.
Datetime oszlopok módosítása
A Datetime oszlopok sok esetben sok helyet foglalnak el. Szerencsére számos módon csökkentheti az adattípus tárterület-követelményeit. A technikák függenek az oszlop használatától és a lekérdezések SQL szintű SQL.
A Datetime (Dátum/idő) oszlopok tartalmaznak egy dátumot és egy időpontot. Amikor megkérdezi magától, hogy szüksége van-e egy oszlopra, ugyanazt a kérdést többször is felteje egy Datetime oszlopban:
-
Szükségem van az időrészre?
-
Szükség van-e az időrészre az órák szintjén? , perc? , Másodperc? , ezredmásodperc?
-
Több Datetime oszlopom van, mert ki szeretném számítani a közöttük lévő különbséget, vagy csak az adatok összesítését év, hónap, negyedév stb. szerint.
Hogy hogyan válaszolja meg ezeket a kérdéseket, az határozza meg, hogy milyen lehetőségei vannak a Datetime oszlop kezelésére.
Ezen megoldások mindegyikéhez szükség van a lekérdezés SQL módosítására. A lekérdezések egyszerűbb módosítása érdekében minden táblában ki kell szűrni legalább egy oszlopot. Egy oszlop szűrésével rövidített formátumról (SELECT *) módosítja a lekérdezés szerkezetét egy olyan SELECT utasításra, amely teljesen minősített oszlopneveket tartalmaz, ami sokkal könnyebben módosítható.
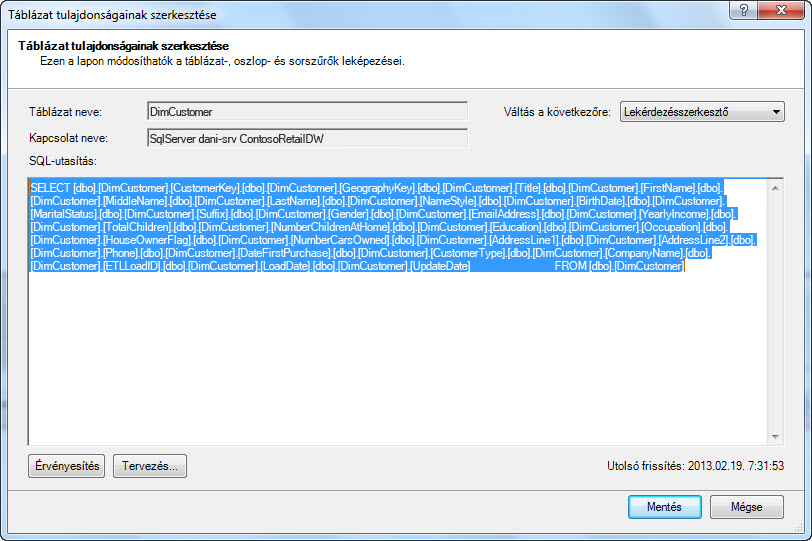
Nézzük meg az Ön számára létrehozott lekérdezéseket. A Tábla tulajdonságai párbeszédpanelen átválthat a Lekérdezésszerkesztőre, és láthatja az egyes SQL aktuális lekérdezését.

A Tábla tulajdonságai gombra, majd a Lekérdezésszerkesztő gombra.
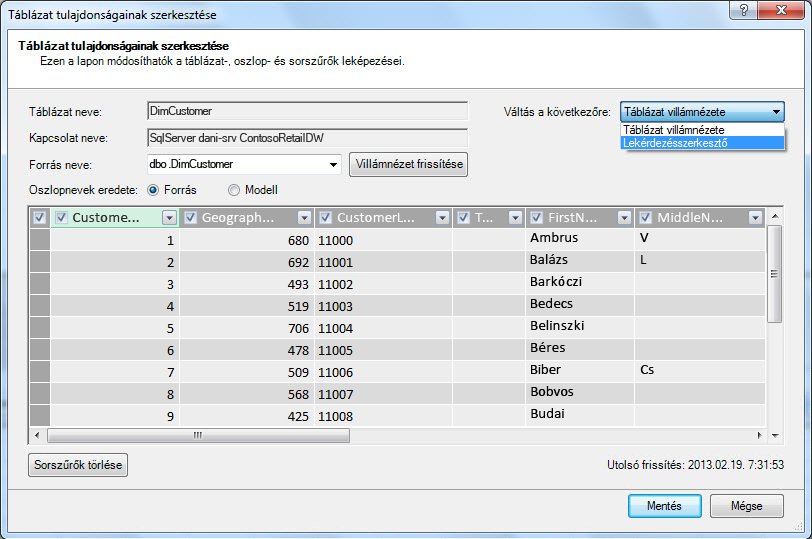
A Lekérdezésszerkesztő megjeleníti SQL tábla feltöltéséhez használt lekérdezést. Ha az importálás során kiszűrt egy oszlopot, a lekérdezés teljesen minősített oszlopneveket tartalmaz:
|
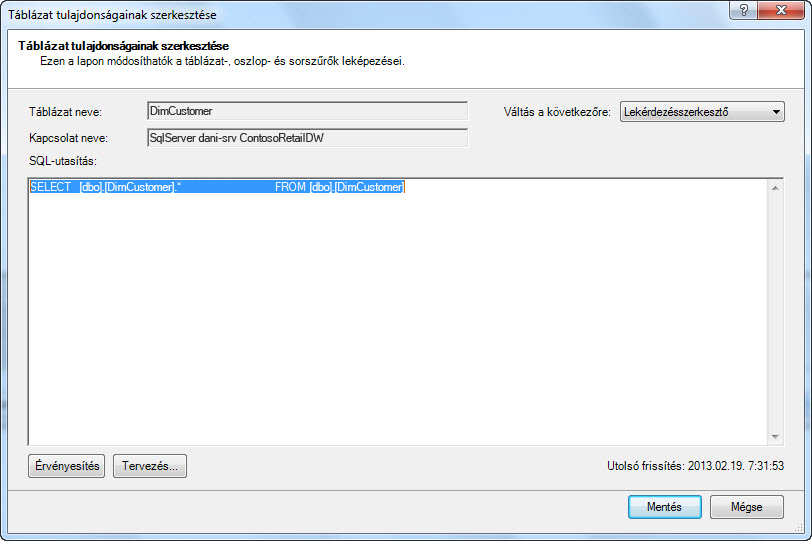
Ezzel szemben, ha teljes egészében importált egy táblát anélkül, hogy egy oszlop jelölését törölje vagy szűrőt alkalmaz, a lekérdezés a "Select * from " (Kijelölés innen) gombra fog vonatkozni, ami nehezebben módosítható:
|
A lekérdezés SQL módosítása
Most, hogy már tudja, hogyan találhatja meg a lekérdezést, módosíthatja, hogy tovább csökkentse a modell méretét.
-
A pénznemet vagy decimális adatokat tartalmazó oszlopok esetén, ha nincs szüksége a tizedesjegyek használatára, akkor a következő szintaxist használja a tizedesek eltüntetése érdekében:
"SELECT ROUND([Decimal_column_name],0)... .”
Ha a centek töredékére nincs szüksége, cserélje le a 0-t 2-re. Negatív számok használata esetén a kerekítést egységekre, tízes számra, százasra stb.
-
Ha van egy dbo nevű Datetime oszlopa. Bigtable. [Dátumidő], és nincs szüksége az Idő részre, a szintaxist használva szabaduljon meg az időtől:
"SELECT CAST (dbo. Bigtable. [Dátum idő] dátumként) AS [Dátumidő]) "
-
Ha van egy dbo nevű Datetime oszlopa. Bigtable. [Dátumidő], és mind a Dátum, mind az Idő részre szüksége van, használjon több oszlopot a SQL lekérdezésben az egyetlen Datetime oszlop helyett:
"SELECT CAST (dbo. Bigtable. [Dátumidő] mint dátum ) AS [Dátumidő],
datepart(hh, dbo. Bigtable. [Dátumidő]) as [Date Time Hours],
datepart(mi, dbo. Bigtable. [Dátumidő]) as [Date Time Minutes],
datepart(ss, dbo. Bigtable. [Dátumidő]) as [Date Time Seconds],
datepart(ms, dbo. Bigtable. [Dátumidő]) as [Date Time Milliseconds]"
Annyi oszlopot használjon, amennyit csak az egyes részeket külön oszlopokban kell tárolnia.
-
Ha órákra és percekre van szüksége, és egy oszlopként szeretné használni őket, használja a következő szintaxist:
Timefromparts(datepart(hh, dbo. Bigtable. [Dátumidő]), dátumrész(pp; dbo. Bigtable. [Dátumidő])) as [Date Time HourMinute]
-
Ha két dátum/idő oszlopra van szüksége , például a [Kezdési időpont] és a [Záró időpont] oszlopra, és valóban szüksége van a közöttük lévő időkülönbségre (másodpercek alatt) az [Időtartam] oszlopban, távolítsa el mindkét oszlopot a listából, és vegye fel a következőt:
"datediff(ss,[Start Date],[End Date]) as [Duration]"
Ha az ms kulcsszót használja az ss helyett, az időtartam ezredmásodpercben lesz meg
Számított DAX-measures használata oszlopok helyett
Ha korábban már használta a DAX kifejezésnyelvet, akkor talán már tudja, hogy a számított oszlopok a modell egy másik oszlopa alapján hoznak létre új oszlopokat, míg a számított measures meghatározása egyszer történik a modellben, de csak kimutatásban vagy más kimutatásban való használat esetén történik a kiértékelésre.
Az egyik memóriamentési módszer a normál vagy számított oszlopok számított measuresre cserélése. A klasszikus példa az Egységár, a Mennyiség és az Összeg. Ha mind a három, akkor helyet takaríthat meg, ha csak kettőt tart fenn, és a harmadikat a DAX használatával számítja ki.
Melyik 2 oszlopot érdemes megtartani?
A fenti példában tartsa meg a Mennyiség és az Egységár mezőben szereplő értékeket. E kettőnek kevesebb értéke van, mint az összegnek. Az Összeg kiszámításához vegyen fel egy számított mértéket, például:
"TotalSales:=sumx('Sales Table','Sales Table'[Unit Price]*'Sales Table'[Quantity])"
A számított oszlopok olyan normál oszlopok, amelyek mindkét esetben helyet foglalnak a modellben. Ezzel szemben a számított measures számítása a szabad terület nélkül történik.
Befejezés
Ebben a cikkben több olyan megoldásról is szó van, amelyek segíthetnek a memória-hatékonyabb modell felépítésében. Az adatmodellek fájlméret- és memóriaigényét úgy csökkentheti, hogy csökkenti az oszlopok és sorok teljes számát, valamint az egyes oszlopokban megjelenő egyedi értékek számát. Az itt szereplő technikák:
-
Az oszlopok eltávolítása természetesen a legjobb módja a hely megtakarításának. Döntse el, hogy mely oszlopokra van szüksége.
-
Néha eltávolíthat egy oszlopot, és lecserélheti egy számított mértékre a táblázatban.
-
Előfordulhat, hogy nem szükséges a táblázat összes sora. A Tábla importálása varázslóban kiszűrheti a sorokat.
-
Általánosságban elmondható, hogy ha egy oszlopot több különálló részre kell szétszedni, jó módszer egy oszlop egyedi értékeinek számának csökkentésére. Minden egyes rész kis számú egyedi értékkel fog rendelkezik, és az egyesített összeg kisebb lesz, mint az eredeti egyesített oszlop.
-
Sok esetben szüksége van a jelentések szeletelőiként használható külön részekre is. Szükség esetén hierarchiákat hozhat létre az órákból, a percekből és a másodpercekből.
-
Az oszlopok sokszor a szükségesnél több információt tartalmaznak. Tegyük fel például, hogy egy oszlop tizedeseket tárol, ön azonban formázással elrejti az összes tizedeset. A kerekítés nagyon hatékony a numerikus oszlopok méretének csökkentésében.
Most, hogy már mindent megtette, ami a munkafüzet méretének csökkentéséhez segíthet, érdemes a Munkafüzetméret-optimalizáló futtatását is fontolóra venni. Elemzi a Excel, és ha lehetséges, további tömörítést is tartalmaz. Töltse le a Workbook Size Optimizer (Munkafüzetméret-optimalizáló) gombra.
Kapcsolódó hivatkozások
Az adatmodell specifikációja és korlátozásai
Power Pivot: Hatékony adatelemzés és adatmodellezés az Excelben









