
מאמר זה מתאר את תחביר הנוסחה של הפונקציה LINEST ואת השימוש בה ב- Microsoft Excel. חפש קישורים למידע נוסף אודות יצירת תרשימים וביצוע ניתוח רגרסיה בסעיף למידע נוסף.
תיאור
הפונקציה LINEST מחשבת סטטיסטיקה עבור קו מסוים בשיטת "הריבועים הפחותים" כדי להגיע לקו הישר התואם ביותר לנתונים, ולאחר מכן מחזירה מערך המתאר את הקו. ניתן גם לשלב את LINEST עם פונקציות אחרות כדי לחשב את הסטטיסטיקה של סוגים אחרים של מודלים ליניאריים בפרמטרים הלא ידועים, כולל סדרות פולינומיאליות, סדרות לוגריתמיות, סדרות מעריכיות וסדרות של חזקות. כיוון שפונקציה זו מחזירה מערך של ערכים, יש להזין אותה כנוסחת מערך. ההוראות מופיעות לאחר הדוגמאות במאמר זה.
המשוואה עבור הקו היא:
y = mx + b
-לחלופין-
y = m1x1 + m2x2 + ... + b
אם קיימים טווחים מרובים של ערכי x, כאשר ערכי y התלויים הם פונקציה של ערכי x הבלתי תלויים. ערכי m הם המקדמים התואמים לכל ערך x, ואילו b הוא ערך קבוע. שים לב ש- y, x ו- m עשויים להיות וקטורים. המערך שהפונקציה LINEST מחזירה הוא {mn,mn-1,...m1,b}. כמו כן, הפונקציה LINEST יכולה להחזיר סטטיסטיקת רגרסיה נוספת.
תחביר
LINEST(known_y's, [known_x's], [const], [stats])
תחביר הפונקציה LINEST מכיל את הארגומנטים הבאים:
תחביר
-
known_y's נדרש. ערכה של ערכי y שכבר ידועים בקשר הגומלין y = mx + b.
-
אם הטווח של known_y's נמצא בעמודה בודדת, כל עמודה של known_x's תתפרש כמשתנה נפרד.
-
אם הטווח של known_y's נמצא בשורה בודדת, כל שורה של known_x's תתפרש כמשתנה נפרד.
-
-
known_x's אופציונלי. ערכה של ערכי x שייתכן שכבר ידועים בקשר הגומלין y = mx + b.
-
הטווח של known_x's יכול לכלול ערכה אחת או יותר של משתנים. אם נעשה שימוש במשתנה אחד בלבד, known_y's ו- known_x's יכולים להיות טווחים בכל צורה שהיא, כל עוד יש להם ממדים שווים. אם נעשה שימוש ביותר ממשתנה אחד, known_y's חייב להיות וקטור (כלומר, טווח בגובה של שורה אחת או ברוחב של עמודה אחת).
-
אם known_x's מושמט, המערכת מניחה כי הוא המערך {1,2,3,...} באותו הגודל כמו known_y's.
-
-
const אופציונלי. ערך לוגי המציין אם לכפות על הקבוע b להיות שווה ל- 0.
-
אם const הוא TRUE או מושמט, b מחושב כרגיל.
-
אם const הוא FALSE, b מוגדר כשווה ל- 0 וערכי m מותאמים לקשר הגומלין y = mx.
-
-
stats אופציונלי. ערך לוגי המציין אם להחזיר סטטיסטיקת רגרסיה נוספת.
-
אם stats הוא TRUE, הפונקציה LINEST מחזירה את סטטיסטיקת הרגרסיה הנו נוספת; כתוצאה מכך, המערך המוחזר הוא {mn,mn-1,...,m1,b; sen,sen-1,...,se1, seb; r2,sey; F,df; ssreg,ssresid}.
-
אם stats הוא FALSE או מושמט, הפונקציה LINEST מחזירה רק את מקדמי m ואת הקבוע b.
סטטיסטיקת הרגרסיה הנוספת היא:
-
|
נתון סטטיסטי |
תיאור |
|---|---|
|
se1,se2,...,sen |
ערכי שגיאת התקן עבור המקדמים m1,m2...,mn. |
|
seb |
ערך השגיאה הרגיל עבור הקבוע b (seb = #N/A כאשר const הוא FALSE). |
|
ש"ח 2 |
מקדם הקביעה. השוואה בין ערכי y משוערים וממשיים, וכן טווחים בערכים החל מ- 0 ועד 1. אם הערך הוא 1, קיים מתאם מושלם במדגם - אין הבדל בין ערך y המשוער לבין ערך y הממשי. מנגד, אם מקדם הקביעה הוא 0, נוסחת הרגרסיה אינה שימושית לחיזוי ערך y. לקבלת מידע אודות אופן החישובשל 2 , ראה "הערות" בהמשך נושא זה. |
|
sey |
שגיאת התקן עבור y המשוער. |
|
F |
הנתון הסטטיסטי F, או ערך F שנצפה. השתמש בנתון הסטטיסטי F כדי לקבוע אם קשר הגומילן שנצפה בין המשתנים התלויים והבלתי תלויים הוא מקרי. |
|
df |
דרגות החופש. השתמש בדרגות החופש כדי לחפש ערכי F קריטיים בטבלה סטטיסטית. השווה את הערכים שנמצאו בטבלה לנתון הסטטיסטי F שהחזירה הפונקציה LINEST כדי לקבוע רמת מהימנות למודל. לקבלת מידע אודות אופן החישוב של df, עיין בסעיף "הערות" בהמשך נושא זה. דוגמה 4 מציגה את השימוש ב- F וב- df. |
|
ssreg |
סכום הרגרסיה של ריבועים. |
|
ssresid |
סכום ריבועי השאריות. לקבלת מידע אודות אופן החישוב של ssreg ו- ssresid, עיין בסעיף "הערות" בהמשך נושא זה. |
האיור הבא מציג את הסדר שבו מוחזרת סטטיסטיקת הרגרסיה הנוספת.

הערות
-
באפשרותך לתאר כל קו ישר באמצעות השיפוע וחיתוך y:
Slope (m):
כדי למצוא את השיפוע של קו, שנכתב לעתים קרובות כ- m, קח שתי נקודות על הקו (x1,y1) ו- (x2,y2); השיפוע שווה ל- (y2 - y1)/(x2 - x1).חיתוך Y (b):
יירוט ה- y של שורה, שנכתב לעתים קרובות כ- b, הוא הערך של y בנקודה שבה הקו חוצה את ציר ה- y.המשוואה של קו ישר היא y = mx + b. לאחר שהערכים של m ושל b ידועים, תוכל לחשב כל נקודה בקו על-ידי הצבת ערך y או ערך x במשוואה זו. ניתן גם להשתמש בפונקציה TREND.
-
כאשר יש משתנה x בלתי תלוי אחד בלבד, ניתן לחשב את ערכי השיפוע וחיתוך y ישירות באמצעות הנוסחאות הבאות:
מדרון:
=INDEX(LINEST(known_y's,known_x's),1)יירוט Y:
=INDEX(LINEST(known_y's,known_x's),2) -
מידת הדיוק של הקו שהפונקציה LINEST מחשבת תלויה בדרגת הפיזור של הנתונים. ככל שהנתונים ליניאריים יותר, כך מידת הדיוק של מודל LINEST גבוהה יותר. הפונקציה LINEST משתמשת בשיטת הריבועים הקטנים ביותר לקביעת ההתאמה הטובה ביותר לנתונים. כאשר יש משתנה x בלתי תלוי אחד בלבד, החישוב של m ו- b מבוסס על הנוסחאות הבאות:
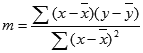
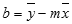
כאשר x ו- y הם אמצעי מדגם; that is, x = AVERAGE(known x's) and y = AVERAGE(known_y's).
-
הפונקציות LINE- ו- Curve-Fitting LINEST ו- LOGEST יכולות לחשב את הקו הישר או העקומה המעריכית הטובים ביותר המתאימים לנתונים שלך. עם זאת, עליך להחליט איזו משתי התוצאות מתאימה בצורה הטובה ביותר לנתונים שלך. באפשרותך לחשב TREND(known_y's,known_x's) עבור קו ישר, או GROWTH(known_y's, known_x's) עבור עקומה מעריכית. פונקציות אלה, ללא הארגומנט new_x , מחזירות מערך של ערכי y החזויים לאורך קו זה או בעקומה בנקודות הנתונים בפועל. לאחר מכן תוכל להשוות את הערכים החזויים לערכים בפועל. ייתכן שתרצה ליצור תרשים של שניהם להשוואה חזותית.
-
בניתוח רגרסיה, Excel מחשב עבור כל נקודה את ריבוע ההפרש בין ערך y המשוער של אותה נקודה לבין ערך y הממשי. סכום ריבועי ההפרשים נקרא סכום ריבועי השאריות, ssresid. לאחר מכן, Excel מחשב את הסכום הכולל של הריבועים, sstotal. כאשר הארגומנט const שווה ל- TRUE או מושמט, הסכום הכולל של הריבועים הוא סכום ריבועי ההפרשים בין ערכי y הממשיים לבין ממוצע ערכי y. כאשר הארגומנט const שווה ל- FALSE, סכום הריבועים הכולל הוא סכום הריבועים של ערכי y הממשיים (מבלי לחסר את ערך y הממוצע מכל ערך y בודד). לאחר מכן, סכום הרגרסיה של הריבועים, ssreg, ניתן לחישוב באמצעות: ssreg = sstotal - ssresid. הסכום השיריד של הריבועים קטן יותר בהשוואה לסכום הריבועים הכולל, כך גדל הערך של מקדם הקביעה, r2, שהוא סימן לאופן שבו המשוואה המתרחבת כתוצאה מניתוח הרגרסיה מסבירה את הקשר בין המשתנים. הערך של r2 שווה ל- ssreg/sstotal.
-
במקרים מסוימים, ייתכן שלעמודת X אחת או יותר (נניח שמשתני Y ו- X נמצאים בעמודות) אין ערך חיזוי נוסף בנוכחות עמודות X האחרות. במילים אחרות, הוצאת עמודת X אחת או יותר עשויה להוביל לערכי Y חזויים מדויקים באותה מידה. במקרה זה, יש להשמיט עמודות X עודפות אלה ממודל הרגרסיה. תופעה זו מכונה "קוליניאריות" משום שניתן לבטא כל עמודת X עודפת כסכום מכפלות של עמודות X שאינן עודפות. הפונקציה LINEST בודקת קוליניאריות ומסירה עמודות X עודפות ממודל הרגרסיה כשהיא מזהה אותן. ניתן לזהות עמודות X שהוסרו בפלט LINEST כבעלות 0 מקדמים, בנוסף ל- 0 ערכי se. אם מתבצעת הסרה של עמודה עודפת אחת או יותר, df מושפע כיוון ש- df תלוי במספר עמודות X המשמשות בפועל למטרות חיזוי. לקבלת פרטים אודות חישוב df, ראה דוגמה 4. אם df משתנה משום שעמודות X עודפות הוסרו, ערכי sey ו- F מושפעים גם הם. בפועל, קוליניאריות אמורה להיות נדירה יחסית. עם זאת, מקרה אחד שבו הסבירות שלה עולה הוא כאשר עמודות X מסוימות מכילות רק ערכי 0 ו- 1 כמחוונים לגבי היותו או אי-היותו של משתתף בניסוי חבר בקבוצה מסוימת. אם const שווה ל- TRUE או מושמט, הפונקציה LINEST מוסיפה עמודת X נוספת של כל ערכי 1 כדי להדגים את נקודת החיתוך. אם יש עמודה עם ערך 1 עבור כל משתתף כדי לציין שהוא זכר, או 0 אם לא, וכן אם יש עמודה עם ערך 1 עבור כל משתתף כדי לציין שהוא נקבה, או 0 אם לא, עמודה אחרונה זו עודפת כיוון שניתן להשיג את הערכים שבה על-ידי חיסור הערך בעמודה "מחוון זכר" מהערך בעמודה הנוספת של כל ערכי 1 שנוספו על-ידי הפונקציה LINEST.
-
הערך של df מחושב באופן הבא כאשר לא מתבצעת הסרה של עמודות X כלשהן מהמודל בשל קוליניאריות: אם יש k עמודות של known_x’s ו- const הוא TRUE או מושמט, df = n – k – 1. אם const הוא FALSE, df = n - k. בשני המקרים, כל עמודת X שהוסרה בשל קוליניאריות מגדילה את הערך של df ב- 1.
-
בעת הזנת קבוע מערך (כגון known_x's) כארגומנט, השתמש בפסיקים כדי להפריד בין ערכים הכלולים באותה שורה ובתווי נקודה-פסיק כדי להפריד בין שורות. תווי ההפרדה עשויים להשתנות בהתאם להגדרות האזוריות.
-
שים לב שייתכן שערכי y שמנבאת משוואת הרגרסיה לא יהיו בתוקף אם הם נמצאים מחוץ לטווח ערכי y שבו השתמשת לקביעת המשוואה.
-
האלגוריתם המשמש כבסיס בפונקציה LINEST שונה מהאלגוריתם המשמש כבסיס בפונקציות SLOPE ו- INTERCEPT. ההבדל בין אלגוריתמים אלה עשוי להוביל לתוצאות שונות כאשר הנתונים אינם ידועים וקוליניאריים. לדוגמה, אם נקודות הנתונים של הארגומנט known_y's הן 0 ונקודות הנתונים של הארגומנט known_x's הן 1:
-
הפונקציה LINEST מחזירה ערך 0. האלגוריתם של הפונקציה LINEST נועד להחזיר תוצאות סבירות עבור נתונים קוליניאריים, ובמקרה זה ניתן למצוא לפחות תשובה אחת.
-
הפונקציות SLOPE ו- INTERCEPT מחזירות #DIV/0! שגיאת #REF!. האלגוריתם של הפונקציות SLOPE ו- INTERCEPT נועד לחפש תשובה אחת בלבד. במקרה זה, יכולה להיות יותר מתשובה אחת.
-
-
בנוסף לשימוש ב- LOGEST לחישוב סטטיסטיקה עבור סוגי רגרסיה אחרים, באפשרותך להשתמש ב- LINEST לחישוב טווח של סוגי רגרסיה אחרים על-ידי הזנת פונקציות של משתני x ו- y כסדרות x ו- y עבור LINEST. לדוגמה, הנוסחה הבאה:
=LINEST(yvalues, xvalues^COLUMN($A:$C))
פועלת כאשר יש עמודה יחידה של ערכי y ועמודה יחידה של ערכי x לחישוב התוצאה המעוקבת (פולינומיאלית מסדר 3) בקירוב של התבנית:
y = m1*x + m2*x^2 + m3*x^3 + b
באפשרותך להתאים נוסחה זו לחישוב סוגים אחרים של רגרסיה, אך במקרים מסוימים יש צורך להתאים את ערכי הפלט וסטטיסטיקה אחרת.
-
קיים הבדל בין ערכי מבחן F שמחזירה הפונקציה LINEST לערכי מבחן F שמחזירה הפונקציה FTEST. הפונקציה LINEST מחזירה את הנתון הסטטיסטי F, בעוד שהפונקציה FTEST מחזירה את ההסתברות.
דוגמאות
דוגמה 1 - שיפוע וחיתוך Y
העתק את נתוני הדוגמה מהטבלה שלהלן והדבק אותם בתא A1 בגליון עבודה חדש של Excel. כדי שהנוסחאות יציגו תוצאות, בחר אותן, הקש F2 ולאחר מכן הקש Enter. אם יש צורך, באפשרותך להתאים את רוחב העמודות כדי לראות את כל הנתונים.
|
y ידוע |
x ידוע |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
תוצאה (שיפוע) |
תוצאה (נקודת חיתוך y) |
|
2 |
1 |
|
נוסחה (נוסחת מערך בתאים A7:B7) |
|
|
=LINEST(A2:A5,B2:B5,,FALSE) |
דוגמה 2 - רגרסיה ליניארית פשוטה
העתק את נתוני הדוגמה מהטבלה שלהלן והדבק אותם בתא A1 בגליון עבודה חדש של Excel. כדי שהנוסחאות יציגו תוצאות, בחר אותן, הקש F2 ולאחר מכן הקש Enter. אם יש צורך, באפשרותך להתאים את רוחב העמודות כדי לראות את כל הנתונים.
|
חודש |
מכירות |
|---|---|
|
1 |
₪3,100 |
|
2 |
₪4,500 |
|
3 |
₪4,400 |
|
4 |
₪5,400 |
|
5 |
₪7,500 |
|
6 |
₪8,100 |
|
נוסחה |
תוצאה |
|
=SUM(LINEST(B1:B6, A1:A6)*{9,1}) |
₪11,000 |
|
חישוב הערכת המכירות בחודש התשיעי, בהתבסס על המכירות בחודשים 1 עד 6. |
דוגמה 3 - רגרסיה ליניארית רבת-משתנים
העתק את נתוני הדוגמה מהטבלה שלהלן והדבק אותם בתא A1 בגליון עבודה חדש של Excel. כדי שהנוסחאות יציגו תוצאות, בחר אותן, הקש F2 ולאחר מכן הקש Enter. אם יש צורך, באפשרותך להתאים את רוחב העמודות כדי לראות את כל הנתונים.
|
שטח קומה (x1) |
משרדים (x2) |
כניסות (x3) |
גיל (x4) |
אומדן ערך (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
₪142,000 |
|
2333 |
2 |
2 |
12 |
₪144,000 |
|
2356 |
3 |
1.5 |
33 |
₪151,000 |
|
2379 |
3 |
2 |
43 |
₪150,000 |
|
2402 |
2 |
3 |
53 |
₪139,000 |
|
2425 |
4 |
2 |
23 |
₪169,000 |
|
2448 |
2 |
1.5 |
99 |
₪126,000 |
|
2471 |
2 |
2 |
34 |
₪142,900 |
|
2494 |
3 |
3 |
23 |
₪163,000 |
|
2517 |
4 |
4 |
55 |
₪169,000 |
|
2540 |
2 |
3 |
22 |
₪149,000 |
|
-234.2371645 |
||||
|
13.26801148 |
||||
|
0.996747993 |
||||
|
459.7536742 |
||||
|
1732393319 |
||||
|
נוסחה (נוסחת מערך דינאמית שהוזנה ב- A19) |
||||
|
=LINEST(E2:E12,A2:D12,TRUE,TRUE) |
דוגמה 4 - שימוש בסטטיסטיקה F ו- r 2
בדוגמה הקודמת, מקדם הקביעה, או r2, הוא 0.99675 (ראה תא A17 בפלט עבור LINEST), אשר יציין קשר גומלין חזק בין המשתנים הבלתי תלויים לבין מחיר המכירה. באפשרותך להשתמש בנתון הסטטיסטי F כדי לקבוע אם תוצאות אלה, כאשר ערך r2 כה גבוה, הן מקריות.
נניח לרגע שלמעשה אין קשר בין המשתנים, אלא שהמדגם בן 11 בנייני המשרדים שנבחר הוא מדגם נדיר הגורם לניתוח הסטטיסטי להראות קשר הדוק. המונח "Alpha" משמש לציון ההסתברות של היסק שגוי שלפיו יש קשר.
ניתן להשתמש בערכי F ו- df בפלט מהפונקציה LINEST כדי להעריך את הסבירות של ערך F גבוה יותר המתרחש במקרה. ניתן להשוות את F לערכים קריטיים בטבלאות התפלגות F שפורסמו או להשתמש בפונקציה FDIST ב- Excel לחישוב ההסתברות של ערך F גדול יותר המתרחש במקרה. התפלגות F המתאימה כוללת דרגות חופש של v1 ו- v2. אם n הוא מספר נקודות הנתונים והארגומנטים = TRUE או מושמט, v1 = n – df – 1 ו- v2 = df. (אם const = FALSE, אז v1 = n – df ו- v2 = df.) הפונקציה FDIST — עם התחביר FDIST(F,v1,v2) - תחזיר את ההסתברות של ערך F גבוה יותר המתרחש במקרה. בדוגמה זו, df = 6 (תא B18) ו- F = 459.753674 (תא A18).
בהנחה שערך Alpha הוא 0.05, v1 = 11 – 6 – 1 = 4 ו- v2 = 6, הרמה הקריטית של F היא 4.53. מאחר ש- F = 459.753674 גבוה בהרבה מ- 4.53, סביר ביותר שערך F כזה גבוה במקרה. (עם Alpha = 0.05, ההיפותזה שאין קשרי גומלין בין known_y לביןknown_x של known_x תידחה כאשר F חורג מהרמה הקריטית, 4.53.) באפשרותך להשתמש בפונקציה FDIST ב - Excel כדי לקבל את ההסתברות שערך F כערך גבוה זה אירע במקרה. לדוגמה, FDIST(459.753674, 4, 6) = 1.37E-7, הסתברות קטנה במיוחד. באפשרותך לסיים זאת על-ידי איתור הרמה הקריטית של F בטבלה או באמצעות הפונקציה FDIST , שמשוואה הרגרסיה שימושית בחיזוי הערך המוערך של בנייני משרדים באזור זה. זכור כי חיוני להשתמש בערכים הנכונים של v1 ו- v2 שחושבו בפיסקה הקודמת.
דוגמה 5 - חישוב נתוני t
מבחן השערה נוסף קובע אם כל אחד ממקדמי השיפוע שימושי לאומדן הערך המשוער של בניין משרדים מדוגמה 3. לדוגמה, כדי לבדוק מובהקות סטטיסטית במקדם הגיל, חלק את -234.24 (מקדם שיפוע הגיל) ב- 13.268 (שגיאת התקן המשוערת למקדמי גיל בתא A15). הנה ערך t שנצפה:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
אם הערך המוחלט של t גבוה מספיק, ניתן להסיק שמקדם השיפוע שימושי באומדן הערך המשוער של בניין משרדים בדוגמה 3. הטבלה הבאה מציגה את הערכים המוחלטים של 4 ערכי t שנצפו.
אם תעיין בטבלה במדריך סטטיסטיקה, תגלה שהערך של t קריטי ודו-זנבי, עם 6 דרגות חופש ו- Alpha = 0.05 הוא 2.447. ניתן למצוא ערך קריטי זה גם באמצעות הפונקציה TINV ב- Excel. TINV(0.05,6) = 2.447. כיוון שהערך המוחלט של t (17.7) גדול מ- 2.447, גיל הוא משתנה חשוב באומדן של הערך המשוער של בנייני משרדים. ניתן לבחון את המובהקות הסטטיסטית של כל אחד מהמשתנים הבלתי תלויים האחרים באופן דומה. להלן ערכי t שנצפו עבור כל אחד מהמשתנים הבלתי תלויים.
|
משתנה |
ערך t שנצפה |
|---|---|
|
שטח קומה |
5.1 |
|
מספר משרדים |
31.3 |
|
מספר כניסות |
4.8 |
|
גיל |
17.7 |
לכל הערכים האלה יש ערך מוחלט גדול מ- 2.447; לפיכך, כל המשתנים המשמשים במשוואת הרגרסיה מועילים לחיזוי השווי המוערך של בנייני משרדים באזור זה.









