
Dans Excel 2013 ou une ultérieure, vous pouvez créer des modèles de données contenant des millions de lignes, puis effectuer de puissantes analyses de données sur ces modèles. Les modèles de données peuvent être créés avec ou sans le complément Power Pivot pour permettre la prise en charge de tableaux croisés dynamiques, de graphiques et de visualisations Power View au sein du même classeur.
Remarque : Cet article décrit les modèles de données disponibles Excel 2013. Toutefois, les mêmes fonctionnalités de modélisation des données et de Power Pivot introduites dans Excel 2013 s’appliquent également Excel 2016. Il existe effectivement peu de différences entre ces versions de Excel.
Bien que vous puissiez facilement créer d’imposants modèles de données dans Excel, il existe plusieurs raisons de ne pas le faire. Premièrement, les modèles de grande taille qui contiennent une multitude de tables et de colonnes sont trop complexes pour la plupart des analyses et produisent une liste de champs encombrante. Deuxièmement, les modèles de grande taille utilisent une quantité importante de mémoire, ce qui affecte négativement les autres applications et rapports qui partagent les mêmes ressources système. Enfin, dans Microsoft 365, SharePoint Online et Excel Web App limitent la taille d’un Excel à 10 Mo. Pour les modèles de données de classeurs qui contiennent des millions de lignes, la limite des 10 Mo est rapidement atteinte. Voir Spécification et limites du modèle de données.
Dans cet article, vous allez apprendre à créer un modèle optimal, plus simple à utiliser et qui consomme moins de mémoire. Prendre le temps d’apprendre les meilleures pratiques en matière de conception de modèles efficaces sera payant par la suite pour tout modèle que vous créez et utilisez, que vous l’affichez dans Excel 2013, Microsoft 365 SharePoint Online, sur Office Web Apps Server ou dans SharePoint 2013.
Vous pouvez également exécuter l’optimiseur de la taille des classeurs. Il analyse votre classeur Excel et si possible, le compresse davantage. Téléchargez l’optimiseur de la taille des fichiers de travail.
Contenu de cet article
Taux de compression et moteur d’analyse en mémoire
Les modèles de données Excel utiliser le moteur d’analyse en mémoire pour stocker les données en mémoire. Le moteur implémente de puissantes techniques de compression pour réduire les besoins de stockage, en réduisant un jeu de résultats jusqu’à ce qu’il soit une fraction de sa taille d’origine.
En moyenne, la taille d’un modèle de données peut être jusqu’à 7 ou 10 fois plus petite que la taille des mêmes données à l’origine. Par exemple, si vous importez 7 Mo de données à partir d’une base de données SQL Server, le modèle de données dans Excel peut facilement correspondre à 1 Mo, voire moins. Le degré de compression réellement atteint dépend essentiellement du nombre de valeurs uniques dans chaque colonne. Plus les valeurs uniques sont nombreuses, plus la mémoire nécessaire à leur stockage est importante.
Pourquoi parlons-nous de compression et de valeurs uniques ? La création d’un modèle efficace qui minimise l’utilisation de mémoire est une question d’optimisation de compression. Le moyen le plus simple d’y arriver consiste à supprimer toutes les colonnes dont vous n’avez pas vraiment besoin, en particulier si celles-ci incluent un grand nombre de valeurs uniques.
Remarque : Les différences de besoins en matière de stockage pour des colonnes individuelles peuvent être énormes. Dans certains cas, il est préférable d’avoir plusieurs colonnes avec un petit nombre de valeurs uniques plutôt qu’une seule colonne avec un grand nombre de valeurs uniques. La section consacrée à l’optimisation de Datetime aborde cette technique en détail.
Rien ne vaut une colonne inexistante pour réduire l’utilisation de la mémoire
La colonne la plus économe en mémoire est celle que vous n’avez jamais importée. Si vous voulez créer un modèle efficace, examinez chaque colonne et demandez-vous si elle contribue à l’analyse que vous souhaitez effectuer. Si ce n’est pas le cas ou si vous en doutez, abstenez-vous. Vous pourrez toujours ajouter de nouvelles colonnes plus tard, si vous en avez besoin.
Deux exemples de colonnes qui doivent toujours être exclues
Le premier exemple porte sur des données qui proviennent d’un entrepôt de données. Dans un entrepôt de données, il est courant de trouver des artefacts de processus ETL qui chargent et actualisent les données dans l’entrepôt. Les colonnes telles que celles qui sont relatives à la « date de création », la « date de mise à jour » et l’« exécution ETL » sont créées quand les données sont chargées. Aucune de ces colonnes n’étant nécessaire dans le modèle, celles-ci doivent être désélectionnées quand vous importez des données.
Le second exemple implique l’omission de la colonne clé primaire durant l’importation d’une table de faits.
De nombreuses tables, notamment les tables de faits, ont des clés primaires. Pour la plupart des tables, par exemple celles qui contiennent des données relatives aux clients, aux employés ou aux ventes, vous souhaiterez disposer de la clé primaire de la table pour pouvoir créer des relations dans le modèle.
Les tables de faits sont différentes. Dans une table de faits, la clé primaire est utilisée pour identifier chaque ligne de façon unique. Bien que cet aspect soit nécessaire en matière de normalisation, cela est moins utile dans un modèle de données où vous voulez uniquement que les colonnes soient utilisées à des fins d’analyse ou pour établir des relations entre les tables. Pour cette raison, durant l’importation d’une table de faits, n’incluez pas sa clé primaire. Les clés primaires d’une table de faits occupent beaucoup d’espace dans le modèle mais ne présentent aucun avantage, car elles ne peuvent pas être utilisées pour créer des relations.
Remarque : Dans les entrepôts de données et les bases de données multidimensionnelles, les grandes tables composées principalement de données numériques sont souvent appelées « tables de faits ». Les tables de faits incluent généralement des données sur les performances ou les transactions, telles que les points de données des ventes et des coûts qui sont agrégés et alignés sur les unités organisationnelles, les produits, les segments de marché, les régions géographiques, etc. Toutes les colonnes d’une table de faits qui contiennent des données métiers ou qui peuvent être utilisées pour faire un renvoi aux données stockées dans d’autres tables doivent être incluses dans le modèle pour prendre en charge l’analyse des données. La colonne que vous voulez exclure est la colonne clé primaire de la table de faits, qui se compose de valeurs uniques qui existent uniquement dans la table de faits. Étant donné que les tables de faits sont extrêmement grandes, certains des gains les plus importants en matière d’efficacité des modèles sont dérivés de l’exclusion des lignes ou colonnes de tables de faits.
Comment exclure les colonnes inutiles
Les modèles efficaces contiennent uniquement les colonnes dont vous avez réellement besoin dans votre classeur. Si vous souhaitez contrôler le choix des colonnes incluses dans le modèle, vous devez utiliser l’Assistant Importation de table dans le complément Power Pivot pour importer les données au lieu de la boîte de dialogue « Importer des données » dans Excel.
Quand vous démarrez l’Assistant Importation de table, vous sélectionnez les tables à importer.
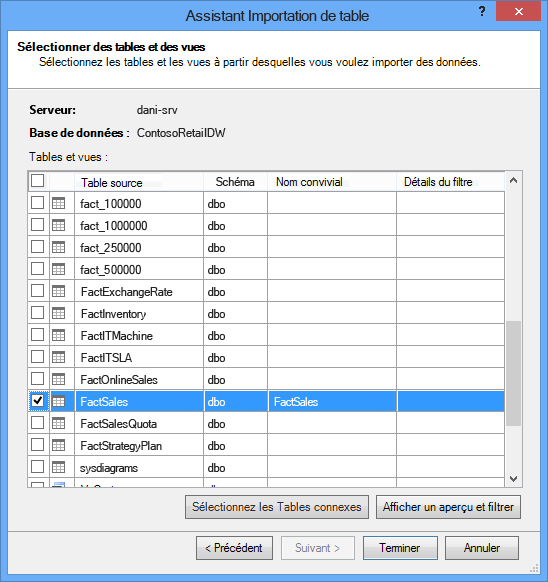
Pour chaque table, vous pouvez cliquer sur Afficher un aperçu et filtrer, puis sélectionner les parties de la table dont vous avez vraiment besoin. Nous vous recommandons de désactiver d’abord les cases à cocher de toutes les colonnes, puis d’activer les cases à cocher des colonnes souhaitées, après avoir déterminé si elles sont nécessaires à l’analyse.
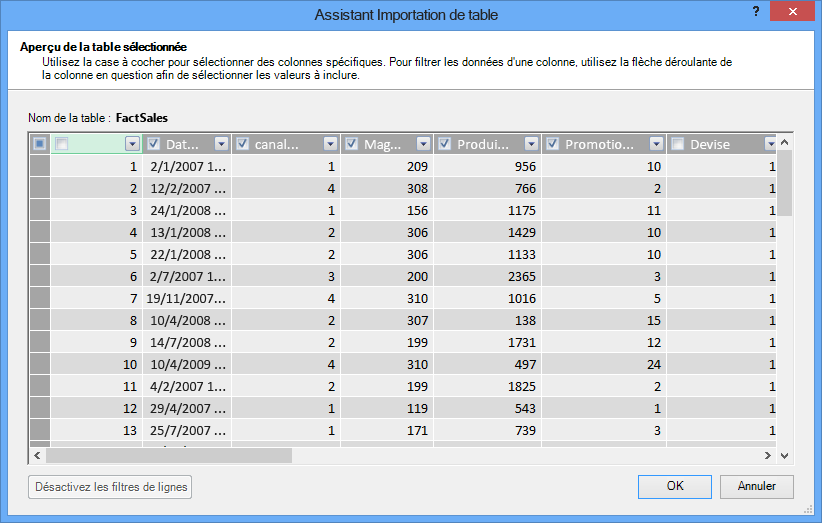
Qu’en est-il du filtrage des lignes nécessaires uniquement ?
De nombreuses tables de bases de données et d’entrepôts de données d’entreprises contiennent des données historiques accumulées sur de longues périodes. En outre, vous constaterez peut-être que les tables qui vous intéressent contiennent des informations sur des domaines de l’entreprise qui ne sont pas nécessaires pour votre analyse spécifique.
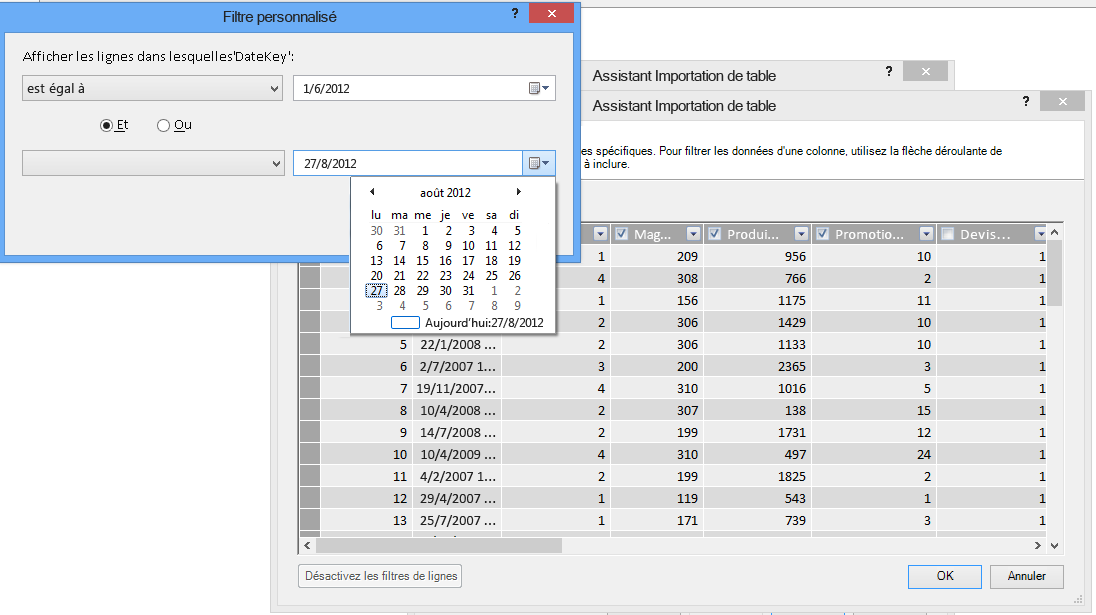
À l’aide de l’Assistant Importation de table, vous pouvez filtrer les données historiques ou les données non liées, et donc gagner beaucoup d’espace dans le modèle. Dans l’image suivante, un filtre de date est utilisé pour récupérer uniquement les lignes qui contiennent les données de l’année actuelle, en excluant les données historiques non nécessaires.
Si nous avons besoin de la colonne, pouvons-nous tout de même réduire l’espace qu’elle occupe ?
Il existe quelques techniques supplémentaires que vous pouvez appliquer pour optimiser la compression d’une colonne. N’oubliez pas que la seule caractéristique de la colonne qui affecte la compression est le nombre de valeurs uniques. Dans cette section, vous apprendrez à modifier certaines colonnes pour réduire le nombre de valeurs uniques.
Modification des colonnes Datetime
Dans de nombreux cas, les colonnes Datetime occupent beaucoup d’espace. Heureusement, il existe un certain nombre de méthodes qui permettent de réduire les besoins de stockage pour ce type de données. Les techniques varient en fonction de la façon dont vous utilisez la colonne et de votre niveau d’expertise en matière de création de requêtes SQL.
Les colonnes Datetime comprennent une partie date et une partie heure. Quand vous vous demandez si vous avez besoin d’une colonne, posez-vous la même question à plusieurs reprises pour une colonne Datetime :
-
Ai-je besoin de la partie date ?
-
Ai-je besoin de la partie heure au niveau des heures ? , des minutes ? , Secondes ? , millisecondes ?
-
Ai-je besoin de plusieurs colonnes Datetime pour calculer la différence qui existe entre elles ou tout simplement pour agréger les données par année, par mois, par trimestre, etc.
La façon dont vous répondez à chacune de ces questions détermine vos options en matière de gestion d’une colonne Datetime.
Toutes ces solutions nécessitent la modification d’une requête SQL. Pour faciliter la modification des requêtes, filtrez au moins une colonne de chaque table. Grâce au filtrage d’une colonne, vous changez la construction des requêtes en passant d’un format abrégé (SELECT *) à une instruction SELECT qui comprend des noms de colonnes complets, lesquels sont beaucoup plus faciles à modifier.
Examinons les requêtes créées pour vous. Dans la boîte de dialogue Propriétés de la table, vous pouvez passer à l’Éditeur de requête afin de voir la requête SQL active pour chaque table.
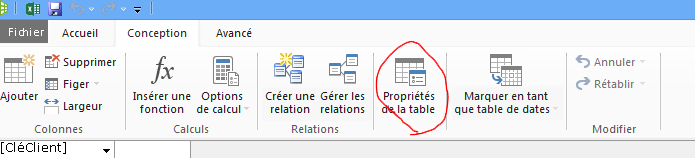
Dans Propriétés de la table, sélectionnez Éditeur de requête.
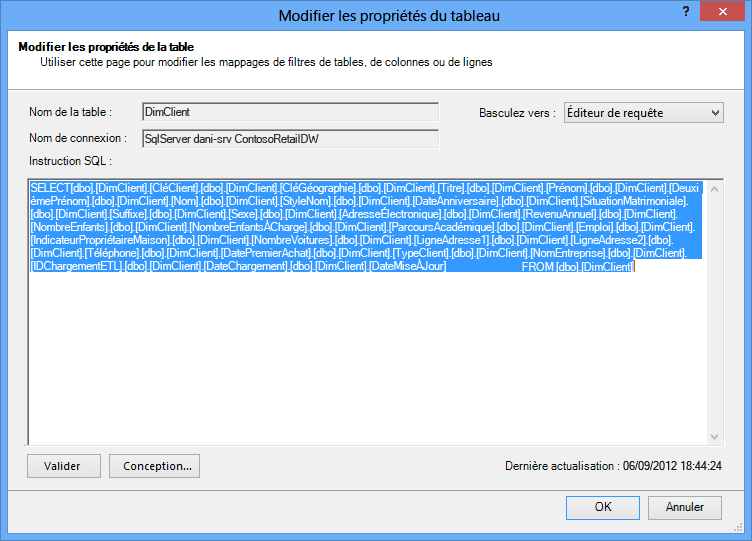
L’Éditeur de requête affiche la requête SQL utilisée pour remplir la table. Si vous avez filtré une colonne durant l’importation, votre requête comprend les noms de colonnes complets :
|
En revanche, si vous avez importé une table dans son intégralité sans désactiver la moindre colonne ou sans appliquer de filtre, vous verrez la requête sous la forme « Select * from », qui est plus difficile à modifier :
|

Modification de la requête SQL
À présent, vous savez comment trouver la requête, vous pouvez ensuite la modifier afin de réduire davantage la taille de votre modèle.
-
Pour les colonnes contenant des données monétaires ou décimales, si vous n’avez pas besoin des décimales, utilisez la syntaxe suivante pour supprimer ces dernières :
« SÉLECTIONNER ARRONDI([Decimal_column_name],0)... .”
Si vous avez besoin de centimes mais pas de fractions de centimes, remplacez le 0 par 2. Si vous utilisez des nombres négatifs, vous pouvez les arrondir aux unités, aux dizaines, aux centaines, etc.
-
Si vous avez une colonne Datetime nommée dbo.Bigtable.[Date Time] et si vous n’avez pas besoin de la partie heure, utilisez la syntaxe suivante pour supprimer la partie heure :
« SELECT CAST (dbo.Bigtable.[Date time] as date) AS [Date time]) »
-
Si vous avez une colonne Datetime nommée dbo.Bigtable.[Date Time] et si vous avez besoin des parties date et heure, utilisez plusieurs colonnes dans la requête SQL au lieu de la colonne Datetime uniquement :
« SELECT CAST (dbo.Bigtable.[Date Time] as date) AS [Date Time],
datepart(hh, dbo.Bigtable.[Date Time]) as [Date Time Hours],
datepart(mi, dbo.Bigtable.[Date Time]) as [Date Time Minutes],
datepart(ss, dbo.Bigtable.[Date Time]) as [Date Time Seconds],
datepart(ms, dbo.Bigtable.[Date Time]) as [Date Time Milliseconds]”
Utilisez autant de colonnes que nécessaire pour stocker chaque partie dans des colonnes distinctes.
-
Si vous avez besoin des heures et des minutes, et si vous préférez les regrouper dans une seule colonne de temps, vous pouvez utiliser la syntaxe suivante :
Timefromparts(datepart(hh, dbo.Bigtable.[Date Time]), datepart(mm, dbo.Bigtable.[Date Time])) as [Date Time HourMinute]
-
Si vous avez deux colonnes datetime, par exemple [Start Time] et [End Time], et si vous avez besoin d’indiquer la différence en secondes entre ces colonnes sous la forme d’une colonne appelée [Duration], retirez les deux colonnes de la liste et ajoutez ce qui suit :
“datediff(ss,[Start Date],[End Date]) as [Duration]”
Si vous utilisez le mot clé ms à la place de ss, vous obtiendrez la durée en millisecondes.
Utilisation de mesures calculées DAX à la place de colonnes
Si vous avez déjà utilisé le langage d’expressions DAX, vous savez sans doute que les colonnes calculées sont utilisées pour dériver de nouvelles colonnes à partir d’une autre colonne du modèle, alors que les mesures calculées sont définies une seule fois dans le modèle mais sont évaluées uniquement quand elles sont utilisées dans un tableau croisé dynamique ou tout autre rapport.
Il existe une technique d’économie de mémoire qui consiste à remplacer les colonnes ordinaires ou calculées par des mesures calculées. L’exemple classique est celui des colonnes relatives au prix unitaire, à la quantité et au total. Si vous avez ces trois colonnes, vous pouvez gagner de l’espace en conservant seulement deux de ces colonnes et en calculant la troisième à l’aide d’expressions DAX.
Quelles sont les 2 colonnes à garder ?
Dans l’exemple ci-dessus, gardez les colonnes relatives à la quantité et au prix unitaire. Ces deux colonnes ont moins de valeurs que la colonne de total. Pour calculer le total, ajoutez une mesure calculée comme suit :
“TotalSales:=sumx(‘Sales Table’,’Sales Table’[Unit Price]*’Sales Table’[Quantity])”
Les colonnes calculées sont comme des colonnes ordinaires dans la mesure où toutes les deux occupent de l’espace dans le modèle. En revanche, les mesures calculées sont calculées à la volée et n’occupent pas d’espace.
Conclusion
Dans cet article, nous avons décrit plusieurs approches qui peuvent vous aider à créer un modèle plus économe en mémoire. Il est possible de limiter la taille du fichier et les besoins en mémoire d’un modèle de données en réduisant le nombre total de colonnes et de lignes, ainsi que le nombre de valeurs uniques figurant dans chaque colonne. Voici quelques techniques que nous avons abordées :
-
La suppression de colonnes est évidemment la meilleure façon de gagner de l’espace. Déterminez quelles sont les colonnes dont vous avez réellement besoin.
-
Parfois, vous pouvez supprimer une colonne et la remplacer par une mesure calculée dans la table.
-
Vous n’avez pas forcément besoin de toutes les lignes d’une table. Vous pouvez filtrer les lignes dans l’Assistant Importation de table.
-
En règle générale, la rupture d’une colonne unique en plusieurs parties distinctes est un bon moyen de réduire le nombre de valeurs uniques dans une colonne. Chacune des parties aura un petit nombre de valeurs uniques, et le total combiné sera plus petit que la colonne unifiée d’origine.
-
Dans de nombreux cas, vous avez également besoin d’utiliser les différentes parties sous forme de segments dans vos rapports. Le cas échéant, vous pouvez créer des hiérarchies basées sur des parties telles que les heures, les minutes et les secondes.
-
Bien souvent, les colonnes contiennent plus d’informations que nécessaire. Par exemple, supposons qu’une colonne stocke des décimales, mais que vous avez appliqué une mise en forme qui masque toutes les décimales. L’arrondi peut se révéler très efficace pour réduire la taille d’une colonne numérique.
Maintenant que vous avez fait votre possible pour réduire la taille de votre classeur, envisagez d’exécuter l’optimiseur de la taille des classeurs. Il analyse votre classeur Excel et si possible, le compresse davantage. Téléchargez l’optimiseur de la taille des fichiers de travail.
Liens connexes
Spécification et limites du modèle de données
Optimiseur de la taille des livres de travail
PowerPivot : analyse et modélisation de données puissantes dans Excel









