
Cet article décrit la syntaxe de formule et l’utilisation de la fonction DROITEREG dans Microsoft Excel. Vous trouverez des liens vous permettant d’obtenir davantage d’informations sur la création de graphiques et l’exécution d’une analyse de régression à la section Voir aussi.
Description
La fonction DROITEREG calcule les statistiques d’une droite par la méthode des moindres carrés afin de calculer une droite s’ajustant au plus près de vos données, puis renvoie une matrice qui décrit cette droite. Vous pouvez également combiner la fonction DROITEREG avec d’autres fonctions pour calculer les statistiques d’autres types de modèles linéaires dans les paramètres inconnus, y compris polynomial, logarithmique, exponentiel et série de puissances. Dans la mesure où cette fonction renvoie une matrice de valeurs, elle doit être tapée sous la forme d’une formule matricielle. Vous trouverez des instructions sous les exemples proposés dans cet article.
L’équation de la droite est la suivante :
y = mx + b
–ou–
y = m1x1 + m2x2 +... + b
en présence de plusieurs plages de valeurs x, où les valeurs dépendantes y sont une fonction des valeurs indépendantes x. Les valeurs m sont des coefficients correspondant à chaque valeur x, et b est une valeur constante. Vous remarquerez que y, x et m peuvent être des vecteurs. La matrice renvoyée par la fonction DROITEREG est de la forme {mn.mn-1.....m1.b}. La fonction DROITEREG peut également renvoyer des statistiques de régression supplémentaires.
Syntaxe
DROITEREG(y_connus, [x_connus], [constante], [statistiques])
La syntaxe de la fonction DROITEREG contient les arguments suivants :
Syntaxe
-
y_connus Obligatoire. Série des valeurs y déjà connues par la relation y = mx + b.
-
Si la plage de y_connus occupe une seule colonne, chaque colonne de l’argument x_connus est interprétée comme étant une variable distincte.
-
Si la plage de y_connus occupe une seule ligne, chaque ligne de l’argument x_connus est interprétée comme étant une variable distincte.
-
-
x_connus Facultatif. Série de valeurs x éventuellement déjà connues par la relation y = mx + b.
-
La plage de x_connus peut inclure une ou plusieurs séries de variables. Si vous utilisez une seule variable, les arguments y_connus et x_connus peuvent être des plages de forme différente, à condition qu’elles aient la même dimension. Si vous utilisez plusieurs variables, l’argument y_connus doit être un vecteur (en d’autres termes, une plage comportant une seule ligne ou une seule colonne).
-
Si l’argument x_connus est omis, il est supposé égal à la matrice {1.2.3....}, de même ordre que l’argument y_connus.
-
-
constante Facultatif. Valeur logique précisant si la constante b doit être forcée à 0.
-
Si l’argument constante est VRAI ou omis, la constante b est calculée normalement.
-
Si l’argument constante est FAUX, b est égal à 0 et les valeurs m sont ajustées de sorte que y = mx.
-
-
statistiques Facultatif. Représente une valeur logique indiquant si d’autres statistiques de régression doivent être renvoyées.
-
Si les statistiques ont la valeur TRUE, LINEST retourne les statistiques de régression supplémentaires ; par conséquent, le tableau retourné est {mn,mn-1,...,m1,b ; sen,sen-1,...,se1,seb ; r2,sey ; F,df ; ssreg,ssresid}.
-
Si l’argument statistiques est FAUX ou omis, la fonction DROITEREG renvoie uniquement les coefficients m et la constante b.
Les statistiques de régression supplémentaires sont les suivantes :
-
|
Statistique |
Description |
|---|---|
|
se1,se2,...,sen |
Les valeurs d’erreur type correspondant aux coefficients m1,m2,...,mn. |
|
seb |
La valeur d’erreur type correspondant à la constante b (seb = #N/A si l’argument constante a la valeur FAUX). |
|
r2 |
Le coefficient de détermination. Compare les valeurs y estimées aux valeurs y réelles et varie entre 0 et 1. Un coefficient de détermination égal à 1 indique une corrélation parfaite de l’échantillon (aucune différence entre les valeurs y estimées et réelles). A l’inverse, un coefficient de détermination égal à 0 (zéro) indique que l’équation de régression ne peut servir à prévoir une valeur y. Pour plus d’informations sur la façon dont2 est calculé, consultez « Remarques », plus loin dans cette rubrique. |
|
sey |
L’erreur type pour la valeur y estimée. |
|
F |
La statistique F ou valeur F observée. Utilisez ce paramètre pour déterminer si la relation observée entre les variables dépendantes et indépendantes est due au hasard. |
|
df |
Les degrés de liberté. Ils vous aident à trouver les valeurs critiques de la statistique F dans une table statistique. Comparez les valeurs trouvées dans la table à la statistique F renvoyée par la fonction DROITEREG pour déterminer le niveau de confiance du modèle. Pour plus d’informations sur le mode de calcul de df, consultez les « Remarques » plus loin dans cette rubrique. L’exemple 4 ci-dessous illustre l’utilisation de F et df. |
|
ssreg |
La somme de régression des carrés. |
|
ssresid |
La somme résiduelle des carrés. Pour plus d’informations sur le mode de calcul de ssreg et de ssresid, consultez les « Notes » plus loin dans cette rubrique. |
L’illustration suivante montre l’ordre dans lequel les statistiques de régression supplémentaires sont renvoyées.

Notes
-
Toute droite peut être décrite par sa pente et son ordonnée à l’origine :
Pente (m) :
Pour trouver la pente d’une ligne, souvent écrite sous la forme m, prenez deux points sur la ligne, (x1,y1) et (x2,y2) ; la pente est égale à (y2 - y1)/(x2 - x1).Interception Y (b) :
L’interception y d’une ligne, souvent écrite sous la forme b, est la valeur de y au point où la ligne traverse l’axe y.L’équation d’une droite est y = mx + b. Une fois connues les valeurs de m et de b, chaque point de la droite peut être calculé en fixant la valeur x ou y dans l’équation. Vous pouvez également utiliser la fonction TENDANCE.
-
Si vous utilisez une seule variable indépendante x, vous pouvez obtenir directement les valeurs de la pente et de l’ordonnée à l’origine de la droite à l’aide des formules suivantes :
Pente:
=INDEX(LINEST(known_y’s,known_x),1)Interception Y :
=INDEX(LINEST(known_y’s,known_x),2) -
L’exactitude de la droite calculée par la fonction DROITEREG dépend du degré de dispersion de vos données. Le modèle de la fonction DROITEREG sera d’autant plus exact que les données seront plus linéaires. La fonction DROITEREG utilise la méthode des moindres carrés pour calculer le meilleur ajustement à vos données. Lorsque vous ne disposez que d’une seule variable indépendante x, les calculs de m et b s’appuient sur les formules suivantes :
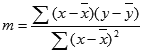
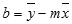
où x et y sont des moyennes d’échantillon, à savoir x = MOYENNE(x_connus) et y = MOYENNE(y_connus).
-
Les fonctions line-and-curve-fitting LINEST et LOGEST peuvent calculer la meilleure courbe droite ou exponentielle qui correspond à vos données. Toutefois, vous devez décider lequel des deux résultats correspond le mieux à vos données. Vous pouvez calculer TREND(known_y,known_x) pour une ligne droite, ou GROWTH(known_y, known_x) pour une courbe exponentielle. Ces fonctions, sans l’argument du new_x , retournent un tableau de valeurs y prédites le long de cette ligne ou courbe à vos points de données réels. Vous pouvez ensuite comparer les valeurs prédites avec les valeurs réelles. Vous souhaiterez peut-être les graphiquer pour les deux pour une comparaison visuelle.
-
Dans une analyse de régression, Excel calcule, pour chaque point, le carré de la différence entre les valeurs y estimée et réelle. La somme de ces différences quadratiques est appelée « somme résiduelle des carrés », ssresid. Excel calcule ensuite la somme totale des carrés, sstotal. Si l’argument constante est VRAI ou est omis, la somme totale des carrés est la somme des différences quadratiques entre les valeurs y réelles et la moyenne des valeurs y. Si l’argument constante est FAUX, la somme totale des carrés (= somme des carrés des valeurs y réelles (sans soustraire la valeur y moyenne de chaque valeur y individuelle). Ensuite, la somme de régression des carrés, ssreg, peut être trouvée en faisant : ssreg = sstotal - ssresid. Plus la somme résiduelle des carrés est petite par rapport à la somme totale des carrés, plus la valeur du coefficient de détermination, r2, est grande, ce qui est un indicateur de la façon dont l’équation résultant de l’analyse de régression explique la relation entre les variables. La valeur de r2 est égale à ssreg/sstotal.
-
Dans certains cas, une ou plusieurs colonnes X (supposons que Y et X se trouvent dans des colonnes) peuvent n’avoir aucune valeur prédictive supplémentaire en présence des autres colonnes X. En d’autres termes, l’élimination d’une ou de plusieurs colonnes X peut entraîner des valeurs Y prédites qui sont tout aussi précises. Dans ce cas, ces colonnes X redondantes doivent être omises du modèle de régression. Ce phénomène est appelé « collinearité », car toute colonne X redondante peut être exprimée sous la forme d’une somme de multiples des colonnes X non redondantes. La fonction LINEST vérifie la collinearité et supprime toutes les colonnes X redondantes du modèle de régression lorsqu’elle les identifie. Les colonnes X supprimées peuvent être reconnues dans la sortie LINEST comme ayant 0 coefficients en plus des valeurs 0 se. Si une ou plusieurs colonnes sont supprimées comme redondantes, df est affecté, car df dépend du nombre de colonnes X réellement utilisées à des fins prédictives. Pour plus d’informations sur le calcul de df, consultez l’exemple 4. Si df est modifié en raison de la suppression des colonnes X redondantes, les valeurs sey et F sont également affectées. La collinearité devrait être relativement rare dans la pratique. Toutefois, il est plus probable que certaines colonnes X contiennent seulement 0 et 1 valeurs pour indiquer si un sujet d’une expérience est ou non membre d’un groupe particulier. Si const = TRUE ou est omis, la fonction LINEST insère efficacement une colonne X supplémentaire des 1 valeurs pour modéliser l’interception. Si vous avez une colonne avec un 1 pour chaque sujet s’il est masculin, ou 0 si ce n’est pas le cas, et que vous avez également une colonne avec un 1 pour chaque sujet si féminin, ou 0 si ce n’est pas le cas, cette dernière colonne est redondante, car les entrées qu’elle contient peuvent être obtenues en soustrayant l’entrée de la colonne « indicateur masculin » de l’entrée dans la colonne supplémentaire des 1 valeurs ajoutées par la fonction LINEST .
-
La valeur de df est calculée comme suit lorsque aucune colonne X n’est supprimée du modèle en raison de la colinéarité : s’il y a k colonnes de x_connus et que l’argument constante est VRAI ou est omise, df = n – k – 1. Si l’argument constante est FAUX, df = n - k. Dans les deux cas, chaque colonne X ayant été supprimée en raison de la colinéarité augmente la valeur de df de 1.
-
Lorsque vous entrez comme argument une constante matricielle telle que x_connus, utilisez le point pour séparer les valeurs d’une même ligne et le point-virgule pour séparer les lignes. Les caractères séparateurs peuvent être différents selon les paramètres régionaux.
-
Notez que les valeurs y prédites par l’équation de régression peuvent ne pas être valides si elles se trouvent en dehors de la plage des valeurs y utilisées pour déterminer cette équation.
-
L’algorithme utilisé dans la fonction DROITEREG est différent de celui utilisé dans les fonctions PENTE et ORDONNEE.ORIGINE. Cette différente peut induire des résultats différents lorsque les données sont non déterminées et colinéaires. Par exemple, si les points de données de l’argument y_connus sont 0 et que les points de données de l’argument x_connus sont 1 :
-
DROITEREG renvoie la valeur 0. L’algorithme de la fonction DROITEREG est conçu pour renvoyer des résultats raisonnables pour des données colinéaires et, dans ce cas, une réponse au moins est possible.
-
PENTE et INTERCEPTION retournent un #DIV/0 ! . L’algorithme des fonctions SLOPE et INTERCEPT est conçu pour rechercher une seule réponse, et dans ce cas, il peut y avoir plusieurs réponses.
-
-
En plus d’utiliser LOGREG pour calculer une statistique pour d’autres types de régression, vous pouvez utiliser DROITEREG pour calculer une plage d’autres types de régression en entrant des fonctions des variables x et y comme série x et y pour DROITEREG. Par exemple, la formule suivante :
=DROITEREG(valeursy, valeursx^COLUMN($A:$C))
fonctionne lorsque vous avez une seule colonne de valeurs y et une seule colonne de valeurs x pour calculer l’approximation cubique (polynomial de commande 3) de forme :
y = m1*x + m2*x^2 + m3*x^3 + b
Vous pouvez ajuster cette formule pour calculer d’autres types de régression, mais dans certains cas elle nécessite l’ajustement des valeurs de sortie et d’autres statistiques.
-
La valeur du test F renvoyée par la fonction DROITEREG est différente de la valeur du test F renvoyée par la fonction TEST.F. La fonction DROITEREG renvoie la statistique F, alors que la fonction TEST.F renvoie la probabilité.
Exemples
Exemple 1 : pente et ordonnée Y
Copiez les données d’exemple dans le tableau suivant, et collez-le dans la cellule A1 d’un nouveau classeur Excel. Pour que les formules affichent des résultats, sélectionnez-les, appuyez sur F2, puis sur Entrée. Si nécessaire, vous pouvez modifier la largeur des colonnes pour afficher toutes les données.
|
y connus |
x connus |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Résultat (pente) |
Résultat (ordonnée à l’origine) |
|
2 |
1 |
|
Formule (formule matricielle dans les cellules A7:B7) |
|
|
=DROITEREG(A2:A5;B2:B5;FAUX) |
Exemple 2 : régression linéaire simple
Copiez les données d’exemple dans le tableau suivant, et collez-le dans la cellule A1 d’un nouveau classeur Excel. Pour que les formules affichent des résultats, sélectionnez-les, appuyez sur F2, puis sur Entrée. Si nécessaire, vous pouvez modifier la largeur des colonnes pour afficher toutes les données.
|
Mois |
Ventes |
|---|---|
|
1 |
3 100 € |
|
2 |
4 500 € |
|
3 |
4 400 € |
|
4 |
5 400 € |
|
5 |
7 500 € |
|
6 |
8 100 € |
|
Formule |
Résultat |
|
=SOMME(DROITEREG(B1:B6, A1:A6)*{9\1}) |
11 000 € |
|
Calcule l’estimation des ventes du neuvième mois, en fonction des ventes des mois 1 à 6. |
Exemple 3 : régression linéaire multiple
Copiez les données d’exemple dans le tableau suivant, et collez-le dans la cellule A1 d’un nouveau classeur Excel. Pour que les formules affichent des résultats, sélectionnez-les, appuyez sur F2, puis sur Entrée. Si nécessaire, vous pouvez modifier la largeur des colonnes pour afficher toutes les données.
|
Superficie utile (x1) |
Bureaux (x2) |
Entrées (x3) |
Âge (x4) |
Valeur immobilière (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
142 000 € |
|
2333 |
2 |
2 |
12 |
144 000 € |
|
2356 |
3 |
1,5 |
33 |
151 000 € |
|
2379 |
3 |
2 |
43 |
150 000 € |
|
2402 |
2 |
3 |
53 |
139 000 € |
|
2425 |
4 |
2 |
23 |
169 000 € |
|
2448 |
2 |
1,5 |
99 |
126 000 € |
|
2471 |
2 |
2 |
34 |
142 900 € |
|
2494 |
3 |
3 |
23 |
163 000 € |
|
2517 |
4 |
4 |
55 |
169 000 € |
|
2540 |
2 |
3 |
22 |
149 000 € |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Formule (formule de tableau dynamique entrée dans A19) |
||||
|
=DROITREG(E2:E12;A2:D12;VRAI;VRAI) |
Exemple 4 - Utilisation des statistiques F etr2
Dans l’exemple précédent, le coefficient de détermination, ou r2, est de 0,99675 (voir la cellule A17 dans la sortie de LINEST), ce qui indiquerait une relation forte entre les variables indépendantes et le prix de vente. La statistique F vous permet de déterminer si les résultats présentant cette valeur de r2 élevée sont le fruit du hasard.
Supposons un instant qu’il n’existe pas de relation véritable entre les variables, mais que l’échantillon de 11 immeubles de bureaux constitué est tel que son analyse statistique démontre une relation étroite. On appelle Alpha la probabilité de se tromper en concluant à l’existence d’une relation.
Vous pouvez utiliser les valeurs F et df des résultats de la fonction DROITEREG pour évaluer la possibilité d’obtenir une valeur F supérieure par hasard. F peut être comparé avec les valeurs critiques dans les tables de distribution F publiées ou vous pouvez utiliser la fonction LOI.F d’Excel pour calculer la probabilité qu’une valeur F plus élevée se produise par hasard. La distribution F appropriée a les degrés de liberté v1 et v2. Si n est le nombre d’observations et que l’argument constante est VRAI ou omis, alors v1 = n – df – 1 et v2 = df. (Si l’argument constante = FAUX, alors v1 = n – df et v2 = df.) La fonction LOI.F d’Excel avec la syntaxe LOI.F(F,v1,v2) renverra la probabilité qu’une valeur F plus élevée se produise par hasard. Dans cet exemple, df = 6 (cellule B18) et F = 459.753674 (cellule A18).
En supposant une valeur Alpha de 0,05, v1 = 11 – 6 – 1 = 4 et v2 = 6, le niveau critique de F est 4,53. Étant donné que F = 459,753674 est beaucoup plus élevé que 4,53, il est extrêmement peu probable qu’une valeur F aussi élevée s’est produite par hasard. (Avec Alpha = 0,05, l’hypothèse qu’il n’existe aucune relation entre les known_y et les known_x doit être rejetée lorsque F dépasse le niveau critique, 4,53.) Vous pouvez utiliser la fonction FDIST dans Excel pour obtenir la probabilité qu’une valeur F aussi élevée s’est produite par hasard. Par exemple, FDIST(459.753674, 4, 6) = 1.37E-7, une probabilité extrêmement faible. Vous pouvez conclure, soit en recherchant le niveau critique de F dans une table, soit en utilisant la fonction FDIST , que l’équation de régression est utile pour prédire la valeur évaluée des immeubles de bureaux dans cette zone. N’oubliez pas qu’il est essentiel d’utiliser les valeurs correctes de v1 et v2 calculées dans le paragraphe précédent.
Exemple 5 : calcul de la statistique T
Un autre test d’hypothèse permet de déterminer si chaque coefficient de pente intervient dans l’estimation de la valeur immobilière d’un immeuble de bureaux proposée dans l’exemple 3. Par exemple, pour tester la signification statistique du coefficient d’âge, divisez -1400,23 (le coefficient de la pente âge) par 82,896 (l’erreur type estimée des coefficients d’âge renvoyée dans la cellule A15). Cela donne la valeur t observée suivante :
t = m4 ÷ se4 =-234,24 ÷ 13,268 =-17,7
Si la valeur absolue de t est suffisamment élevée, vous pouvez conclure que le coefficient de pente est utile dans l’estimation de la valeur immobilière d’un immeuble de bureaux dans l’exemple 3. Le tableau suivant illustre les valeurs absolues des 4 valeurs t observées.
Si vous vous reportez à la table correspondante d’un manuel de statistique, vous trouverez que la valeur critique t, bilatérale, pour 6 degrés de liberté et Alpha = 0,05 est 2,447. Cette valeur critique peut également être trouvée au moyen de la fonction LOI.STUDENT.INVERSE d’Excel. LOI.STUDENT.INVERSE(0,05,6) = 2,447. Dans la mesure où la valeur absolue de t (16,89) est supérieure à 1,94, l’âge est une variable significative dans l’estimation de la valeur immobilière d’un immeuble de bureaux. On peut ainsi tester la signification statistique de chacune des autres variables indépendantes. Le tableau suivant récapitule les valeurs t observées pour chaque variable indépendante.
|
Variable |
Valeur t observée |
|---|---|
|
Superficie utile |
4,82 |
|
Nombre de bureaux |
29,90 |
|
Nombre d’entrées |
4,72 |
|
Âge |
16,89 |
Toutes ces valeurs sont supérieures à 2 447 en valeur absolue. Par conséquent, toutes les variables utilisées dans l’équation de régression sont utiles pour prédire la valeur immobilière des immeubles de bureaux de ce quartier.









