
Una vez que haya migrado los datos de Access a SQL Server, tendrá una base de datos cliente/servidor, la cual puede ser una solución local o una híbrida de la nube de Azure. De cualquier manera, ahora Access es la capa de presentación y SQL Server es la capa de datos. Ahora es un buen momento para repensar los aspectos de la solución, especialmente el rendimiento de consultas, la seguridad y la continuidad empresarial, para que pueda mejorar y escalar su solución de base de datos.
Para un usuario de Access puede resultar desalentador conocer por primera vez la documentación de SQL Server y Azure. Esto amerita un rápido paseo para guiarlo a través de los aspectos destacados que puedan ser importantes para usted. Cuando termine esta excursión, estará listo para explorar los avances en la tecnología de bases de datos y hacer un viaje aún más largo.
En este artículo:
|
Administración de bases de datos Impulsar la continuidad empresarial Identificar problemas de privacidad |
Consultas y relacionada |
Tipos de datos |
Varios |
Impulsar la continuidad empresarial
Deseará mantener y ejecutar su solución de Access con mínimas interrupciones, pero las opciones disponibles con una base de datos back-end de Access son limitadas. Realizar una copia de seguridad de la base de datos de Access es esencial para proteger los datos, pero necesita desconectar a los usuarios. También puede haber tiempos de inactividad no planeados causados por actualizaciones de mantenimiento de hardware o software, interrupciones de red o alimentación, errores de hardware, infracciones de seguridad o incluso ciberataques. Para reducir el tiempo de inactividad y el impacto en su negocio, puede hacer una copia de seguridad de una base de datos de SQL Server mientras está en uso. Además, SQL Server también ofrece estrategias de alta disponibilidad (HA) y recuperación ante desastres (DR). A estas dos tecnologías combinadas se las denomina HADR. Para obtener más información, vea Continuidad empresarial y recuperación de bases de datos e Impulsar la continuidad empresarial con SQL Server (libro electrónico).
Copias de seguridad mientras está en uso
SQL Server utiliza un proceso de copia de seguridad en línea que puede realizarse mientras la base de datos se ejecuta. Puede hacer una copia de seguridad completa, una copia de seguridad parcial o una copia de seguridad de un archivo. Una copia de seguridad copia los datos y los registros de transacciones para asegurar una operación de restauración completa. Especialmente en una solución local, tenga en cuenta las diferencias entre las opciones de recuperación simple y completa, y cómo estas afectan al crecimiento del registro de transacciones. Para obtener más información, vea Modelos de recuperación.
La mayoría de las operaciones de copia de seguridad se realizan inmediatamente, excepto la administración de archivos y las operaciones de reducción de base de datos. Por el contrario, si intenta crear o eliminar un archivo de la base de datos mientras está en curso una operación de copia de seguridad, la misma no se realizará correctamente. Para obtener más información, vea Resumen de la copia de seguridad.
HADR
Las dos técnicas más comunes para lograr la alta disponibilidad y la continuidad empresarial son la creación de reflejos y la agrupación de clústeres. SQL Server integra la tecnología de creación de reflejos y la de agrupación de clústeres con las "instancias de clústeres de conmutación por error siempre activadas" y los "grupos de disponibilidad siempre activados".
La creación de reflejos es una solución de continuidad al nivel de la base de datos que admite una conmutación por error casi instantánea al mantener una base de datos en espera, una copia completa o reflejo de la base de datos activa en hardware independiente. Puede opera en modo sincrónico (alta seguridad), donde una transacción entrante está confirmada para todos los servidores al mismo tiempo, o en un modo asíncrono (alto rendimiento), en el que una transacción entrante se confirma solo en la base de datos activa y, a continuación, en alguna punto predefinido copiado en el reflejo. La creación de reflejos es una solución a nivel de la base de datos y funciona solo con las bases de datos que utilizan el modelo de recuperación completa.
La agrupación de clústeres es una solución a nivel del servidor que combina los servidores en un solo almacenamiento de datos que se muestra al usuario como una única instancia. Los usuarios se conectan a la instancia y nunca necesitan saber qué servidor de la instancia está activo actualmente. Si un servidor falla o debe desconectarse para mantenimiento, la experiencia del usuario no cambia. El administrador de clúster supervisa cada servidor del clúster con un latido, por lo que detecta cuando el servidor activo en el clúster se desconecta e intenta cambiar fácilmente al siguiente servidor del clúster, aunque se produzca un retardo variable al producirse el cambio.
Para obtener más información, vea las Instancias de clústeres de conmutación por error siempre activadas y los Grupos de disponibilidad siempre activados: una solución de alta disponibilidad y recuperación ante desastres.
Seguridad de SQL Server
Aunque puede proteger la base de datos de Access con el centro de confianza y cifrando la base de datos, SQL Server tiene más características de seguridad avanzada. Echemos un vistazo a tres funciones que se destacan para el usuario de Access. Para obtener más información, vea Asegurando SQL Server.
Autenticación de base de datos
Hay cuatro métodos de autenticación de bases de datos en SQL Server, cada uno de los cuales puede especificarse en una cadena de conexión ODBC. Para más información, vea Vincular a datos o importar datos desde una base de datos de Azure SQL Server. Cada método tiene sus propias ventajas.
Autenticación integrada de Windows Use las credenciales de Windows para la validación de usuarios, los roles de seguridad y la limitación de los usuarios a las características y los datos. Puede aprovechar las credenciales del dominio y administrar fácilmente los derechos de usuario de la aplicación. De forma opcional, puede escribir un nombre de entidad de seguridad de servicio (SPN). Para obtener más información, vea Elegir un modo de autenticación.
Autenticación de SQL Server Los usuarios necesitan conectarse con credenciales configuradas en la base de datos especificando el id. de inicio de sesión y la contraseña la primera vez que accedan a la base de datos en una sesión. Para obtener más información, vea Elegir un modo de autenticación.
Autenticación integrada de Azure Active Directory Permite conectarse a la base de datos de Azure SQL Server con Azure Active Directory. Después de configurar la autenticación de Azure Active Directory, no es necesario especificar un nombre de usuario y contraseña adicionales. Para obtener más información, vea Conectarse a una base de datos SQL con autenticación de Azure Active Directory.
Autenticación de contraseña de Active Directory Permite conectarse con credenciales configuradas en Azure Active Directory si especifica el nombre de inicio de sesión y la contraseña. Para obtener más información, vea Conectarse a una base de datos SQL con autenticación de Azure Active Directory.
Sugerencia Use la detección de amenazas para recibir alertas de actividad anómala en la base de datos que indiquen posibles amenazas de seguridad para una base de datos de Azure SQL Server. Para obtener más información, vea Detección de amenazas de base de datos SQL.
Seguridad de aplicaciones
SQL Server tiene características de seguridad de dos niveles de aplicación que puede aprovechar con Access.
Enmascaramiento dinámico de datos Ocultar información confidencial enmascarándola para los usuarios sin privilegios. Por ejemplo, puede enmascarar los números de seguridad social, ya sea parcial o completamente.
 Una máscara de datos parcial |
 Una máscara de datos completa |
Hay varias maneras en las que puede definir una máscara de datos y puede aplicarlas a diferentes tipos de datos. El enmascaramiento de datos está basado en directivas a nivel de tabla y columna para un conjunto definido de usuarios y se aplica en tiempo real a la consulta. Para obtener más información, vea Enmascaramiento dinámico de datos.
Seguridad de nivel de fila Puede controlar el acceso a filas específicas de la base de datos con información confidencial en función de las características del usuario mediante la seguridad de nivel de fila. El sistema de base de datos aplica estas restricciones de acceso y esto hace que el sistema de seguridad sea más confiable y robusto.

Hay dos tipos de predicados de seguridad:
-
Un predicado de filtro filtra las filas de una consulta. El filtro es transparente y el usuario final lo desconoce.
-
Un predicado de bloqueo impide acciones no autorizadas y arroja una excepción si la acción no se puede realizar.
Para obtener más información, vea Seguridad de nivel de fila.
Proteger los datos mediante cifrado
Proteja los datos en reposo, en tránsito y mientras están en uso sin afectar al rendimiento de la base de datos. Para obtener más información, consulte Cifrado de SQL Server.
Cifrado en reposo Para proteger los datos personales contra los ataques de medios sin conexión a nivel del almacenamiento físico, utilice el cifrado en reposo, también denominado cifrado de datos transparente (TDE). Esto significa que los datos están protegidos incluso si el medio físico es robado o eliminado incorrectamente. El TDE realiza el cifrado y descifrado en tiempo real de bases de datos, copias de seguridad y registros de transacciones sin que sea necesario cambiar las aplicaciones.
Cifrado en tránsito Para protegerse contra las intromisiones y los ataques de tipo man-in-the-middle, puede cifrar los datos transmitidos por la red. SQL Server admite la seguridad de la capa de transporte (TLS) 1.2 para las comunicaciones de alta seguridad. El protocolo de flujo de datos TDS (TDS) también se usa para proteger las comunicaciones a través de redes que no sean de confianza.
Cifrado en uso en el cliente Para proteger los datos personales mientras están en uso, "Siempre cifrado" es la característica que desea. Un controlador en el equipo del cliente cifra y descifra los datos personales sin revelar las claves de cifrado al motor de la base de datos. Como resultado, los datos cifrados solo están visibles para las personas responsables de administrar esos datos y no para otros usuarios con alto nivel de privilegios que no deban tener acceso. Dependiendo del tipo de cifrado seleccionado, Siempre cifrado puede limitar algunas funcionalidades de la base de datos, tales como la búsqueda, la agrupación y la indización de columnas cifradas.
Identificar problemas de privacidad
Las preocupaciones sobre la privacidad son tan generalizadas que la Unión Europea ha definido requisitos legales mediante el Reglamento general de protección de datos (RGPD). Afortunadamente, un back-end de SQL Server es muy apropiado para responder a estos requisitos. Considere implementar RGPD mediante un marco de trabajo de tres pasos.

Paso 1: Evaluar y administrar el riesgo de cumplimiento
El RGPD necesita que identifique y haga un inventario de la información personal que tenga en tablas y archivos. Esta información puede variar desde un nombre, una foto, una dirección de correo electrónico, datos bancarios, publicaciones en sitios web de redes sociales, información médica o incluso una dirección IP.
Una nueva herramienta, Clasificación y detección de los datos SQL, integrada en SQL Server Management Studio le ayuda a descubrir, clasificar, etiquetar y crear informes sobre datos confidenciales al aplicar dos atributos de metadatos a las columnas:
-
Etiquetas Para definir la confidencialidad de los datos.
-
Tipos de información Para proporcionar granularidad adicional acerca de los tipos de datos almacenados en una columna.
Otro mecanismo de detección que puede usar es la búsqueda de texto completo, el cual incluye el uso de los predicados CONTIENE y TEXTOLIBRE y de las funciones con valores de conjunto de filas como CONTIENETABLA y TABLADETEXTOLIBRE para usar con la instrucción SELECCIONAR. Con la búsqueda de texto completo, puede buscar tablas para descubrir palabras, combinaciones de palabras o variaciones de una palabra tales como sinónimos o inflexiones. Para obtener más información, consulte: Búsqueda de texto completo.
Paso 2: Proteger información personal
El RGPD requiere que proteja la información personal y limite el acceso a la misma. Además de los pasos estándar que debe seguir para administrar el acceso a su red y sus recursos, como la configuración del firewall, puede usar las características de seguridad de SQL Server para ayudarle a controlar el acceso a los datos:
-
La autenticación de SQL Server para administrar la identidad del usuario y evitar el acceso no autorizado.
-
La seguridad de nivel de fila para limitar el acceso a las filas de una tabla basándose en la relación entre el usuario y dichos datos.
-
El enmascaramiento dinámico de datos para limitar la exposición a los datos personales al enmascararlos ante los usuarios sin privilegios.
-
El cifrado para asegurarse de que los datos personales estén protegidos durante la transmisión y el almacenamiento, y que estén protegidos frente a peligro, incluido en el lado del servidor.
Para obtener más información, vea Seguridad de SQL Server.
Paso 3: Responder de forma eficaz a las solicitudes
El RGPD requiere que mantenga registros del procesamiento de datos personales y que estos registros estén disponibles para las autoridades supervisoras previa solicitud. Si se generan problemas de publicación accidental de datos, los controles de protección le permiten responder rápidamente. Los datos deben estar disponibles rápidamente cuando se necesiten los informes. Por ejemplo, el RGPD requiere que se notifique una vulneración de datos personales a la autoridad supervisora "a más tardar, 72 horas después de haberla notado".
SQL Server 2017 le ayuda con las tareas de informes de varias maneras:
-
SQL Server Audit le ayuda a asegurar que existen registros persistentes de las actividades de acceso y procesamiento de las bases de datos. Realiza una auditoría específica que realiza el seguimiento de las actividades de la base de datos para ayudarle a comprender e identificar las posibles amenazas, el abuso o las infracciones de seguridad. Puede realizar análisis forense de datos rápidamente.
-
Las tablas temporales de SQL Server son tablas de usuario con versión del sistema diseñadas para mantener un historial completo de los cambios en los datos. Puede usarlas para crear informes fáciles y análisis en un momento determinado.
-
Evaluación de vulnerabilidad de SQL le ayuda a detectar problemas de seguridad y de permisos. Cuando se detecta un problema, también puede explorar en profundidad los informes de la base de datos para encontrar acciones para la resolución.
Para obtener más información, vea Crear una plataforma de confianza (libro electrónico) y Desplazarse hasta el cumplimiento normativo de RGPD.
Crear instantáneas de las bases de datos
Una instantánea de la base de datos es una vista estática de solo lectura de una base de datos de SQL Server en un momento determinado. Aunque puede copiar un archivo de la base de datos de Access para crear una instantánea de la base de datos de forma eficaz, Access no tiene una metodología integrada como SQL Server. Puede usar una instantánea de base de datos para escribir informes basándose en los datos al momento que se tomó la instantánea de la base de datos. También puede usar una instantánea de base de datos para mantener datos históricos, tales como uno para cada trimestre económico que use para resumir los informes de fin de período. Le recomendamos las siguientes prácticas:
-
Asignar un nombre a la instantánea Cada instantánea de la base de datos necesita un nombre único de base de datos. Agregue el propósito y el período de tiempo al nombre para facilitar la identificación. Por ejemplo, para hacer una instantánea de la base de datos AdventureWorks tres veces al día a intervalos de 6 horas entre las 6 A.M. y las 6 P.M. basándose en un reloj de 24 horas, asígneles el nombre AdventureWorks_snapshot_0600, AdventureWorks_snapshot_1200 y AdventureWorks_snapshot_1800.
-
Limitar el número de instantáneas Cada instantánea de la base de datos se conserva hasta que se quita explícitamente. Debido a que cada instantánea seguirá creciendo, puede que quiera ahorrar espacio en disco eliminando una instantánea anterior después de crear una nueva instantánea. Por ejemplo, si está realizando informes diarios, conserve la instantánea de la base de datos durante 24 horas y, a continuación, elimínela y sustitúyala por otra nueva.
-
Conectar con la instantánea correcta Para usar una instantánea de la base de datos, el front-end de Access necesita conocer la ubicación correcta. Cuando reemplaza una nueva instantánea por una existente, debe redireccionar Access a la nueva instantánea. Agregue lógica al front-end de Access para asegurarse de que está conectándose a la instantánea de la base de datos correcta.
Aquí se muestra cómo crear una instantánea de la base de datos:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Para obtener más información, vea Instantáneas de la base de datos (SQL Server).
Control de simultaneidad
Cuando una gran cantidad de personas intenta modificar los datos de una base de datos al mismo tiempo, se necesita un sistema de controles para que las modificaciones efectuadas por una persona no afecten negativamente a las de otra persona. Esto se denomina control de simultaneidad y existen dos estrategias de bloqueo básicas: pesimista y optimista. El bloqueo puede impedir que los usuarios modifiquen los datos de forma que afecte a otros usuarios. El bloqueo también ayuda a asegurar la integridad de la base de datos, especialmente con consultas que de otra forma podrían producir resultados inesperados Hay diferencias importantes en la forma en que Access y SQL Server implementan estas estrategias de control de simultaneidad.
En Access, la estrategia de bloqueo predeterminada es optimista y concede la propiedad del bloqueo a la primera persona que intenta escribir en un registro. Access le muestra el cuadro de diálogo de conflicto de escritura a la otra persona que intenta escribir en el mismo registro al mismo tiempo. Para resolver este conflicto, la otra persona puede guardar el registro, copiarlo en el portapapeles o descartar los cambios.
También puede usar la propiedad BloqueosDelRegistro para cambiar la estrategia de control de simultaneidad. Esta propiedad afecta los formularios, los informes y las consultas y tiene tres opciones de configuración:
-
Sin bloquear En un formulario, los usuarios pueden intentar modificar el mismo registro al mismo tiempo pero es posible que aparezca el cuadro de diálogo de conflicto de escritura. En los informes, los registros no se bloquean mientras se obtiene una vista previa del informe o se imprime el mismo. En las consultas, los registros no se bloquean mientras se ejecuta la consulta. Esta es la forma en que Access implementa el bloqueo optimista.
-
Todos los registros Todos los registros de la tabla o la consulta subyacentes se bloquean mientras que el formulario está abierto en vista Formulario o vista de Hoja de Datos, mientras se obtienen una vista previa del informe o se imprime el mismo, o bien mientras se ejecuta la consulta. Los usuarios pueden leer los registros durante el bloqueo.
-
Registro modificado En los formularios y las consultas se bloquea una página de registros tan pronto como cualquier usuario empieza a modificar un campo en el registro y permanece bloqueada hasta que el usuario se desplaza a otro registro. En consecuencia, un registro solo puede ser modificado por un usuario a la vez. Esta es la forma en que Access implementa el bloqueo pesimista.
Para obtener más información, vea el Cuadro de diálogo de conflicto de escritura y la Propiedad BloqueosDelRegistro.
En SQL Server, el control de simultaneidad funciona de la siguiente manera:
-
Pesimista Después de que un usuario realiza una acción que provoca la aplicación de un bloqueo, otros usuarios no pueden realizar acciones que entrarían en conflicto con el bloqueo hasta que el propietario lo libere. Este control de simultaneidad se usa principalmente en entornos donde existe un alto nivel de contención de datos.
-
Optimista En el control de simultaneidad optimista, los usuarios no bloquean los datos al leerlos. Cuando un usuario actualiza los datos, el sistema comprueba si otro usuario cambió los datos después de que fueran leídos. Si otro usuario actualizó los datos, se producirá un error. Por lo general, el usuario que recibe el error deshace la transacción y vuelve a empezar. Este control de simultaneidad se usa principalmente en entornos donde existe un bajo nivel de contención de datos.
Puede especificar el tipo de control de simultaneidad seleccionando varios niveles de aislamiento de transacciones, lo que define el nivel de protección de la transacción frente a las modificaciones realizadas por otras transacciones mediante el uso de la instrucción ESTABLECER TRANSACCIÓN:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Nivel de aislamiento |
Descripción |
|
Lectura no confirmada |
Las transacciones se aíslan solo lo suficiente como para asegurarse de que los datos dañados físicamente no se puedan leer. |
|
Lectura confirmada |
Las transacciones pueden leer datos previamente leídos por otra transacción sin tener que esperar a que se complete la primera transacción. |
|
Lectura repetible |
Los bloqueos de lectura y escritura se ejecutan en los datos seleccionados hasta el final de la transacción, pero pueden producirse lecturas fantasma. |
|
Instantánea |
Usa la versión de fila para proporcionar coherencia de lectura a nivel de la transacción. |
|
Serializable |
Las transacciones están completamente aisladas entre sí. |
Para obtener más información, vea la Guía de control de versiones de fila y bloqueo de transacciones.
Mejorar el rendimiento de las consultas
Una vez que tenga una consulta de paso a través ejecutándose, aproveche las formas sofisticadas en las que SQL Server puede hacer que se ejecute de forma más eficaz.
A diferencia de las bases de datos de Access, SQL Server ofrece consultas en paralelo para optimizar la ejecución de consultas y las operaciones de índices de los equipos que tienen más de un microprocesador (CPU). Como SQL Server puede ejecutar una consulta o una operación de índice en paralelo utilizando varios subprocesos de trabajo del sistema, la operación puede completarse de forma rápida y eficaz.
Las consultas son un componente esencial para mejorar el rendimiento general de la solución de la base de datos. Las consultas incorrectas se ejecutan indefinidamente, caducan y usan recursos como las CPU, la memoria y ancho de banda. Esto dificulta la disponibilidad de información esencial para el negocio. Incluso una sola consulta incorrecta puede causar serios problemas de rendimiento en la base de datos.
Para obtener más información, vea Consultar más rápido con SQL Server (libro electrónico).
Optimización de consultas
Varias herramientas funcionan de forma conjunta para ayudarle a analizar el rendimiento de una consulta y mejorarla: Optimizador de consultas, planes de ejecución y almacén de consultas.
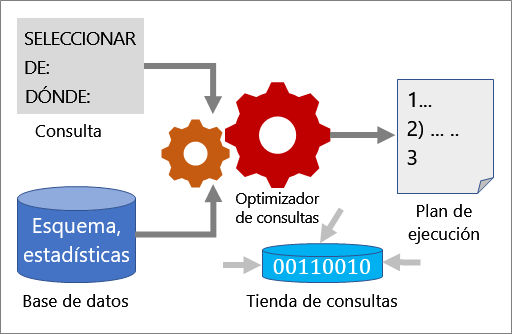
Optimizador de consultas
El optimizador de consultas es uno de los componentes más importantes de SQL Server. Use el optimizador de consultas para analizar una consulta y determinar la manera más eficaz de tener acceso a los datos necesarios. La entrada para el optimizador de consultas se compone de la consulta, el esquema de la base de datos (definiciones de tabla e índices) y estadísticas de la base de datos. El resultado del optimizador de consultas es un plan de ejecución.
Para obtener más información, consulte el Optimizador de consultas de SQL Server.
Plan de ejecución
Un plan de ejecución es una definición que secuencia las tablas de origen a acceder y los métodos utilizados para extraer los datos de cada tabla. La optimización es el proceso de selección de un plan de ejecución entre los muchos posibles planes. Cada plan de ejecución posible tiene un costo asociado en la cantidad de recursos computacionales utilizados y el optimizador de consultas elige el que tiene el costo estimado más bajo.
SQL Server también tiene que ajustarse dinámicamente a las condiciones cambiantes de la base de datos. Las regresiones en los planes de ejecución de las consultas pueden afectar mucho al rendimiento. Algunos cambios en una base de datos pueden causar que un plan de ejecución sea ineficaz o no válido, basándose en el nuevo estado de la base de datos. SQL Server detecta los cambios que invalidan un plan de ejecución y marca el plan como no válido.
Luego, debe recopilarse un nuevo plan para la siguiente conexión que ejecute la consulta. Entre las condiciones que invalidan un plan se incluyen:
-
Cambios realizados en una tabla o vista referenciados por la consulta (MODIFICAR TABLA y MODIFICAR VISTA).
-
Cambios en los índices utilizados por el plan de ejecución.
-
Actualizaciones de estadísticas utilizadas por el plan de ejecución, generadas tanto explícitamente a partir de una instrucción, tal como ACTUALIZAR ESTADÍSTICAS como automáticamente.
Para obtener más información, vea Planes de ejecución.
Tienda de consultas
La tienda de consultas ofrece información sobre el rendimiento y la elección del plan de ejecución. Simplifica la solución de problemas de rendimiento ya que le ayuda a encontrar rápidamente las diferencias de rendimiento causadas por los cambios en los planes de ejecución. La tienda de consultas recopila los datos de telemetría, tales como el historial de consultas, los planes, las estadísticas en tiempo de ejecución y las estadísticas de espera. Use la instrucción MODIFICAR BASE DE DATOS para implementar la tienda de consultas:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Para obtener más información, vea Supervisar el rendimiento con la tienda de consultas.
Corrección automática de planes
Quizás la forma más sencilla de mejorar el rendimiento de las consultas sea con la corrección automática de planes, la cual es una característica disponible en la base de datos Azure SQL. Solo tiene que activarla y dejarla funcionar. Realiza continuamente la supervisión y el análisis del plan de ejecución, detecta planes de ejecución problemáticos y corrige automáticamente los problemas de rendimiento. En segundo plano, la corrección automática de planes usa una estrategia de cuatro pasos: aprender, adaptar, comprobar y repetir.
Para más información, vea Ajuste automático.
Procesamiento de consultas adaptable
También puede obtener consultas más rápidas actualizando a SQL Server 2017, el cual tiene una nueva característica denominada procesamiento de consultas adaptable. SQL Server ajusta las opciones del plan de consultas en función de las características del tiempo de ejecución.
La estimación de cardinalidad se aproxima a la cantidad de filas procesadas en cada paso de un plan de ejecución. Las estimaciones inexactas pueden resultar en tiempos de respuesta de consultas lentos, utilización de recursos innecesarios (memoria, CPU y E/S) y reducción del rendimiento y la concurrencia. Se usan tres técnicas para adaptarse a las características de la carga de trabajo de la aplicación:
-
Comentarios para la concesión de memoria en modo de lotes Un cálculo deficiente de la cardinalidad puede hacer que las consultas se "derramen en el disco" o que ocupen demasiada memoria. SQL Server 2017 ajusta las concesiones de memoria en función de los comentarios de ejecución, quita el derrame en disco y mejora la simultaneidad para la repetición de consultas.
-
Combinaciones adaptables en modo de lotes Las combinaciones adaptables seleccionan de manera dinámica un mejor tipo de combinación interno (combinaciones de bucles anidados, combinaciones de fusión o combinaciones hash) durante el tiempo de ejecución, en función de las filas de entrada reales. Por lo tanto, un plan puede cambiar de manera dinámica hacia una mejor estrategia de combinación durante la ejecución.
-
Ejecución intercalada Tradicionalmente, las funciones de tabla con valores de varias instrucciones se han considerado como una caja negra para el procesamiento de consultas. SQL Server 2017 puede estimar mejor el recuento de filas para mejorar las operaciones de bajada.
Puede hacer que las cargas de trabajo sean automáticamente válidas para el procesamiento adaptable de consultas habilitando un nivel de compatibilidad de 140 para la base de datos:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Para obtener más información, vea el Procesamiento inteligente de consultas en bases de datos SQL.
Formas de consultar
En SQL Server existen varias formas de consultar, y cada una de ellas tiene sus ventajas. Debe conocer cuáles son para poder elegir la opción adecuada para su solución de Access. La mejor forma de crear consultas TSQL es editarlas y probarlas de forma interactiva con el editor Transact-SQL de SQL Server Management Studio (SSMS), el cual tiene IntelliSense para ayudarle a elegir las palabras clave adecuadas y comprobar si hay errores de sintaxis.
Vistas
En SQL Server, una vista es como una tabla virtual donde los datos de la vista provienen de una o más tablas o de otras vistas. Sin embargo, en las consultas a las vistas se las referencia igual que a las tablas. Las vistas pueden ocultar la complejidad de las consultas y ayudar a proteger los datos limitando el conjunto de filas y columnas. Este es un ejemplo de una vista simple:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Para obtener un rendimiento óptimo y editar los resultados de la vista, cree una vista indexada que se mantenga en la base de datos como una tabla, tenga almacenamiento asignado a ella y se puede consultar como cualquier otra tabla. Para usarla en Access, cree un vínculo a la vista de la misma manera que se vincula a una tabla. Este es un ejemplo de una vista indexada:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Sin embargo, existen restricciones. No se pueden actualizar los datos si hay más de una tabla base afectada o si la vista contiene funciones de agregado o una cláusula DISTINCT. Si SQL Server devuelve un mensaje de error indicando que no sabe qué registro debe eliminar, es posible que tenga que agregar un desencadenador de eliminación a la vista. Por último, no se puede usar la cláusula ORDER BY como se haría con una consulta de Access.
Para obtener más información, vea Vistas y Crear vistas indexadas.
Procedimientos almacenados
Un procedimiento almacenado es un grupo de una o más instrucciones TSQL que aceptan parámetros de entrada, devuelven parámetros de salida e indican si el valor de estado es correcto o incorrecto. Actúan como nivel intermedio entre el front-end de Access y el back-end de SQL Server. Los procedimientos almacenados pueden ser tan sencillos como una instrucción SELECT o tan complejo como cualquier programa. Aquí tenemos un ejemplo:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Cuando se usa un procedimiento almacenado en Access, suele devolver un conjunto de resultados en un formulario o informe. Sin embargo, puede llevar a cabo otras acciones que no devuelvan resultados, tales como instrucciones DDL o DML. Cuando utilice una consulta de paso a través, asegúrese de establecer la propiedad de Registros devueltos correctamente.
Para obtener más información, vea Procedimientos almacenados.
Expresiones de tablas comunes
Una expresión de tabla común (CTE) es como una tabla temporal que genera un conjunto de resultados con nombre. Solo existe para la ejecución de una única consulta o instrucción DML. Una CTE está integrada en la misma línea de código que la instrucción SELECT o la instrucción DML que la utiliza, mientras que la creación y el uso de una tabla o vista temporal es generalmente un proceso de dos pasos. Aquí tenemos un ejemplo:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
Una CTE tiene varias ventajas, entre las que se incluyen las siguientes:
-
Como las CTE son transitorias, no es necesario crearlas como objetos de base de datos permanentes como las vistas.
-
Puede hacer referencia a la misma CTE más de una vez en una misma consulta o instrucción DML, lo que hace que el código sea más manejable.
-
Puede usar consultas que hacen referencia a una CTE para definir un cursor.
Para obtener más información, vea CON common_table_expression.
Funciones definidas por el usuario
Una función definida por el usuario (UDF) puede realizar consultas y cálculos y devolver tanto valores escalares o conjuntos de resultados de datos. Son similares a las funciones de los lenguajes de programación que aceptan parámetros, realizan una acción tal como un cálculo complejo, y devuelven el resultado de dicha acción como un valor. Aquí tenemos un ejemplo:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Una UDF tiene ciertas limitaciones. Por ejemplo, no pueden usar determinadas funciones del sistema no deterministas, realizar instrucciones DML o DDL ni consultas SQL dinámicas.
Para obtener más información, vea Funciones definidas por el usuario.
Agregar claves e índices
Independientemente del sistema de base de datos que use, las claves y los índices van de la mano.
Claves
En SQL Server, asegúrese de crear claves principales para cada tabla y claves externas para cada tabla relacionada. La característica en SQL Server equivalente al tipo de datos de autonumeración de Access es la propiedad IDENTITY, que se puede usar para crear valores de clave. Una vez que se le aplica esta propiedad a cualquier columna numérica, pasa a ser de solo lectura y la mantiene el sistema de la base de datos. Cuando inserta un registro en una tabla que contiene una columna de IDENTIDAD, el sistema incrementa automáticamente el valor de la columna de IDENTIDAD por 1 y empezando desde 1, pero puede controlar estos valores con argumentos.
Para obtener más información, vea CREAR TABLA, Identidad (Propiedad).
Índices
Como siempre, la selección de índices es un acto de equilibrio entre la velocidad de la consulta y el costo de actualización. En Access, tiene un solo tipo de índice, pero en SQL Server tiene doce. Afortunadamente, puede usar el optimizador de consultas para ayudarle a elegir el índice más eficaz con confiabilidad. Y en Azure SQL, puede usar la administración automática de índices, una característica del ajuste automático, la cual recomienda agregar o quitar índices por usted. A diferencia de Access, debe crear índices propios para las claves externas en SQL Server. También puede crear índices en una vista indexada para mejorar el rendimiento de las consultas. La desventaja de una vista indexada se incrementa en mayor medida al modificar los datos de las tablas base de las vistas, porque también es necesario actualizar la vista. Para obtener más información, vea Arquitectura de índices de SQL Server y guía de diseño e Índices.
Ejecutar transacciones
Realizar un proceso de transacciones en línea (OLTP) es difícil cuando se usa Access, pero es relativamente fácil con SQL Server. Una transacción es una sola unidad de trabajo que confirma todos los cambios realizados en los datos cuando son exitosos, pero revierte los cambios cuando no lo son. Una transacción debe tener cuatro propiedades, que a menudo se denominan ACID:
-
Atomicidad Una transacción debe ser una unidad de trabajo atómica: todas las modificaciones de datos se realizan, o bien no se realiza ninguna.
-
Coherencia Cuando haya finalizado, la transacción debe dejar todos los datos en un estado coherente. Esto significa que se aplican todas las reglas de integridad de los datos.
-
Aislamiento Los cambios realizados por las transacciones simultáneas se aíslan de la transacción actual.
-
Durabilidad Una vez completada una transacción, los cambios son permanentes incluso en caso de que se produzca un error del sistema.
Utilice una transacción para asegurar la integridad garantizada de los datos, tal como una retirada de efectivo de un cajero automático o un depósito automático de un sueldo. Puede realizar transacciones explícitas, implícitas o en el ámbito por lotes. Aquí se muestran dos ejemplos de TSQL:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Para obtener más información, vea Transacciones.
Usar restricciones y desencadenadores
Todas las bases de datos tienen formas para mantener la integridad de los datos.
Restricciones
En Access, se debe exigir la integridad referencial en una relación de tabla mediante pares clave externa-clave principal, actualizaciones y eliminaciones en cascada, y reglas de validación. Para obtener más información, vea la Guía de relaciones de tablas y Restringir la entrada de datos mediante reglas de validación.
En SQL Server, se utilizan restricciones UNIQUE y CHECK, que son objetos de base de datos que exigen la integridad de los datos en las tablas de SQL Server. Para comprobar si un valor es válido en otra tabla, utilice una restricción de clave externa. Para comprobar que un valor de una columna se encuentra dentro de un rango específico, utilice una restricción de comprobación. Estos objetos son su primera línea de defensa y están diseñados para trabajar de forma eficaz. Para obtener más información, vea Restricciones únicas y restricciones de comprobación.
Desencadenadores
Access no tiene desencadenadores de base de datos. En SQL Server, puede usar los desencadenadores para exigir reglas complejas de integridad de datos y para ejecutar esta lógica de negocios en el servidor. Un desencadenador de base de datos es un procedimiento almacenado que se ejecuta cuando se ejecutan ciertas acciones en una base de datos. El desencadenador es un evento, como por ejemplo agregar o eliminar un registro de una tabla, lo que activa, y luego ejecuta, el procedimiento almacenado. Aunque una base de datos de Access pueda asegurar la integridad referencial cuando un usuario intenta actualizar o eliminar datos, SQL Server tiene un conjunto sofisticado de desencadenadores. Por ejemplo, puede programar un desencadenador para eliminar registros en masa y asegurar la integridad de los datos. Incluso puede agregar desencadenadores a tablas y vistas.
Para obtener más información, vea Desencadenadores: DML, Desencadenadores: DDL y Diseñar un desencadenador T-SQL.
Usar columnas calculadas
En Access, puede crear una columna calculada agregándola a una consulta y creando una expresión, tal como:
Extended Price: [Quantity] * [Unit Price]
En SQL Server, la característica equivalente también se denomina columna calculada, y es una columna virtual que no se almacena físicamente en la tabla, a menos que la columna se marque como PERSISTENTE. Al igual que la columna calculada de Access, la misma utiliza los datos de otras columnas en una expresión. Para crear una columna calculada, agréguela a una tabla. Por ejemplo:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Para obtener más información, vea Especificar columnas calculadas en una tabla.
Marca de tiempo para los datos
En ocasiones, puede agregar un campo de tabla para registrar una marca de tiempo cuando se crea un registro para que pueda registrar la entrada de datos. En Access, puede crear simplemente una columna de fecha con el valor predeterminado de =Now(). Para registrar una fecha o una hora en SQL Server, utilice el tipo de datos datetime2 con el valor predeterminado de SYSDATETIME().
Nota Evite confundir rowversion con el agregado de marcas de tiempo a los datos. Las palabras clave marca de tiempo son sinónimo de rowversion en SQL Server, pero debe utilizar la palabra clave rowversion. En SQL Server, rowversion es un tipo de datos que exponen los números binarios únicos generados automáticamente dentro de una base de datos y generalmente se usa como mecanismo para marcar la versión de las filas de una tabla. Sin embargo, el tipo de datos rowversion es solo un número que se incrementa, no conserva una fecha o una hora, y no está diseñado para marcar el tiempo en una fila.
Para más información, vea rowversion. Para obtener más información sobre el uso de rowversion para minimizar los conflictos de registro, vea Migrar una base de datos de Access a SQL Server.
Administrar objetos grandes
En Access, puede administrar los datos no estructurados, como archivos, fotos e imágenes, usando los Tipo de datos de datos adjuntos. En la terminología de SQL Server, los datos no estructurados se denominan Blob (objeto binario grande) y existen varias formas de trabajar con ellos:
FILESTREAM Usa el tipo de datos varbinary (max) para almacenar los datos no estructurados en el sistema de archivos en lugar de en la base de datos. Para obtener más información, vea Acceder a los datos del FILESTREAM con Transact-SQL.
FileTable Almacena blobs en tablas especiales llamadas FileTables y proporciona compatibilidad con aplicaciones de Windows como si estuvieran almacenadas en el sistema de archivos y sin realizar cambios en las aplicaciones del cliente. FileTable requiere el uso de FILESTREAM. Para más información, vea FileTables.
Almacén remoto de blobs (RBS) Almacena objetos binarios grandes (BLOB) en soluciones de almacenamiento de mercancías en lugar de directamente en el servidor. Así se ahorra espacio y se reducen los recursos de hardware. Para obtener más información, vea Datos de objetos binarios grandes (Blob).
Trabajar con datos jerárquicos
Aunque las bases de datos relacionales como Access son muy flexibles, trabajar con relaciones jerárquicas es una excepción y a menudo requiere códigos e instrucciones SQL complejas. Entre los ejemplos de datos jerárquicos se incluyen: una estructura organizativa, un sistema de archivos, una taxonomía de términos de lenguaje y un gráfico de vínculos entre páginas Web. SQL Server tiene un tipo de datos HierarchyId y un conjunto de funciones jerárquicas integrados para almacenar, consultar y administrar fácilmente los datos jerárquicos.
Para obtener más información, vea Datos jerárquicos y Tutorial: Usar el tipo de datos HierarchyId
Manipular texto JSON
La notación de objetos JavaScript (JSON) es un servicio Web que usa lenguaje natural para transmitir datos como pares de atributo-valor en una comunicación asincrónica entre navegador y servidor. Por ejemplo:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Access no tiene ninguna manera integrada para administrar los datos JSON, pero en SQL Server puede almacenar, indexar, consultar y extraer los datos JSON sin problemas. Puede convertir y almacenar texto JSON en una tabla o dar formato a los datos como texto JSON. Por ejemplo, es posible que quiera dar formato JSON a los resultados de la consulta para una aplicación web o agregar estructuras de datos JSON a las filas y columnas.
Nota JSON no es compatible con VBA. Como alternativa, puede usar XML en VBA usando la biblioteca MSXML.
Para obtener más información, vea Datos JSON en SQL Server.
Recursos
Este es un buen momento para obtener más información acerca de SQL Server y Transact SQL (TSQL). Como ha visto, hay muchas características como las de Access, pero también funciones que Access simplemente no tiene. Aquí se muestran algunos recursos de aprendizaje para llevar su excursión al siguiente nivel:
|
Recurso |
Descripción |
|
Curso basado en vídeo |
|
|
Ttutorials acerca de SQL Server 2017 |
|
|
Aprendizaje para Azure |
|
|
Convertirse en un experto |
|
|
La página de aterrizaje principal |
|
|
Información de ayuda |
|
|
Información de ayuda |
|
|
La guía fundamental para los datos en la nube (libro electrónico) |
Información general de la nube |
|
Un resumen visual de las nuevas características |
|
|
Un resumen de las características por versiones |
|
|
Descargar SQL Server Express 2017 |
|
|
Descargar bases de datos de ejemplo |






