

Try it!
Databases and web apps can yield big business advantages. Database design is critical to achieving your goals, whether you want to manage employee information, provide weekly reports against data, or track customer orders. Investing the time to understand database design will help you build databases that work right the first time and that accommodate changing needs.
Important: Access web apps are different from desktop databases. This article doesn't discuss web app design.
Concepts and terms
Let’s start by learning some basic terms and concepts. To design a useful database, you create tables that focus on one subject. In your tables, you capture all the data needed for that subject in fields, which hold the smallest possible unit of data.
|
Relational databases |
A database in which data is divided into tables, which are kind of like spreadsheets. Each table has just one subject, such as customers (one table) or products (another table). |
|
Records and fields |
Storage for the discrete data in a table. Rows (or records) store each unique data point, such as the name of a customer. Columns (or fields) isolate the information being captured about each data point into the smallest possible unit—first name might be one column and last name might be another. |
|
Primary key |
A value that ensures each record is unique. For example, there might be two customers with the same name, Elizabeth Andersen. But one of the Elizabeth Andersen records has the number 12 as its primary key and the other has a primary key of 58. |
|
Parent-child relationships |
Common relationships between tables. For example, a single customer may have multiple orders. Parent tables have primary keys. Child tables have foreign keys, which are values from the primary key that show how the child table records are linked to the parent table. These keys are linked by a relationship. |
What is good database design?
Two principles are fundamental to good database design:
-
Avoid duplicate information (also called redundant data). It wastes space and increases the likelihood of errors.
-
Ensure that data is correct and complete. Incomplete or erroneous information flows through in queries and reports and may ultimately lead to misinformed decisions.
To help with these issues:
-
Divide database information into subject-based tables with a narrow focus. Avoid duplicating information in multiple tables. (For example, customer names should go in only one table.)
-
Join the tables together using keys instead of duplicating data.
-
Include processes that support and ensure the accuracy and integrity of database information.
-
Design your database with your data processing and reporting needs in mind.
To improve the long-term usefulness of your databases, follow these five design steps:
Step 1: Determine the purpose of your database
Before you start, have a goal for your database.
To keep your design focused, summarize the purpose of the database and refer to the summary often. If you want a small database for a home-based business, for example, you might write something simple, like, “The customer database keeps a list of customer information for the purpose of producing mailings and reports.” For an enterprise database, you might need multiple paragraphs to describe when and how people in different roles will use the database and its data. Create a specific and detailed mission statement to refer to throughout the design process.
Step 2: Find and organize required information
Gather all of the types of information you want to record, such as your product names and order numbers.
Start with your existing information and tracking methods. For example, maybe you currently record purchase orders in a ledger or you keep customer information on paper forms. Use those sources to list the information you currently capture (for example, all the boxes on your forms). Where you don’t currently capture important information, think about what discrete information you need. Each individual data type becomes a field in your database.
Don’t worry about making your first list perfect—you can fine-tune it over time. But do consider all the people who use this information, and ask for their ideas.
Next, think about what you want out of the database and the types of reports or mailings you want to produce. Then, make sure you’re capturing the information required to meet those goals. For example, if you want a report that shows sales by region, you need to capture the sales data at the regional level. Try to sketch out the report with the actual information as you’d like to see it. Then, list the data that you need to create the report. Do the same thing for mailings or other outputs you want from the database.
Example
Suppose you give customers the opportunity to opt in to (or out of) periodic email updates, and you want to print a list of those who have opted in. You need a Send Email column in the Customer table, with allowable values of Yes and No.
For those willing to receive emails, you need an email address, which also requires a field. If you want to include a proper salutation (such as Mr., Mrs., or Ms.), include a Salutation field. If you want to address customers by their first name in emails, add a First Name field.
Tip: Remember to break each piece of information into its smallest useful part, such as first name and last name for a customer table. In general, if you want to sort, search, calculate, or report based on an item of information (such as customer last name), you should put that item in its own field.
Step 3: Divide information into tables
Divide your information items into major entities or subjects, such as products, customers, and orders. Each subject becomes a table.
After you have your list of required information, determine the major entities (or subjects) you need to organize your data. Avoid duplicating data across entities. For example, the preliminary list for a product sales database might look like this:

The major entities are: customers, suppliers, products, and orders. So start out with those four tables: one for facts about customers, one for facts about suppliers, and so on. This may not be your final design, but it’s a good starting point.
Note: The best databases contain multiple tables. Avoid the temptation to place all your information in a single table. This results in duplicate information, larger database size, and increased errors. Design to record each fact just once. If you find yourself repeating information, such as a supplier address, restructure your database to place that information in a separate table.
To understand why more tables are better than fewer, consider the table shown here:
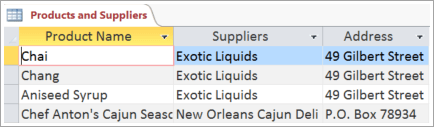
Each row contains information about both the product and its supplier. Because you may have many products from the same supplier, the supplier name and address information has to be repeated many times. This wastes disk space. Instead, record the supplier information only once in a separate Suppliers table and then link that table to the Products table.
A second problem with this design is evident when you need to modify information about the supplier. Suppose you need to change a supplier's address. Because it appears in many places, you might accidentally change the address in one place but forget to change it in the others. Recording the supplier’s address in only one place solves that problem.
Finally, suppose there is only one product supplied by Coho Winery, and you want to delete the product but retain the supplier name and address information. With this design, how would you delete the product record without also losing the supplier information? You can't. Because each record contains facts about a product in addition to facts about a supplier, it’s impossible to delete one without deleting the other. To keep these facts separate, split this table into two: the first for product information and the second for supplier information. Then, when you delete a product record, you delete only the facts about the product—not the facts about the supplier.
Step 4: Turn information items into columns
Decide what information you need to store in each table. These discrete pieces of data become fields in the table. For example, an Employees table might include fields such as Last Name, First Name, and Hire Date.
After you’ve chosen the subject for a database table, the columns in that table should only store facts about that single subject. For instance, a product table should store facts only about products—not about their suppliers.
To decide what information to track in the table, use the list you created earlier. For example, the Customers table might include: First Name, Last Name, Address, Send Email, Salutation, and Email Address. Each record (customer) in the table contains the same set of columns, so you store exactly the same information for each customer.
Create your first list, and then review and refine it. Remember to break information down into the smallest possible fields. For example, if your initial list has Address as a field, break that down into Street Address, City, State, and Zip Code—or, if your customers are global, into even more fields. That way, for example, you can do mailings in the proper format or report on orders by state.
After you have refined the data columns in each table, you are ready to choose each table's primary key.
Step 5: Specify primary keys
Choose each table’s primary key. The primary key, such as Product ID or Order ID, uniquely identifies each record. If you don’t have an obvious, unique identifier, use Access to create one for you.
You need a way to uniquely identify each row in each table. Remember the earlier example where two customers have the same name? Because they share a name, you need a way to separately identify each one.
So every table should include a column (or set of columns) that uniquely identifies each row. This is called the primary key and is often a unique number, such as an employee ID number or a serial number. Access uses primary keys to quickly associate data from multiple tables and to bring the data together for you.
Sometimes the primary key consists of two or more fields. For example, an Order Details table that stores line items for orders might use two columns in its primary key: Order ID and Product ID. When a primary key employs more than one column, it is also called a composite key.
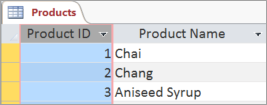
If you already have a unique identifier for the information in a table, such as product numbers that uniquely identify each product in your catalog, use that, but only if the values meet these rules for primary keys:
-
The identifier will always be different for each record. Duplicate values are not permitted in a primary key.
-
There is always a value for the item. Every record in your table must have a primary key. If you are using multiple columns to create the key (like Part Family and Part Number), both values must always be present.
-
The primary key is a value that doesn’t change. Because the keys are referenced by other tables, any change to a primary key in one table means a change to it everywhere it’s referenced. Frequent changes increase the risk of errors.
If you don’t have an obvious identifier, use an arbitrary, unique number as the primary key. For example, you might assign each order a unique order number for the sole purpose of identifying the order.
Tip: To create a unique number as the primary key, add a column using the AutoNumber data type. The AutoNumber data type automatically assigns a unique, numeric value to each record. This type of identifier contains no factual information describing the row it represents. It’s ideal for use as a primary key because the numbers don’t change—unlike a primary key that contains facts about a row, like a telephone number or a customer name.
Want more?



Need more help?
Want more options?
Explore subscription benefits, browse training courses, learn how to secure your device, and more.




Communities help you ask and answer questions, give feedback, and hear from experts with rich knowledge.


