
Nachdem Sie Ihre Daten von Access zu SQL Server migriert haben, verfügen Sie jetzt über eine Client/Server-Datenbank, bei der es sich entweder um eine lokale oder hybride Azure-Cloudlösung handeln kann. In beiden Fällen ist Access nun die Präsentationsschicht und SQL Server die Datenschicht. Jetzt ist ein guter Zeitpunkt, um Aspekte Ihrer Lösung, insbesondere Abfrageleistung, Sicherheit und Geschäftskontinuität, zu überdenken, damit Sie Ihre Datenbanklösung verbessern und skalieren können.
Ein Access-Benutzer, der sich zum ersten Mal mit der SQL Server- und Azure-Dokumentation befasst, kann sich entmutigt fühlen. Dies verlangt nach jemandem, der Sie an die Hand nimmt und durch die Highlights führt, die für Sie wichtig sind. Sobald Sie diese Exkursion abgeschlossen haben, sind Sie bereit, die Fortschritte in der Datenbanktechnologie zu erkunden und sich näher damit zu befassen.
Inhalt dieses Artikels
|
Datenbankverwaltung Fördern der Geschäftskontinuität Umgang mit Datenschutzbedenken |
Abfragen und verwandte Features Verbessern der Abfrageleistung Möglichkeiten zum Durchführen von Abfragen |
Datentypen Verwenden von berechneten Spalten |
Verschiedenes |
Fördern der Geschäftskontinuität
Sie möchten die Betriebsbereitschaft Ihrer Access-Lösung mit minimalen Unterbrechung gewährleisten, aber Ihre Optionen mit einer Access-Back-End-Datenbank sind begrenzt. Das Sichern Ihrer Access-Datenbank ist für den Schutz Ihrer Daten unerlässlich, erfordert aber, dass Ihre Benutzer offline gehen. Zudem treten ungeplante Ausfallzeiten durch Hardware-/Softwarewartungsupgrades, Netzwerk- oder Stromausfälle, Hardwarefehler, Sicherheitsverletzungen oder sogar Cyberangriffe auf. Um die Ausfallzeiten und Auswirkungen auf Ihr Unternehmen zu minimieren, können Sie eine SQL Server-Datenbank sichern, während sie in Betrieb ist. SQL Server bietet darüber hinaus auch Strategien für Hochverfügbarkeit (High Availability, HA) und Notfallwiederherstellung (Disaster Recovery, DR). Diese beiden kombinierten Technologien werden als HADR bezeichnet. Weitere Informationen finden Sie unter Geschäftskontinuität und Datenbankwiederherstellung sowie Fördern der Geschäftskontinuität mit SQL Server (e-Book).
Sicherung während des Betriebs
SQL Server verwendet einen Onlinesicherungsprozess, der ausgeführt werden kann, während die Datenbank verwendet wird. Sie können vollständige, Teil- oder Dateisicherungen ausführen. Bei einer Sicherung werden die Daten und die Transaktionsprotokolle kopiert, um einen vollständigen Wiederherstellungsvorgang zu gewährleisten. Besonders in einer lokalen Lösung sollten Sie sich der Unterschiede zwischen einfachen und vollständigen Wiederherstellungsoptionen und deren Auswirkungen auf das Anwachsen des Transaktionsprotokolls bewusst sein. Weitere Informationen finden Sie unter Wiederherstellungsmodelle.
Die meisten Sicherungsvorgänge erfolgen sofort, mit Ausnahme von Dateiverwaltungs- und Datenbankverkleinerungsvorgängen. Wenn Sie hingegen versuchen, eine Datenbankdatei zu erstellen oder zu löschen, während ein Sicherungsvorgang ausgeführt wird, tritt ein Fehler auf. Weitere Informationen finden Sie unter Sicherungen
HADR
Die beiden häufigsten Techniken zum Erzielen von Hochverfügbarkeit und Geschäftskontinuität sind Spiegelung und Clustering. SQL Server integriert Spiegelungs- und Clusteringtechnologie mit Always On-Failoverclusterinstanzen und Always On-Verfügbarkeitsgruppen.
Bei der Spiegelung handelt es sich um eine Lösung für Kontinuität auf Datenbankebene, die ein nahezu sofortiges Failover unter Verwendung einer Standbydatenbank unterstützt, einer vollständigen Kopie bzw. Spiegelkopie der aktiven Datenbank, die auf separater Hardware verwaltet wird. Sie kann in einem synchronen Modus (hohe Sicherheit) betrieben werden, in dem für eine eingehende Transaktion auf allen Servern gleichzeitig ein Commit ausgeführt wird, oder in einem asynchronen Modus (hohe Leistung), in dem für eine eingehende Transaktion in der aktiven Datenbank ein Commit ausgeführt wird, und die Transaktion dann zu einem bestimmten Zeitpunkt an die Spiegelkopie übertragen wird. Die Spiegelung ist eine Lösung auf Datenbankebene und funktioniert nur mit Datenbanken, die das vollständige Wiederherstellungsmodell verwenden.
Clustering ist eine Lösung auf Serverebene, die Server in einem einzigen Datenspeicher kombiniert, der für den Benutzer wie eine einzige Instanz aussieht. Benutzer stellen die Verbindung mit der Instanz her und brauchen nie zu wissen, welcher Server in der Instanz gerade aktiv ist. Wenn ein Server ausfällt oder zur Wartung offline genommen werden muss, ändert sich die Benutzererfahrung nicht. Jeder Server im Cluster wird vom Cluster-Manager mit einem Heartbeat überwacht. Dieser erkennt, sobald der aktive Server im Cluster offline geht und versucht, nahtlos zum nächsten Server im Cluster zu wechseln. Allerdings ist die Zeitverzögerung bei diesem Wechsel variabel.
Weitere Informationen finden Sie unter Always On-Failoverclusterinstanzen und Always On-Verfügbarkeitsgruppen: eine Hochverfügbarkeits- und Notfallwiederherstellungslösung.
SQL Server-Sicherheit
Sie können Ihre Access-Datenbank zwar schützen, indem Sie das Trust Center verwenden und die Datenbank verschlüsseln, SQL Server verfügt aber zudem über erweiterte Sicherheitsfunktionen. Sehen wir uns drei Funktionen an, die für den Access-Benutzer besonders gut geeignet sind. Weitere Informationen finden Sie unter Sichern von SQL Server.
Datenbankauthentifizierung
Es gibt vier Datenbankauthentifizierungsmethoden in SQL Server, von denen jede in einer ODBC-Verbindungszeichenfolge angegeben werden kann. Weitere Informationen finden Sie unter Verknüpfen oder Importieren von Daten aus einer Azure SQL Server-Datenbank. Jede Methode bietet eigene Vorteile.
Integrierte Windows-Authentifizierung Verwenden Sie Windows-Anmeldeinformationen für Benutzervalidierung, Sicherheitsrollen und die Beschränkung der für Benutzer verfügbaren Funktionen und Daten. Sie können Domänenanmeldeinformationen nutzen und Benutzerrechte mühelos in Ihrer Anwendung verwalten. Geben Sie optional einen Dienstprinzipalnamen (SPN) ein. Weitere Informationen finden Sie unter Auswählen eines Authentifizierungsmodus.
SQL Server-Authentifizierung Benutzer müssen die Verbindung mit den in der Datenbank eingerichteten Anmeldeinformationen herstellen, indem sie die Anmelde-ID und das Kennwort eingeben, wenn Sie in der Sitzung zum ersten Mal auf die Datenbank zugreifen. Weitere Informationen finden Sie unter Auswählen eines Authentifizierungsmodus.
Integrierte Active Directory-Authentifizierung Stellen Sie die Verbindung zur Azure SQL Server-Datenbank mithilfe von Azure Active Directory her. Nachdem Sie die Azure Active Directory-Authentifizierung konfiguriert haben, sind keine weiteren Anmeldeinformationen und kein Kennwort erforderlich. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit der SQL-Datenbank unter Verwendung der Azure Active Directory-Authentifizierung.
Active Directory-Kennwortauthentifizierung Stellen Sie eine Verbindung mit in Azure Active Directory eingerichteten Anmeldeinformationen her, indem Sie den Anmeldenamen und das Kennwort eingeben. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit der SQL-Datenbank unter Verwendung der Azure Active Directory-Authentifizierung.
Tipp Verwenden Sie die Bedrohungserkennung, um Benachrichtigungen über anomale Datenbankaktivitäten zu erhalten, die auf potenzielle Sicherheitsbedrohungen für eine Azure SQL Server-Datenbank hinweisen. Weitere Informationen finden Sie unter Bedrohungserkennung von Azure SQL-Datenbank.
Anwendungssicherheit
SQL Server verfügt über zwei Sicherheitsmerkmale auf Anwendungsebene, die Sie mit Access nutzen können.
Dynamische Datenmaskierung Sensible Informationen werden verborgen, indem sie vor nicht berechtigten Benutzern maskiert werden. Beispielsweise können Sie Sozialversicherungsnummern teilweise oder vollständig maskieren.
 Maskierung eines Teils der Daten |
 Maskierung der vollständigen Daten |
Es gibt mehrere Möglichkeiten zum Definieren einer Datenmaske, und Sie können diese auf unterschiedliche Datentypen anwenden. Die Datenmaskierung erfolgt richtliniengesteuert auf Tabellen- und Spaltenebene für einen definierten Satz von Benutzern und wird in Echtzeit auf die Abfrage angewendet. Weitere Informationen finden Sie unter Dynamische Datenmaskierung.
Sicherheit auf Zeilenebene Sie können den Zugriff auf bestimmte Datenbankzeilen mit sensiblen Informationen basierend auf Benutzereigenschaften mit Hilfe von Sicherheit auf Zeilenebene steuern. Das Datenbanksystem wendet diese Zugriffsbeschränkungen an, was das Sicherheitssystem zuverlässiger und robuster macht.

Es gibt zwei Arten von Sicherheitsprädikaten:
-
Ein Filterprädikat filtert Zeilen aus einer Abfrage. Der Filter ist transparent, und der Endbenutzer bemerkt die Filterung nicht.
-
Ein Blockprädikat verhindert unbefugte Aktionen und löst eine Ausnahme aus, wenn eine Aktion nicht ausgeführt werden kann.
Weitere Informationen finden Sie unter Sicherheit auf Zeilenebene.
Schützen von Daten mit Verschlüsselung
Schützen Sie ruhende Daten, Daten während der Übertragung und Daten während der Verwendung, ohne die Datenbankleistung zu beeinträchtigen. Weitere Informationen finden Sie unter SQL Server-Verschlüsselung.
Verschlüsselung ruhender Daten Um personenbezogene Daten vor Offlinemedienangriffen auf der physischen Speicherschicht zu schützen, verwenden Sie die Verschlüsselung ruhender Daten, auch als Transparent Data Encryption (TDE) bezeichnet. Dies bedeutet, dass Ihre Daten auch dann geschützt sind, wenn das physische Medium gestohlen oder unsachgemäß entsorgt wird. TDE führt Verschlüsselung und Entschlüsselung von Datenbanken, Sicherungen und Transaktionsprotokollen in Echtzeit aus, ohne dass Änderungen an Ihren Anwendungen erforderlich sind.
Verschlüsselung während der Übertragung Zum Schutz vor dem Ausspionieren und vor "Man-in-the-Middle"-Angriffen können Sie Daten, die über das Netzwerk übertragen werden, verschlüsseln. SQL Server unterstützt Transport Layer Security (TLS) 1.2 für hochsichere Kommunikation. Das TDS-Protokoll (Tabular Data Stream) wird ebenfalls zum Schutz der Kommunikation über nicht vertrauenswürdige Netzwerke verwendet.
Auf dem Client verwendete Verschlüsselung Um personenbezogene Daten während der Nutzung zu schützen, ist "Always Encrypted" das Feature der Wahl. Persönliche Daten werden von einem Treiber auf dem Clientcomputer verschlüsselt und entschlüsselt, ohne die Verschlüsselungsschlüssel an die Datenbankmaschine weiterzugeben. Dies führt dazu, dass verschlüsselte Daten nur für die Personen sichtbar sind, die für die Verwaltung dieser Daten verantwortlich sind, und nicht für andere Benutzer mit hohen Berechtigungen, die keinen Zugriff haben sollten. Je nach Typ der ausgewählten Verschlüsselung kann "Always Encrypted" einige Datenbankfunktionen wie Suchen, Gruppieren und Indizieren der verschlüsselten Spalten einschränken.
Umgang mit Datenschutzbedenken
Datenschutzbedenken sind so weit verbreitet, dass die Europäische Union durch die DSGVO (EU-Datenschutz-Grundverordnung) gesetzliche Anforderungen definiert hat. Glücklicherweise ist ein SQL-Server-Back-End gut geeignet, diese Anforderungen zu erfüllen. Stellen Sie sich die Implementierung der DSGVO als dreistufiges Framework vor.

Schritt 1: Bewerten und Verwalten des Compliancerisikos
Die DSGVO erfordert, dass Sie persönliche Daten in Tabellen und Dateien identifizieren und inventarisieren. Bei diesen Informationen kann es sich um alles handeln, von Namen, Fotos, E-Mail-Adressen, über Bankverbindungen bis zu Beiträgen in sozialen Netzwerken, medizinischen Daten oder IP-Adressen.
Ein neues in SQL Server Management Studio integriertes Tool, SQL Data Discovery and Classification, hilft Ihnen, sensible Daten zu ermitteln, zu klassifizieren, zu bezeichnen und zu melden, indem zwei Metadatenattribute auf Spalten angewendet werden:
-
Bezeichnungen Um die Vertraulichkeit von Daten zu definieren.
-
Informationstypen Um eine zusätzliche Granularität hinsichtlich der in einer Spalte gespeicherten Datentypen bereitzustellen.
Ein weiterer Ermittlungsmechanismus, den Sie verwenden können, ist die Volltextsuche. Dies umfasst die Verwendung von CONTAINS- und FREETEXT-Prädikaten sowie Funktionen mit Rowset-Werten wie CONTAINSTABLE und FREETEXTTABLE zur Verwendung mit der SELECT-Anweisung. Mithilfe der Volltextsuche können Sie Tabellen nach Wörtern, Wortkombinationen oder Variationen eines Worts, z. B. Synonyme oder Beugungsformen, durchsuchen. Weitere Informationen finden Sie unterVolltextsuche.
Schritt 2: Schutz personenbezogener Daten
Die DSGVO erfordert, dass Sie personenbezogene Daten schützen und den Zugriff darauf einschränken. Zusätzlich zu den Standardschritten, die Sie zur Verwaltung des Zugriffs auf Ihr Netzwerk und Ihre Ressourcen durchführen, wie z. B. Firewalleinstellungen, können Sie SQL Server-Sicherheitsfunktionen verwenden, um den Datenzugriff zu steuern:
-
SQL Server-Authentifizierung, um Benutzeridentitäten zu verwalten und unbefugten Zugriff zu verhindern.
-
Sicherheit auf Zeilenebene, um den Zugriff auf Zeilen in einer Tabelle, basierend auf der Beziehung zwischen dem Benutzer und diesen Daten, zu beschränken.
-
Dynamische Datenmaskierung, um die Exposition personenbezogener Daten durch Maskierung der Daten vor nicht berechtigten Benutzern einzuschränken.
-
Verschlüsselung, um zu gewährleisten, dass personenbezogene Daten während der Übertragung und Speicherung sowie vor Angriffen, auch auf der Serverseite, geschützt sind.
Weitere Informationen finden Sie unter SQL Server-Sicherheit.
Schritt 3: Effiziente Reaktion auf Anforderungen
Die DSGVO erfordert, dass Sie Aufzeichnungen über die Verarbeitung personenbezogener Daten führen und diese Aufzeichnungen den Aufsichtsbehörden auf Anfrage zur Verfügung stellen. Treten Probleme auf, z. B. eine versehentliche Datenfreigabe, erlaubt die Schutzüberwachung Ihnen, schnell zu reagieren. Daten müssen schnell verfügbar sein, wenn eine Meldung erforderlich ist. Beispielweise verlangt die DSGVO, dass Verstöße gegen den Datenschutz der zuständigen Aufsichtsbehörde "innerhalb von 72 Stunden nach Ermittlung des Verstoßes" gemeldet werden.
SQL Server 2017 unterstützt Sie auf verschiedene Arten bei allen Berichterstattungsaufgaben:
-
SQL Server Audit hilft Ihnen, sicherzustellen, dass persistente Datensätze über Datenbankzugriffe und Verarbeitungsaktivitäten vorhanden sind. Es führt ein fein abgestuftes Überwachung durch, die Datenbankaktivitäten verfolgt, um Ihnen zu helfen, potenzielle Bedrohungen, vermuteten Missbrauch oder Sicherheitsverletzungen zu verstehen und zu identifizieren. Sie erhalten einfache Möglichkeiten für Datenforensik.
-
SQL Server-Zeittabellen sind systemversionierte Benutzertabellen, die so konzipiert sind, dass sie den vollständigen Verlauf der Datenänderungen speichern. Diese können Sie für einfache Berichte und Zeitpunktanalysen verwenden.
-
SQL-Sicherheitsrisikobewertung (Vulnerability Assessment, VA) ermöglicht das Ermitteln von Sicherheits- und Berechtigungsproblemen. Wird ein Problem erkannt, können Sie auch einen Drilldown in Datenbanküberprüfungsberichte durchführen, um Maßnahmen zur Lösung der Probleme zu finden.
Weitere Informationen finden Sie unter Create a platform of trust (e-Book) (Erstellen einer Vertrauensplattform (e-Book)) und Journey to GDPR Compliance (Weg zur DSGVO-Compliance).
Erstellen von Datenbankmomentaufnahmen
Bei einer Datenbankmomentaufnahme handelt es sich um eine schreibgeschützte, statische Sicht einer SQL Server-Datenbank zu einem bestimmten Zeitpunkt. Sie können eine Datenbankmomentaufnahme zwar auch durch Kopieren einer Access-Datenbankdatei erstellen, verfügt Access aber nicht wie SQL Server über eine entsprechende integrierte Methode. Sie können eine Datenbankmomentaufnahme verwenden, um Berichte basierend auf den Daten zum Zeitpunkt der Erstellung der Datenbankmomentaufnahme zu schreiben. Sie können eine Datenbankmomentaufnahme auch verwenden, um Verlaufsdaten zu verwalten, z. B. eine Momentaufnahme für jedes Finanzquartal, die Sie verwenden, um Berichte am Ende der Periode zusammenzustellen. Hierbei wird folgende bewährte Methode empfohlen:
-
Benennen Sie die Momentaufnahme Jede Datenbankmomentaufnahme erfordert einen eindeutigen Datenbanknamen. Fügen Sie dem Namen zur leichteren Identifizierung den Zweck und den Zeitrahmen hinzu. Um beispielsweise zwischen 6.00 Uhr und 18.00 Uhr (basierend auf einer 24-Stunden-Uhr) dreimal täglich im 6-Stunden-Rhythmus eine Momentaufnahme der AdventureWorks-Datenbank zu erfassen, nennen Sie die Momentaufnahmen "AdventureWorks_snapshot_0600", "AdventureWorks_snapshot_1200" und "AdventureWorks_snapshot_1800".
-
Beschränken Sie die Anzahl von Momentaufnahmen Jede Datenbankmomentaufnahme bleibt so lange bestehen, bis sie explizit gelöscht wird. Da jede Momentaufnahme weiter wächst, möchten Sie vielleicht Speicherplatz sparen, indem Sie eine ältere Momentaufnahme löschen, nachdem Sie eine neue Momentaufnahme erstellt haben. Wenn Sie beispielsweise tägliche Berichte erstellen, bewahren Sie die Datenbankmomentaufnahme 24 Stunden lang auf, und ersetzen Sie sie dann durch eine neue.
-
Herstellen der Verbindung mit der richtigen Momentaufnahme Um eine Datenbankmomentaufnahme zu verwenden, muss das Access-Front-End den richtigen Speicherort kennen. Wenn Sie eine neue Momentaufnahme durch eine bestehende ersetzen, müssen Sie Access auf die neue Momentaufnahme umleiten. Fügen Sie entsprechende Logik zum Access-Front-End hinzu, um sicherzustellen, dass Sie sich mit der richtige Datenbankmomentaufnahme verbinden.
Hier erfahren Sie, wie Sie eine Datenbankmomentaufnahme erstellen:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Weitere Informationen finden Sie unter Datenbankmomentaufnahmen (SQL Server).
Parallelitätssteuerung
Wenn viele Personen gleichzeitig versuchen, Daten in einer Datenbank zu ändern, ist ein Kontrollsystem erforderlich, damit die von einer Person vorgenommenen Änderungen sich nicht nachteilig auf die einer anderen Person auswirken. Dies wird als Parallelitätssteuerung bezeichnet. Es gibt zwei grundlegende Sperrstrategien, pessimistisch und optimistisch. Sperren kann verhindern, dass Benutzer Daten in einer Weise ändern, die sich auf andere Benutzer auswirkt. Durch Sperren wird zudem die Datenbankintegrität gewährleistet, insbesondere bei Abfragen, die ansonsten zu unerwarteten Ergebnissen führen könnten. Es gibt wichtige Unterschiede in der Art und Weise, wie Access und SQL Server diese Parallelitätssteuerungsstrategien implementieren.
In Access ist die Standardsperrstrategie optimistisch. Die erste Person, die in einen Datensatz zu schreiben versucht, erhält den Besitz an der Sperre. Anderen Personen, die versuchen, gleichzeitig in denselben Datensatz zu schreiben, wird das Dialogfeld Schreibkonflikt angezeigt. Um den Konflikt zu beheben, kann die andere Person den Datensatz speichern, in die Zwischenablage kopieren oder die Änderungen verwerfen.
Mit der RecordLocks-Eigenschaft können Sie die Parallelitätssteuerungsstrategie ändern. Diese Eigenschaft wirkt sich auf Formulare, Berichte und Abfragen aus und weist drei Einstellungen auf:
-
Keine Sperren In Formularen können Benutzer versuchen, denselben Datensatz gleichzeitig zu bearbeiten, aber möglicherweise wird das Dialogfeld Schreibkonflikt angezeigt. In Berichten werden Datensätze nicht gesperrt, während der Bericht in der Vorschau angezeigt oder gedruckt wird. In Abfragen werden Datensätze nicht gesperrt, während die Abfrage ausgeführt wird. Auf diese Weise implementiert Access die optimistische Sperrung.
-
Alle Datensätze Alle Datensätze in der zugrunde liegenden Tabelle oder Abfrage werden gesperrt, während das Formular in der Formularansicht oder Datenblattansicht geöffnet ist, während der Bericht in der Vorschau angezeigt oder gedruckt wird oder während die Abfrage ausgeführt wird. Benutzer können die Datensätze während der Sperre lesen.
-
Bearbeiteter Datensatz Für Formulare und Abfragen wird eine Seite von Datensätzen gesperrt, sobald ein Benutzer beginnt, ein Feld im Datensatz zu bearbeiten, und bleibt so lange gesperrt, bis der Benutzer zu einem anderen Datensatz wechselt. Folglich kann ein Datensatz jeweils nur von einem Benutzer bearbeitet werden. Auf diese Weise implementiert Access die pessimistische Sperrung.
Weitere Informationen finden Sie unter Dialogfeld "Schreibkonflikt" und RecordLocks-Eigenschaft (DatensätzeSperren).
In SQL Server funktioniert Parallelitätssteuerung so:
-
Pessimistisch Nachdem ein Benutzer eine Aktion ausgeführt hat, die bewirkt, dass eine Sperre angewendet wird, können andere Benutzer keine Aktionen ausführen, die mit der Sperre in Konflikt geraten, bis der Besitzer den Datensatz freigibt. Diese Parallelitätssteuerung wird hauptsächlich in Umgebungen verwendet, in denen es häufig zu Konflikten kommt.
-
Optimistisch Bei der optimistischen Parallelitätssteuerung werden die Daten beim Lesen nicht gesperrt. Wenn ein Benutzer Daten aktualisiert, überprüft das System, ob ein anderer Benutzer die Daten nach dem Lesen geändert hat. Hat ein anderer Benutzer die Daten aktualisiert, wird ein Fehler ausgelöst. Normalerweise führt der Benutzer, der den Fehler empfängt, ein Rollback der Transaktion aus und beginnt von vorne. Diese Parallelitätssteuerung wird hauptsächlich in Umgebungen verwendet, in denen es selten zu Konflikten kommt.
Sie können den Typ der Parallelitätssteuerung durch Auswählen verschiedener Isolationsgrade für Transaktionen festlegen. Diese definieren die Schutzebene für die Transaktion für Änderungen, die von anderen Transaktionen mithilfe der SET TRANSACTION-Anweisung vorgenommen werden:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Isolationsgrad |
Beschreibung |
|
Lesen ohne Commit |
Transaktionen werden nur soweit isoliert, um sicherzustellen, dass keine physisch beschädigten Daten gelesen werden. |
|
Lesen mit Commit |
Transaktionen können Daten lesen, die zuvor von einer anderen Transaktion gelesen wurden, ohne auf den Abschluss der ersten Transaktion warten zu müssen. |
|
Wiederholbarer Lesevorgang |
Lese- und Schreibsperren werden für ausgewählte Daten bis zum Ende der Transaktion gesetzt, es können jedoch Phantomlesevorgänge erfolgen. |
|
Momentaufnahme |
Verwendet Zeilenversion, um Lesekonsistenz auf Transaktionsebene bereitzustellen. |
|
Serialisierbar |
Transaktionen sind vollständig voneinander isoliert. |
Weitere Informationen finden Sie im Handbuch zu Transaktionssperren und Zeilenversionsverwaltung.
Verbessern der Abfrageleistung
Sobald Sie eine Access-Pass-Through-Abfrage gestartet haben, nutzen Sie die Vorteile der ausgeklügelten Möglichkeiten von SQL Server, um deren Ausführung effizienter zu machen.
Im Gegensatz zu einer Access-Datenbank bietet SQL Server parallele Abfragen zur Optimierung von Abfrageausführung und Indexvorgängen für Computer mit mehr als einem Mikroprozessor (CPU). SQL Server kann eine Abfrage oder einen Indexvorgang unter Verwendung mehrerer Arbeitsthreads des Systems parallel ausführen und auf diese Weise schnell und effizient abschließen.
Abfragen sind eine wichtige Komponente zur Verbesserung der Gesamtleistung ihrer Datenbanklösung. Ungültige Abfragen laufen auf unbestimmte Zeit, führen zu Timeouts und verbrauchen Ressourcen wie CPU, Arbeitsspeicher und Netzwerkbandbreite. Das beeinträchtigt die Verfügbarkeit kritischer Geschäftsinformationen. Selbst eine einzige ungültige Abfrage kann ernsthafte Leistungsprobleme für Ihre Datenbank verursachen.
Weitere Informationen finden Sie unter Schnellere Abfrage mit SQL Server (e-Book)
Abfrageoptimierung
Mehrere Tools in Kombination helfen Ihnen, die Leistung einer Abfrage zu analysieren und zu verbessern: Abfrageoptimierer, Ausführungspläne und Abfragespeicher.
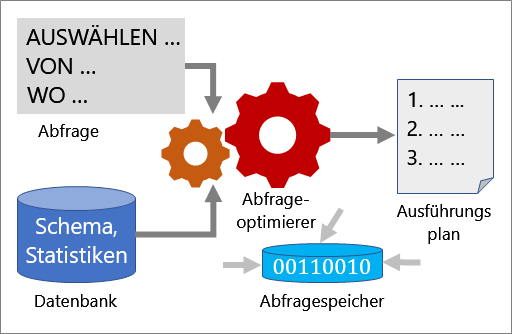
Abfrageoptimierer
Der Abfrageoptimierer ist eine der wichtigsten Komponenten von SQL Server. Verwenden Sie den Abfrageoptimierer, um eine Abfrage zu analysieren und die effizienteste Methode für den Zugriff auf die erforderlichen Daten zu ermitteln. Die Eingabe für den Abfrageoptimierer besteht aus der Abfrage, dem Datenbankschema (Tabellen- und Indexdefinitionen) und Datenbankstatistiken. Die Ausgabe des Abfrageoptimierers ist ein Ausführungsplan.
Weitere Informationen finden Sie unter Der SQL Server-Abfrageoptimierer.
Ausführungsplan
Ein Ausführungsplan ist eine Definition, durch die die Reihenfolge der Quelltabellen, auf die zugegriffen wird, und der Methoden zum Extrahieren von Daten aus jeder Tabelle festgelegt wird. Bei der Optimierung handelt es sich um den Vorgang des Auswählens eines Ausführungsplans aus potenziell vielen möglichen Plänen. Jedem möglichen Ausführungsplan sind Kosten in Höhe der verwendeten Computingressourcen zugeordnet, und der Abfrageoptimierer wählt den Plan mit den niedrigsten geschätzten Kosten aus.
SQL Server muss sich außerdem dynamisch an geänderte Bedingungen in der Datenbank anpassen. Regressionen in Abfrageausführungsplänen können sich erheblich auf die Leistung auswirken. Bestimmte Änderungen in einer Datenbank können dazu führen, dass ein Ausführungsplan aufgrund des neuen Status der Datenbank ineffizient oder ungültig ist. SQL Server erkennt die Änderungen, durch die ein Ausführungsplan ungültig wird, und kennzeichnet den Plan als ungültig.
Für die nächste Verbindung muss dann ein neuer Plan für die Ausführung der Abfrage kompiliert werden. Zu den Bedingungen, durch die ein Plan ungültig wird, gehören:
-
Änderungen, die an einer Tabelle oder Sicht vorgenommen wurden, auf die die Abfrage verweist (ALTER TABLE und ALTER VIEW).
-
Änderungen an Indizes, die vom Ausführungsplan verwendet werden.
-
Aktualisierungen an den vom Ausführungsplan verwendeten Statistiken, die entweder explizit aus einer Anweisung, z.B. UPDATE STATISTICS, oder automatisch generiert werden.
Weitere Informationen finden Sie unter Ausführungspläne
Abfragespeicher
Der Abfragespeicher bietet einen Einblick in die Auswahl und Leistung von Ausführungsplänen. Er vereinfacht die Problembehandlung in Bezug auf Leistung, indem er Ihnen hilft, Leistungsunterschiede, die durch Änderungen des Ausführungsplans verursacht werden, schnell zu finden. Der Abfragespeicher sammelt Telemetriedaten, wie z.B. den Verlauf von Abfragen, Plänen, Laufzeitstatistiken und Wartestatistiken. Verwenden Sie die ALTER DATABASE-Anweisung, um den Abfragespeicher zu implementieren:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Weitere Informationen finden Sie unter Leistungsüberwachung mit dem Abfragespeicher.
Automatische Plankorrektur
Der vielleicht einfachste Weg, die Abfrageleistung zu verbessern, ist die automatische Plankorrektur, ein Feature, das in Azure SQL-Datenbank verfügbar ist. Sie brauchen das Feature lediglich zu aktivieren und es seine Arbeit verrichten lassen. Es führt kontinuierlich die Überwachung und Analyse des Ausführungsplans durch, erkennt problematische Ausführungspläne und behebt Leistungsprobleme automatisch. Hinter den Kulissen verwendet die automatische Plankorrektur eine vierstufige Strategie auf Lernen, Anpassen, Überprüfen und Wiederholen.
Weitere Informationen finden Sie unter Automatische Optimierung.
Adaptive Abfrageverarbeitung
Sie können Abfragen auch beschleunigen, indem Sie auf SQL Server 2017 aktualisieren, der über ein neues Feature namens adaptive Abfrageverarbeitung verfügt. SQL Server passt die Auswahlen des Abfrageplans basierend auf den Laufzeitmerkmalen an.
Die Kardinalitätsschätzung schätzt die Anzahl der bei jedem Schritt in einem Ausführungsplan verarbeiteten Zeilen. Fehlerhafte Schätzungen können zu einer langsamen Beantwortungszeit für Abfragen, unnötiger Ressourcennutzung (Arbeitsspeicher, CPU und E/A) sowie zu einem reduzierten Durchsatz und einer geringeren Parallelität führen. Zur Anpassung an die Merkmale der Anwendungsworkload werden drei Techniken verwendet:
-
Feedback zur Speicherzuweisung (Batchmodus) Schlechte Kardinalitätsschätzungen können dazu führen, dass Abfragen, sich auf den Datenträger auswirken oder zu viel Arbeitsspeicherplatz beanspruchen. SQL Server 2017 passt Speicherzuweisungen basierend auf Ausführungsfeedback an, vermeidet Auswirkungen auf den Datenträger und verbessert die Parallelität bei sich wiederholenden Abfragen.
-
Adaptive Joins (Batchmodus) Adaptive Joins wählen dynamisch während der Laufzeit einen besseren internen Jointyp (Joins geschachtelter Schleifen, Zusammenführungsjoins oder Hashjoins) aus, basierend auf den tatsächlichen Eingabezeilen. Ein Plan kann daher während der Ausführung dynamisch zu einer besseren Joinstrategie wechseln.
-
Verschachtelte Ausführung Tabellenwertfunktionen mit mehreren Anweisungen wurden traditionell von der Abfrageverarbeitung als Blackbox behandelt. SQL Server 2017 kann die Zeilenanzahl besser schätzen, um Downstreamoperationen zu verbessern.
Sie können Workloads automatisch für die adaptive Abfrageverarbeitung qualifizieren, indem Sie eine Kompatibilitätsstufe von 140 für die Datenbank aktivieren:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Weitere Informationen finden Sie unter Intelligente Abfrageverarbeitung in SQL-Datenbanken.
Möglichkeiten zum Durchführen von Abfragen
In SQL Server gibt es mehrere Möglichkeiten zum Durchführen von Abfragen, und sie bieten alle ihre Vorteile. Sie sollten die einzelnen Vorteile kennen, damit Sie die richtige Wahl für Ihre Access-Lösung treffen können. Die beste Möglichkeit zur Erstellung Ihrer TSQL-Abfragen besteht darin, sie mit dem Transact-SQL-Editor von SQL Server Management Studio (SSMS) interaktiv zu bearbeiten und zu testen, der Ihnen mit IntelliSense bei der Auswahl der richtigen Schlüsselwörter und der Suche nach Syntaxfehlern behilflich ist.
Sichten
Eine Sicht in SQL Server ist mit einer virtuellen Tabelle vergleichbar, in der die Daten aus einer oder mehreren Tabellen oder anderen Sichten stammen. Sichten werden in Abfragen jedoch genau wie Tabellen referenziert. Sichten können die Komplexität von Abfragen verbergen und helfen, Daten zu schützen, indem sie den Satz von Zeilen und Spalten einschränken. Hier ein Beispiel für eine einfache Sicht:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Für eine optimale Leistung und zum Bearbeiten der Ergebnisse der Sicht erstellen Sie eine indizierte Sicht. Diese wird wie eine Tabelle in der Datenbank gespeichert, ihr wird Speicherplatz zugewiesen, und sie kann wie jede Tabelle abgefragt werden. Um sie in Access zu verwenden, verknüpfen Sie auf die Sicht auf die gleiche Weise, wie Sie eine Verknüpfung mit einer Tabelle herstellen. Hier ein Beispiel für eine indizierte Sicht:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Es gibt jedoch Einschränkungen. Sie können keine Daten aktualisieren, wenn mehr als eine Basistabelle betroffen ist oder die Sicht aggregierte Funktionen oder eine DISTINCT-Klausel enthält. Wenn SQL Server eine Fehlermeldung zurückgibt, die besagt, dass nicht ermittelt werden kann, welcher Datensatz gelöscht werden soll, müssen Sie möglicherweise einen Löschtrigger für die Ansicht hinzufügen. Außerdem können Sie die ORDER BY-Klausel nicht wie bei einer Abfragen-Abfrage verwenden.
Weitere Informationen finden Sie unter Sichten und Erstellen indizierter Sichten.
Gespeicherte Prozeduren
Bei einer gespeicherten Prozedur handelt es sich um eine Gruppe aus einer oder mehreren TSQL-Anweisungen, die Eingabeparameter annehmen, Ausgabeparameter zurückgeben und Erfolg oder Fehler mit einem Statuswert angeben. Sie fungieren als Zwischenschicht zwischen dem Access-Front-End und dem SQL Server-Back-End. Gespeicherte Prozeduren reichen von einfachen SELECT-Anweisung bis hin zu komplexen anderen Programmen. Hier ein Beispiel:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Wenn Sie eine gespeicherte Prozedur in Access verwenden, gibt sie normalerweise ein Ergebnis an ein Formular oder einen Bericht zurück. Sie kann jedoch andere Aktionen ausführen, die keine Ergebnisse zurückgeben, wie z.B. DDL- oder DML-Anweisungen. Wenn Sie eine Pass-Through-Abfrage verwenden, stellen Sie sicher, dass Sie die Eigenschaft Liefert Datensätze entsprechend festlegen.
Weitere Informationen finden Sie unter Gespeicherte Prozeduren.
Allgemeine Tabellenausdrücke
Allgemeine Tabellenausdrücke (Common Table Expressions, CTE) ähneln einer temporären Tabelle, die ein benanntes Resultset generiert. Sie existieren nur für die Dauer der Ausführung einer einzelnen Abfrage oder DML-Anweisung. Ein allgemeiner Tabellenausdruck wird in die gleiche Codezeile wie die SELECT- oder DML-Anweisung, die ihn verwendet, geschrieben, während das Erstellen und Verwenden einer temporären Tabelle oder Sicht in der Regel in zwei Schritten erfolgt. Hier ein Beispiel:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
Ein allgemeiner Tabellenausdruck bietet mehrere Vorteile, z.B. folgende:
-
Da allgemeiner Tabellenausdrücke kurzlebig sind, brauchen Sie sie nicht als permanente Datenbankobjekte wie Sichten zu erstellen.
-
Sie können in einer Abfrage oder DML-Anweisung mehrmals auf den gleichen allgemeinen Tabellenausdruck verweisen, wodurch der Code leichter zu verwalten ist.
-
Sie können Abfragen verwenden, die auf einen allgemeinen Tabellenausdruck verweisen, um einen Cursor zu definieren.
Weitere Informationen finden Sie unter WITH common_table_expression.
Benutzerdefinierte Funktionen
Eine benutzerdefinierte Funktion kann Abfragen und Berechnungen durchführen und entweder skalare Werte oder Datenresultsets zurückgeben. Sie sind wie Funktionen in Programmiersprachen, die Parameter akzeptieren, eine Aktion ausführen, z. b. eine komplexe Berechnung, und das Ergebnis der Aktion als Wert zurückzugeben. Hier ein Beispiel:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Für benutzerdefinierte Funktionen gelten bestimmte Einschränkungen. So können sie beispielsweise bestimmte nicht deterministische Systemfunktionen nicht verwenden, keine DML- oder DDL-Anweisungen und keine dynamischen SQL-Abfragen ausführen.
Weitere Informationen finden Sie unter Benutzerdefinierte Funktionen.
Hinzufügen von Schlüsseln und Indizes
Unabhängig davon, welches Datenbanksystem Sie verwenden, gehen Schlüssel und Indizes Hand in Hand.
Schlüssel
In SQL Server müssen Sie Primärschlüssel für jede Tabelle und Fremdschlüssel für jede verknüpfte Tabelle erstellen. Das SQL Server-Feature, das dem AutoWert-Datentyp von Access entspricht, ist die IDENTITY-Eigenschaft, mit der Sie Schlüsselwerte erstellen können. Wenn Sie diese Eigenschaft auf eine numerische Spalte anwenden, wird diese schreibgeschützt und vom Datenbanksystem gepflegt. Wenn Sie einen Datensatz in eine Tabelle einfügen, die eine IDENTITY-Spalte enthält, erhöht das System den Wert für die IDENTITY-Spalte automatisch um 1 und beginnend bei 1, aber Sie können diese Werte mit Argumenten steuern.
Weitere Informationen finden Sie unter CREATE TABLE, IDENTITY (Eigenschaft).
Indizes
Wie immer ist die Auswahl der Indizes ein Balanceakt zwischen Abfragegeschwindigkeit und Aktualisierungskosten. In Access wird ein Indextyp verwendet, in SQL Server hingegen gibt es zwölf. Glücklicherweise können Sie mit dem Abfrageoptimierer den effektivsten Index auswählen. In Azure SQL können Sie die automatische Indexverwaltung verwenden, ein Feature der automatischen Optimierung, die Ihnen das Hinzufügen oder Entfernen von Indizes empfiehlt. Im Gegensatz zu Access müssen Sie in SQL Server eigene Indizes für Fremdschlüssel erstellen. Sie können auch Indizes für eine indizierte Sicht erstellen, um die Abfrageleistung zu verbessern. Der Nachteil einer indizierten Sicht ist eine erhöhte Auslastung beim Ändern der Daten in Basistabellen der Sicht, da die Sicht ebenfalls aktualisiert werden muss. Weitere Informationen finden Sie unter Leitfaden zur Architektur und zum Design von SQL Server-Indizes und Indizes.
Ausführen von Transaktionen
Das Ausführen eines Onlinetransaktionsprozesses (OLTP) bei Verwendung von Access ist schwierig, in SQL Server hingegen relativ einfach. Eine Transaktion ist eine einzelne Arbeitseinheit, die alle Datenänderungen bei Erfolg festschreibt, die Änderungen bei Misserfolg jedoch zurücksetzt. Eine Transaktion muss vier Eigenschaften aufweisen, die häufig als AKID bezeichnet werden:
-
Atomarität Eine Transaktion muss eine unteilbare Arbeitseinheit sein, deren Datenänderungen entweder komplett oder gar nicht ausgeführt werden.
-
Konsistenz Nach Abschluss muss eine Transaktion alle Daten in einem konsistenten Zustand hinterlassen. Dies bedeutet, dass alle Datenintegritätsregeln angewendet werden.
-
Isolation Von parallelen Transaktionen vorgenommene Änderungen werden von der aktuellen Transaktion isoliert.
-
Dauerhaftigkeit Nach Abschluss einer Transaktion sind Änderungen dauerhaft und bleiben auch bei einem Systemausfall bestehen.
Sie verwenden eine Transaktion, um die Datenintegrität zu gewähren, z.B. bei einer Geldautomatenauszahlung oder bei der automatischen Einzahlung eines Gehaltsschecks. Sie können explizite, implizite oder Stapeltransaktionen ausführen. Hier sind zwei TSQL-Beispiele:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Weitere Informationen finden Sie unter Transaktionen.
Verwenden von Einschränkungen und Triggern
Alle Datenbanken bieten Möglichkeiten zur Wahrung der Datenintegrität.
Einschränkungen
In Access erzwingen Sie die referenzielle Integrität in einer Tabellenbeziehung durch Fremdschlüssel-Primärschlüssel-Paare, Aktualisierungs-und Löschweitergaben sowie Gültigkeitsregeln. Weitere Informationen finden Sie unter Leitfaden für Tabellenbeziehungen und Einschränken der Dateneingabe mithilfe von Gültigkeitsregeln.
In SQL Server verwenden Sie UNIQUE- und CHECK-Einschränkungen, d.h. Datenbankobjekte, die die Datenintegrität in SQL Server-Tabellen erzwingen. Um zu überprüfen, ob ein Wert in einer anderen Tabelle gültig ist, verwenden Sie eine Fremdschlüsseleinschränkung. Um zu überprüfen, ob ein Wert in einer Spalte innerhalb eines bestimmten Bereiches liegt, verwenden Sie eine CHECK-Einschränkung. Diese Objekte sind Ihre erste Verteidigungslinie und wurden für einen effizienten Betrieb entwickelt. Weitere Informationen finden Sie unter UNIQUE- und CHECK-Einschränkungen.
Trigger
Access verfügt nicht über Datenbanktrigger. In SQL Server können Sie Trigger verwenden, um komplexe Datenintegritätsregeln durchzusetzen und diese Geschäftslogik auf dem Server auszuführen. Ein Datenbanktrigger ist eine gespeicherte Prozedur, die ausgeführt wird, wenn bestimmte Aktionen innerhalb einer Datenbank auftreten. Der Trigger ist ein Ereignis, wie das Hinzufügen eines Datensatzes zu einer Tabelle oder das Löschen eines Datensatzes aus einer Tabelle, das ausgelöst wird und dann die gespeicherte Prozedur ausführt. Eine Access-Datenbank kann zwar die referenzielle Integrität sicherstellen, wenn ein Benutzer versucht, Daten zu aktualisieren oder zu löschen, SQL Server verfügt jedoch über einen ausgeklügelten Satz von Triggern. Sie können z.B. einen Trigger programmieren, um Datensätze in einem Massenvorgang zu löschen und dabei die Datenintegrität zu gewährleisten. Sie können sogar Trigger zu Tabellen und Sichten hinzufügen.
Weitere Informationen finden Sie unter DML-Trigger, DDL-Trigger und Designing a T-SQL trigger (Entwerfen eines T-SQL-Triggers).
Verwenden von berechneten Spalten
In Access erstellen Sie eine berechnete Spalte, indem Sie sie zu einer Abfrage hinzufügen und einen Ausdruck erstellen, wie z.B.:
Extended Price: [Quantity] * [Unit Price]
In SQL Server handelt es sich bei dem Feature berechnete Spalte um eine virtuelle Spalte, die nicht physisch in der Tabelle gespeichert ist, es sei denn, die Spalte ist mit PERMANENT gekennzeichnet. Berechnete Spalten verwenden Daten aus anderen Spalten in einem Ausdruck. Um eine berechnete Spalte zu erstellen, fügen Sie sie einer Tabelle hinzu. Beispiel:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Weitere Informationen finden Sie unter Festlegen berechneter Spalten in einer Tabelle.
Setzen von Zeitstempeln für Daten
Manchmal fügen Sie ein Tabellenfeld hinzu, um beim Erstellen eines Datensatzes einen Zeitstempel aufzuzeichnen, sodass Sie den Dateneintrag protokollieren können. In Access können Sie einfach eine Datumsspalte mit dem Standardwert =Now() erstellen. Um ein Datum oder eine Uhrzeit in SQL Server aufzuzeichnen, verwenden Sie den Datentyp datetime2 mit dem Standardwert SYSDATETIME().
Hinweis Verwechseln Sie ROWVERSION nicht mit dem Hinzufügen eines Zeitstempels zu Ihren Daten. Das Schlüsselwort "Zeitstempel" ist ein Synonym für ROWVERSION in SQL Server, aber dort sollten Sie das Schlüsselwort ROWVERSION verwenden. In SQL Server ist ROWVERSION ein Datentyp, der automatisch generierte, eindeutige Binärzahlen innerhalb einer Datenbank verfügbar macht, und im Allgemeinen als Mechanismus für die Versionsverwaltung von Tabellenzeilen verwendet wird. Der ROWVERSION-Datentyp ist jedoch nur ein inkrementeller numerischer Wert, der weder das Datum noch die Uhrzeit speichert und nicht für das Zeitstempeln einer Zeile ausgelegt ist.
Weitere Informationen finden Sie unter ROWVERSION. Weitere Informationen zum Verwenden von ROWVERSION zum Minimieren von Datensatzkonflikten finden Sie unter Migrieren einer Access-Datenbank zu SQL Server.
Verwalten großer Objekte
In Access verwalten Sie unstrukturierte Daten, wie Dateien, Fotos und Bilder, mit dem Datentyp Anlage. In der SQL Server-Terminologie werden unstrukturierte Daten als BLOB (Binary Large Object) bezeichnet, und es gibt mehrere Möglichkeiten, mit ihnen zu arbeiten:
FILESTREAM Verwendet den Datentyp "varbinary(max)", um die unstrukturierten Daten im Dateisystem und nicht in der Datenbank zu speichern. Weitere Informationen finden Sie unter Zugreifen auf FILESTREAM-Daten mit Transact-SQL.
FileTable Speichert BLOBs in speziellen Tabellen, die als FileTables bezeichnet werden, und bietet Kompatibilität mit Windows-Anwendungen, als wären sie im Dateisystem gespeichert, ohne dass Änderungen an Ihren Clientanwendungen vorgenommen werden. FileTable setzt die Verwendung von FILESTREAM voraus. Weitere Informationen finden Sie unter FileTables.
Remote BLOB Store (RBS) Speichert Binary Large Objects (BLOBs) in speziellen Speicherlösungen und nicht direkt auf dem Server. Dadurch werden Speicherplatz und Hardwareressourcen eingespart. Weitere Informationen finden Sie unter Binary Large Object (BLOB)-Daten.
Arbeiten mit hierarchischen Daten
Relationale Datenbanken wie Access sind zwar sehr flexibel, aber das Arbeiten mit hierarchischen Beziehungen ist eine Ausnahme und erfordert häufig komplexe SQL-Anweisungen oder Code. Beispiele für hierarchische Daten sind: Organisationsstrukturen, Dateisysteme, Taxonomien von Sprachbegriffen und Diagramme von Verknüpfungen zwischen Webseiten. SQL Server verfügt über einen integrierten Datentyp hierarchyid und einen Satz hierarchischer Funktionen, um hierarchische Daten ganz einfach zu speichern, abzufragen und zu verwalten.
Weitere Informationen finden Sie unter hierarchische Daten und Lernprogramm: Verwenden des hierarchyid-Datentyps.
Bearbeiten von JSON-Text
JSON (JavaScript Object Notation) ist ein Webdienst, der für die Übertragung von Daten als Attribut-Wert-Paare in einer asynchronen Browser-Server Kommunikation lesbaren Text verwendet. Beispiel:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Access bietet keine integrierten Methoden für die Verwaltung von JSON-Daten, aber in SQL Server können sie JSON-Daten problemlos speichern, indizieren, abfragen und extrahieren. Sie können JSON-Text in eine Tabelle konvertieren und speichern oder Daten als JSON-Text formatieren. Sie können z.B. Abfrageergebnisse für eine Web-App als JSON formatieren oder JSON-Datenstrukturen zu Zeilen und Spalten hinzufügen.
Hinweis JSON wird in VBA nicht unterstützt. Alternativ können Sie in VBA XML mithilfe der MSXML-Bibliothek verwenden.
Weitere Informationen finden Sie unter JSON-Daten in SQL Server.
Ressourcen
Jetzt ist ein guter Zeitpunkt, um mehr über SQL Server und Transact SQL (TSQL) zu erfahren. Wie Sie bereits gesehen haben, gibt es viele Features wie Access, aber auch Funktionen, die in Access einfach nicht verfügbar sind. Wenn Sie die nächste Ebene erkunden möchten, finden Sie hier einige Lernressourcen:
|
Ressource |
Beschreibung |
|
Videobasierter Kurs |
|
|
Tutorials zu SQL Server 2017 |
|
|
Praxislernmodule für Azure |
|
|
Experte werden |
|
|
Die Hauptstartseite |
|
|
Hilfeinformationen |
|
|
Hilfeinformationen |
|
|
Eine Übersicht über die Cloud |
|
|
Eine visuelle Zusammenfassung der neuen Features |
|
|
Eine Zusammenfassung der Features nach Version |
|
|
SQL Server Express 2017 herunterladen |
|
|
Beispieldatenbanken herunterladen |









