
Hvis du har brug for at udvikle komplekse statistiske eller tekniske analyser, kan du spare tid og trin ved hjælp af Analysis ToolPak. Du angiver data og parametre for hver analyse, og værktøjet bruger de relevante statistiske eller tekniske makrofunktioner til at beregne og vise resultaterne i en outputtabel. Nogle værktøjer genererer diagrammer ud over outputtabeller.
Dataanalysefunktionerne kan kun anvendes på ét regneark ad gangen. Når du udfører en dataanalyse på grupperede regneark, vises resultaterne i det første regneark, og tomme, formaterede tabeller vises i de resterende regneark. Hvis du vil udføre en dataanalyse på de resterende regneark, skal du genberegne med analyseværktøjet for hvert regneark.
Analysis ToolPak indeholder de værktøjer, der er beskrevet i de følgende afsnit. Hvis du vil bruge disse værktøjer, skal du klikke på Dataanalyse i gruppen Analyse under fanen Data. Hvis kommandoen Dataanalyse ikke er tilgængelig, skal du indlæse tilføjelsesprogrammet Analysis ToolPak.
-
Klik på fanen Filer, klik på Indstillinger, og klik derefter på kategorien Tilføjelsesprogrammer.
-
Markér Excel-tilføjelsesprogrammer i feltet Administrer, og klik derefter på Søg.
Hvis du bruger Excel til Mac, skal du i filmenuen gå til Værktøjer > Excel-tilføjelsesprogrammer.
-
Markér afkrydsningsfeltet Analysis ToolPak i dialogboksen Tilføjelsesprogrammer, og klik derefter på OK.
-
Hvis Analysis ToolPak ikke vises i feltet Tilgængelige tilføjelsesprogrammer, skal du klikke på Gennemse for at finde det.
-
Hvis der vises en meddelelse om, at Analysis ToolPak ikke aktuelt er installeret på din computer, skal du klikke på Ja for at installere det.
-
Bemærk!: Hvis du vil medtage VBA-funktioner (Visual Basic for Application) til Analysis ToolPak, kan du indlæse VBA-tilføjelsesprogrammet til Analysis ToolPak på samme måde, som du indlæser Analysis ToolPak. Markér afkrydsningsfeltet Analysis ToolPak - VBA i feltet Tilgængelige tilføjelsesprogrammer.
Analyseværktøjerne Anova foretager forskellige typer af variansanalyser. Hvilket værktøj, du skal anvende i den konkrete sammenhæng, afhænger af, hvor mange faktorer og hvor mange stikprøver du har fra de populationer, du vil teste.
Anova: Enkeltfaktor
Dette værktøj udfører en simpel analyse af variansen på data for to eller flere stikprøver. Analysen giver en test af hypotesen om, at hver prøve udtrækkes fra den samme underliggende sandsynlighedsfordeling i forhold til den alternative hypotese om, at underliggende sandsynlighedsfordelinger ikke er ens for alle stikprøver. Hvis der kun er to eksempler, kan du bruge regnearksfunktionen T.TEST. Med mere end to prøver er der ingen praktisk generalisering af T.TEST, og Single Factor Anova-modellen kan i stedet kaldes.
Anova: To-faktor med gentagelse
Dette analyseværktøj er nyttigt, når data kan klassificeres i to forskellige dimensioner. I et forsøg på at måle planternes højde kan planterne f.eks. få forskellige gødningsmærker (f.eks. A, B, C) og kan også opbevares ved forskellige temperaturer (f.eks. lav, høj). For hver af de seks mulige par af {gødning, temperatur} har vi et lige antal observationer af plantehøjde. Ved hjælp af dette Anova-værktøj kan vi teste:
-
Om plantehøjderne for de forskellige gødningsmærker udtrækkes fra den samme underliggende population. Temperatur ignoreres ved denne analyse.
-
Om plantehøjderne for de forskellige temperaturniveauer udtrækkes fra den samme underliggende population. Gødningsmærke ignoreres ved denne analyse.
Uanset om der er redegjort for effekterne af de forskelle mellem gødningsmærker, der blev fundet i det første punkt i opstillingen, og de forskelle i temperaturer, der blev fundet i det andet punkt i opstillingen, udtrækkes de seks stikprøver, der repræsenterer alle par af {gødning, temperatur}-værdier, fra den samme population. Den alternative hypotese er, at der er effekter, der forårsages af specifikke {gødning, temperatur}-par over og under forskellene, der er baseret på gødning alene eller på temperatur alene.

Anova: To-faktor uden gentagelse
Dette analyseværktøj er nyttigt, når data klassificeres på to forskellige dimensioner som i Two-Factor tilfælde med replikering. Men for dette værktøj antages det, at der kun er en enkelt observation for hvert par (f.eks. hvert {gødning, temperatur}-par i det foregående eksempel).
Regnearksfunktionerne KORRELATION og PEARSON beregner begge korrelationskoefficienten mellem to målingsvariabler, når målinger på hver variabel observeres for hver af N-emnerne. (En eventuel manglende observation for et emne forårsager, at emnet ignoreres i analysen). Analyseværktøjet Korrelation er særligt nyttigt, når der er mere end to målingsvariabler for hvert af N-emnerne. Det indeholder en outputtabel, en korrelationsmatrix, der viser værdien af KORRELATION (eller PEARSON) anvendt på hvert muligt par målingsvariabler.
Korrelationskoefficienten er ligesom kovariansen et mål for, i hvilket omfang to målingsvariabler "varierer sammen". I modsætning til kovariansen skaleres korrelationskoefficienten, så dens værdi er uafhængig af de enheder, hvori de to målingsvariabler udtrykkes. Hvis de to målingsvariabler f.eks. er vægt og højde, er værdien af korrelationskoefficienten uændret, hvis vægt konverteres fra pund til kg. Værdien af en korrelationskoefficient skal være mellem -1 og +1 inklusive.
Du kan bruge analyseværktøjet Korrelation til at undersøge hvert par målingsvariabler for at bestemme, om de to målingsvariabler har tendens til at bevæge sig sammen – dvs. om store værdier af den ene variabel har tendens til at være forbundet med store værdier af den anden (positiv korrelation), om små værdier af den ene variabel har tendens til at være forbundet med store værdier af den anden (negativ korrelation), eller om værdier af begge variabler har tendens til ikke at være relateret (korrelation nær 0 (nul)).
Værktøjerne Korrelation og Kovarians kan begge bruges med samme indstilling, når du har N forskellige målingsvariabler, der er observeret på et sæt individer. Værktøjerne Korrelation og Kovarians giver hver en outputtabel, en matrix, der viser henholdsvis korrelationskoefficienten eller kovariansen mellem hvert par målingsvariabler. Forskellen er, at korrelationskoefficienter skaleres til at ligge mellem -1 og +1 inklusive. De kovarianser, der svarer til hinanden, skaleres ikke. Både korrelationskoefficienten og kovariansen er mål for, hvor meget to variabler "varierer sammen".
Værktøjet Kovarians beregner værdien af regnearksfunktionen KOVARIANS. P for hvert par målingsvariabler. (Direkte brug af KOVARIANS. P i stedet for kovariansværktøjet er et rimeligt alternativ, når der kun er to målingsvariabler, dvs. N=2.) Indtastningen på diagonalen af værktøjet Kovarianss outputtabel i række i, kolonne i er kovariansen for den i'te målingsvariabel med sig selv. Dette er blot populationens varians for den pågældende variabel, som beregnet af regnearksfunktionen VARIANS.P.
Du kan bruge værktøjet Kovarians til at undersøge hvert par målingsvariabler for at bestemme, om de to målingsvariabler har tendens til at bevæge sig sammen – dvs., om store værdier af den ene variabel har tendens til at være forbundet med store værdier af den anden (positiv kovarians), om små værdier af den ene variabel har tendens til at være forbundet med store værdier af den anden (negativ kovarians), eller om værdier af begge variabler har tendens til ikke at være relateret (kovarians nær 0 (nul)).
Analyseværktøjet Beskrivende statistik genererer en rapport, der indeholder statistik med én variabel for dataene i inputområdet samt oplysninger om dataenes overordnede tendens og afvigelse.
Analyseværktøjet Eksponentiel udglatning forudsiger en værdi, der er baseret på prognosen fra den forrige periode afstemt efter fejl i denne forrige prognose. Værktøjet benytter en udglatningskonstant, a, hvis størrelse bestemmer, hvor meget prognosen ændres som følge af fejl i den forrige prognose.
Bemærk!: Værdier mellem 0,2 og 0,3 er egnede som udglatningskonstanter. Værdierne angiver, at den aktuelle prognose skal korrigeres for fejl med 20 % til 30 % i forhold til den foregående prognose. Større konstanter giver et hurtigere svar, men kan give fejlagtige prognoser. Mindre konstanter kan resultere i, at prognoseværdierne ændres længe efter, at de faktiske værdier ændres.
Analyseværktøjet F-test: Dobbelt-stikprøve for varians udfører en F-test med dobbelt stikprøve for at sammenligne varianser i to populationer.
Du kan f.eks. bruge værktøjet F-test på eksempler på tidspunkter i et svømmemøde for hvert af to teams. Værktøjet giver resultatet af en test af null-hypotesen om, at disse to stikprøver kommer fra fordelinger med ens varianser i forhold til alternativet, at varianserne ikke er ens i de underliggende fordelinger.
Værktøjet beregner værdien f for en F-stikprøvefunktion (eller et F-forhold). En værdi af f, der er tæt på 1, er et tegn på, at de underliggende populationsvarianser er lig med hinanden. Hvis f < 1, giver "P(F <= f) en-sidet" i outputtabellen sandsynligheden for at observere en værdi af F-stikprøvefunktionen, der er mindre end f, når populationsvarianser er lig hinanden, og "F kritisk en-sidet" giver den kritiske værdi mindre end 1 for det valgte signifikansniveau Alpha. Hvis f > 1, giver "P(F <= f) en-sidet" sandsynligheden for at observere en værdi af F-stikprøvefunktionen, der er større end f, når populationsvarianser er lig med hinanden, og "F kritisk en-sidet" giver den kritiske værdi større en 1 for Alpha.
Analyseværktøjet Fourier-analyse løser problemer i lineære systemer og analyserer periodiske data ved hjælp af Fast Fourier Transform-metoden (FFT) til at transformere data. Med dette værktøj understøttes også inverse transformationer, hvor det omvendte af de transformerede data returnerer de oprindelige data.
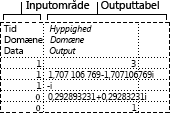
Analyseværktøjet Histogram beregner individuelle og kumulative hyppigheder for et celleområde, der består af data og dataklasser. Værktøjet genererer data for antallet af forekomster af en værdi i et datasæt.
I en klasse på 20 studerende kan du f.eks. bestemme fordelingen af karakterer i kategorier for bogstavkarakterer. En histogramtabel viser grænserne for bogstavkarakter og antallet af resultater mellem den laveste grænse og den aktuelle grænse. Den mest almindelige score er datatilstanden.
Analyseværktøjet Bevægeligt gennemsnit beregner værdier i prognoseperioden på grundlag af variablens gennemsnitsværdi i et bestemt antal foregående perioder. Et bevægeligt gennemsnit frembringer tendensoplysninger, som ikke kan aflæses ud fra et simpelt gennemsnit af alle historiske data. Brug dette værktøj til at oprette prognoser for salg, lagerbeholdning eller tendenser. Hver enkelt prognoseværdi er baseret på nedenstående formel.
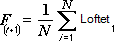
hvor:
-
N er antallet af foregående perioder, der skal indgå i det bevægelige gennemsnit
-
A j er den faktiske værdi på tidspunktet j
-
F j er prognoseværdien på tidspunktet j
Analyseværktøjet Generering af tilfældige tal udfylder et område med uafhængige tilfældige tal, der er trukket fra en af flere fordelinger. Du kan karakterisere emnerne i en population med en sandsynlighedsfordeling. Du kan f.eks. bruge en normalfordeling til at karakterisere populationen af enkeltpersoners højder, eller du kan bruge en Bernoulli-fordeling af to mulige resultater til at karakterisere populationen af mønt-flip-resultater.
Analyseværktøjet Plads og Fraktil opretter en tabel, der indeholder ordenstal og procentplads for hver værdi i et datasæt. Du kan analysere den relative placering af værdier i et datasæt. Dette værktøj bruger regnearksfunktionerne PLADS. EQ ogPROCENTPLADS. INC. Hvis du vil tage højde for bundne værdier, skal du bruge PLADS . Funktionen LIGE , som behandler bundne værdier som havende samme rang, eller som bruger PLADS.Funktionen GNS, som returnerer den gennemsnitlige rang for de bundne værdier.
Analyseværktøjet Regression udfører en lineær regressionsanalyse ved hjælp af metoden "mindste kvadrater" for at tilpasse en linje gennem et sæt observationer. Du kan analysere, hvordan en enkelt afhængig variabel påvirkes af værdierne for en eller flere uafhængige variabler. Du kan f.eks. analysere, hvordan en atlets ydeevne påvirkes af faktorer som alder, højde og vægt. Du kan fordele andele i målingen af ydeevnen for hver af disse tre faktorer baseret på et sæt ydelsesdata og derefter bruge resultaterne til at forudsige ydeevnen for en ny, ikke-afprøvet atlet.
Værktøjet Regression bruger regnearksfunktionen LINREGR.
Analyseværktøjet Stikprøver opretter en stikprøve fra en population ved at behandle inputområdet som en population. Når populationen er for stor til at blive behandlet eller diagrammet, kan du bruge en repræsentativ stikprøve. Du kan også oprette en stikprøve, der kun indeholder værdierne fra en bestemt del af en cyklus, hvis du mener, at inputdataene er periodiske. Hvis inputområdet f.eks. indeholder kvartalsvise salgstal, placerer stikprøvetagning med en periodisk hastighed på fire værdierne fra samme kvartal i outputområdet.
Analyseværktøjet T-test med to stikprøver tester for lighed af den populationsmiddelværdi, der ligger under hver stikprøve. De tre værktøjer anvender forskellige forudsætninger: at populationsvarianserne er lig med hinanden, at populationsvarianserne ikke er lig med hinanden, og at de to stikprøver repræsenterer før og efter behandlingsobservationer for de samme emner.
For alle tre værktøjer nedenfor gælder det, at en t-statistik-værdi, t, beregnes og vises som "t Stat" i outputtabellerne. Afhængig af dataene kan denne værdi, t, være negativ eller ikke-negativ. Under forudsætning af ens underliggende populationsmiddelværdier gælder det, at hvis t < 0, giver "P(T <= t) en-sidet" sandsynligheden for, at der observeres en værdi af t-statistik, der er mere negativ end t. Hvis t >=0, giver "P(T <= t) en-sidet" sandsynligheden for, at der observeres en værdi af t-statistik, der er mere positiv end t. "t kritisk en-sidet" giver skæringsværdien, så sandsynligheden for at observere en værdi af t-statistik, der er større end eller lig med "t kritisk en-sidet", er Alpha.
"P(T <= t) to-sidet" giver sandsynligheden for, at der observeres en værdi af t-statistik, der er større i absolut værdi end t. "P kritisk to-sidet" giver skæringsværdien, så sandsynligheden for en observeret t-statistik, der er større i absolut værdi end "P kritisk to-sidet", er Alpha.
T-test: Parvis dobbelt stikprøve for middelværdi
Du kan bruge en parret test, når der er en naturlig parring af observationer i prøverne, f.eks. når en prøvegruppe testes to gange – før og efter et eksperiment. Dette analyseværktøj og dets formel udfører en parret toprøvet Student's t-test for at afgøre, om observationer, der er taget før en behandling, og observationer, der er taget efter en behandling, sandsynligvis er kommet fra fordelinger med lige populationsmidler. Denne t-testform forudsætter ikke, at varianserne for begge populationer er ens.
Bemærk!: Blandt de resultater, der genereres af dette værktøj, er puljevarians, der er en akkumuleret måling af dataspredningen omkring middelværdien, og som opnås ved at bruge følgende formel:
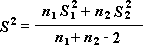
T-test: To stikprøver med ens varians
Dette analyseværktøj udfører en t-test med to stikprøver. Denne t-testformular forudsætter, at de to datasæt stammer fra fordelinger med de samme varianser. Det kaldes en homoscedastic t-test. Du kan bruge denne t-test til at afgøre, om de to stikprøver sandsynligvis kommer fra fordelinger med ens populationsmidler.
T-test: To stikprøver med forskellig varians
Dette analyseværktøj udfører en t-test med to stikprøver. Denne t-testformular forudsætter, at de to datasæt stammer fra fordelinger med ulige varianser. Det kaldes en heteroscedastic t-Test. Som det er tilfældet med de foregående tilfælde med lig med varianser, kan du bruge denne t-test til at afgøre, om de to stikprøver sandsynligvis kommer fra fordelinger med ens populationsmidler. Brug denne test, når der er særskilte emner i de to stikprøver. Brug den parrede test, der er beskrevet i det følgende eksempel, når der er et enkelt sæt af emner, og de to prøver repræsenterer målinger for hvert emne før og efter en behandling.
Den følgende formel bruges til at bestemme den statistiske værdi t.
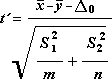
Følgende formel bruges til at beregne frihedsgraderne, f. Da resultatet af beregningen normalt ikke er et heltal, afrundes værdien af fg til det nærmeste heltal for at opnå en kritisk værdi fra t-tabellen. Excel-regnearksfunktionen T.TEST bruger den beregnede fg-værdi uden afrunding, fordi det er muligt at beregne en værdi for T.TEST med en ikke-integer fg. På grund af disse forskellige tilgange til bestemmelse af frihedsgraderne, resultaterne af T.TEST , og dette t-testværktøj adskiller sig i tilfældet Ulige varianser.
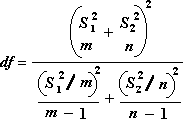
Z-testen: Analyseværktøjet To stikprøver for middelværdi udfører en z-test med to stikprøver for midler med kendte varianser. Dette værktøj bruges til at teste null-hypotesen om, at der ikke er nogen forskel mellem to populationsmidler mod enten ensidede eller tosidede alternative hypoteser. Hvis der ikke kendes varianser, er regnearksfunktionen Z.TEST skal bruges i stedet.
Når du bruger z-testværktøjet, skal du være forsigtig med at forstå outputtet. "P(Z <= z) en-sidet" er virkelig P(Z >= ABS(z)), sandsynligheden for en z-værdi længere fra 0 i samme retning som den observerede z-værdi, når der ikke er nogen forskel mellem middelværdien for populationen. "P(Z <= z) tosidet" er i virkeligheden P(Z >= ABS(z) eller Z <= -ABS(z)), sandsynligheden for en z-værdi længere fra 0 i begge retninger end den observerede z-værdi, når der ikke er nogen forskel mellem populationens middelværdi. Det tosidede resultat er blot det ensidede resultat ganget med 2. Værktøjet z-test kan også bruges i tilfælde, hvor null-hypotesen er, at der er en bestemt værdi, der ikke er nul, for forskellen mellem de to middelværdier i populationen. Du kan f.eks. bruge denne test til at bestemme forskellene mellem ydeevnen for to bilmodeller.
Har du brug for mere hjælp?
Du kan altid spørge en ekspert i Excel Tech Community eller få support i community'er.
Se også
Opret et histogram i Excel 2016
Opret et Pareto-diagram i Excel 2016
Indlæse Analysis ToolPak i Excel
ENGINEERING-funktioner (reference)
Sådan undgår du ødelagte formler









