
De fleste brugere opdager, at den reelle styrke findes i aggregering eller beregning af et resultat på en eller anden måde, når først de lærer at bruge Power Pivot. Hvis dine data indeholder en kolonne med numeriske værdier, kan du nemt aggregere dem ved at markere dem i en pivottabel eller en Power View-feltliste. Da de er numeriske, vil de automatisk blive lagt sammen, talt, gennemsnit vil blive beregnet, afhængigt af den type aggregering du vælger. Dette kaldes en implicit måling. Implicitte målinger er gode til hurtig og nem aggregering, men de har begrænsninger, og disse begrænsninger kan næsten altid løses med eksplicitte målinger og beregnede kolonner.
Lad os først se på et eksempel, hvor vi bruger en beregnet kolonne til at tilføje en ny tekstværdi i hver række i en tabel, vi kalder Produkt. Hver række i tabellen Produkt indeholder alle mulige oplysninger om alle de produkter, vi sælger. Vi har kolonner til produktnavn, farve, størrelse, forhandler pris osv. Vi har en anden relateret tabel med navnet Produktkategori, der indeholder kolonnen Produktkategorinavn. Det, vi ønsker, er, at hvert produkt i tabellen Produkt indeholder produktkategorinavnet fra tabellen Produktkategori. I tabellen Produkt kan vi oprette en beregnet kolonne med navnet Produktkategori sådan her:
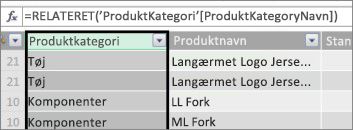
Vores nye Produktkategori-formel bruger RELATED DAX-funktionen til at hente værdier fra kolonnen Produktkategorinavn i den relaterede tabel Produktkategori og angiver derefter disse værdier for hvert produkt (hver række) i tabellen Produkt.
Dette er et godt eksempel på, hvordan vi kan bruge en beregnet kolonne til at tilføje en fast værdi i hver række, som vi kan bruge senere i området RÆKKER, KOLONNER eller FILTRE af pivottabellen eller i en Power View-rapport.
Lad os lave et andet eksempel, hvor vi vil beregne en overskudsmargen for vores produktkategorier. Dette er et almindeligt scenarie, også i en masse selvstudier. Vi har tabellen Salg i vores datamodel, der indeholder transaktionsdata, og der findes en relation mellem tabellen Salg og tabellen Produktkategori. I tabellen Salg har vi en kolonne med salgsbeløb og en anden kolonne med omkostninger.
Vi kan oprette en beregnet kolonne, der beregner et overskudsbeløb for hver række ved at trække værdierne i kolonnen Forbrug fra værdierne i kolonnen Salgsbeløb således:
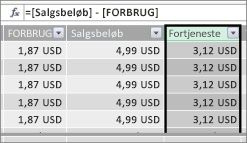
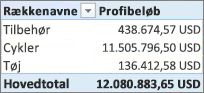
Vi kan nu oprette en pivottabel og trække feltet Produktkategori til KOLONNER og vores nye felt Overskud til området VÆRDIER (en kolonne i en tabel i PowerPivot er et felt i pivottabelfeltlisten). Resultatet er en implicit måling kaldet Sum af overskud. Det er et aggregeret beløb af værdier fra kolonnen Overskud for hver af de forskellige produktkategorier. Vores resultat ser sådan ud:
I dette tilfælde giver Overskud kun mening som et felt i VÆRDIER. Hvis vi placerede Overskud i området KOLONNER, ville vores pivottabel se således ud:
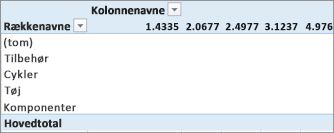
Feltet Overskud giver ikke nogen nyttige oplysninger, når det er placeret i områderne KOLONNER, RÆKKER eller FILTRE. Det giver kun mening som en aggregeret værdi i området VÆRDIER.
Det, vi har gjort, er at oprette en kolonne med navnet Overskud, der beregner en overskudsmargen for hver række i tabellen Salg. Vi tilføjede derefter Overskud til området VÆRDIER i vores pivottabel, hvilket automatisk oprettede en implicit måling, hvor et resultat beregnes for hver af produktkategorierne. Hvis du tænker, at vi i virkeligheden beregnede overskuddet for vores produktkategorier to gange, har du helt ret. Først beregnede vi et overskud for hver række i tabellen Salg, og derefter føjede vi Overskud til området VÆRDIER, hvor det blev aggregeret for hver af produktkategorierne. Hvis du også tænker, at det egentlig ikke var nødvendigt at oprette den beregnede kolonne Overskud, har du også ret. Men hvordan beregner vi så vores overskud uden at oprette en beregnet overskudskolonne?
Det ville være bedre at beregne Overskud som en eksplicit måling.
Vi forlader nu vores beregnede kolonne Overskud i tabellen Salg og Produktkategori i KOLONNER og Overskud i VÆRDIER i pivottabellen et øjeblik for at sammenligne vores resultater.
I beregningsområdet af tabellen Salg skal vi nu oprette en måling, der hedder Samlet overskud (for at undgå navnekonflikter). I sidste ende giver det det samme resultat, som det vi gjorde før, men uden en beregnet kolonne Overskud.
Først vælger vi i tabellen Salg kolonnen Salgsbeløb, og derefter klikker vi på AutoSum for at oprette en eksplicit måling, Sum af salgsbeløb. Husk, at en eksplicit måling er noget, vi opretter i beregningsområdet af en tabel i Power Pivot. Vi gør det samme for kolonnen Forbrug. Vi vil omdøbe disse SamletSalgsbeløb og SamletForbrug for at gøre det lettere at identificere dem.
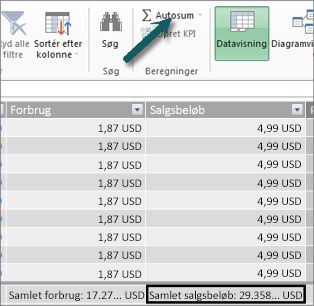
Herefter opretter vi en anden måling med denne formel:
Samlet overskud:=[ Salgsbeløb i alt]-[Samlet forbrug]
Bemærk!: Vi kan også skrive vores formel som Samlet overskud:=SUM([Salgsbeløb]) - SUM([Forbrug]), men ved at oprette separate målinger for Salgsbeløb og Forbrug, kan vi også bruge dem i vores pivottabel, og vi kan bruge dem som argumenter i alle mulige andre måleformler.
Efter at have ændret formatet for vores nye måling Samlet overskud til valuta kan vi føje den til vores pivottabel.
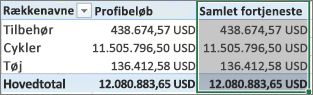
Du kan se, at vores nye måling Samlet fortjeneste returnerer det samme resultat som oprettelse af en beregnet kolonne Overskud og placerer det herefter i VÆRDIER. Forskellen er, at vores måling Samlet fortjeneste er langt mere effektiv og gør vores datamodel renere og mere enkel, fordi vi beregner på det tidspunkt og kun for de felter, vi vælger til vores pivottabel. Vi behøver i virkeligheden ikke den beregnede kolonne Overskud.
Hvorfor er denne sidste del vigtig? Beregnede kolonner føjer data til datamodellen, og data kræver en masse hukommelse. Hvis vi opdaterer datamodellen, skal der også bruges ressourcer til at genberegne alle værdierne i kolonnen Overskud. Det er slet ikke nødvendigt at bruge ressourcer på denne måde, da vi ønsker at beregne vores overskud, når vi vælger de felter, vi ønsker Overskud for i pivottabellen, som produktkategorier, område eller efter dato.
Lad os se på et andet eksempel. Et, hvor en beregnet kolonne skaber resultater, der ved første øjekast ser rigtige ud, men ...
I dette eksempel ønsker vi at beregne salgsbeløb som en procentdel af det samlede salg. Vi opretter en beregnet kolonne kaldet % af salg i tabellen Salg, således:
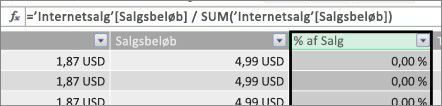
Vores formel siger: For hver række i tabellen Salg skal beløbet i kolonnen Salgsbeløb divideres med den samlede SUM af alle beløb i kolonnen Salgsbeløb.
Hvis vi opretter en pivottabel og føjer Produktkategori til KOLONNER og vælger vores nye kolonne % af salg til at sætte ind i VÆRDIER, får vi en samlet sum med % af salg for hver af vores produktkategorier.
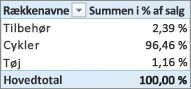
Ok. Det ser indtil videre fint ud. Men lad os tilføje et udsnitsværktøj. Vi tilføjer Kalenderår og vælger derefter et år. I dette tilfælde vælger vi 2007. Her er det, vi får.
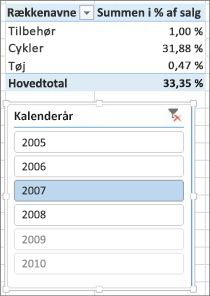
Ved første øjekast ser dette muligvis stadig korrekt ud. Men vores procenter bør i virkeligheden give 100 % i alt, fordi vi gerne vil kende procentdelen af det samlede salg for hver af vores produktkategorier for 2007. Så hvad gik der galt?
Vores % af kolonnen Salg beregnede en procent for hver række, der er værdien i kolonnen Salgsbeløb divideret med summen af alle værdier i kolonnen Salgsbeløb. Værdier i en beregnet kolonne er faste. De er et uforanderligt resultat for hver række i tabellen. Da vi føjede % af salg til vores pivottabel, blev det aggregeret som en sum af alle værdier i kolonnen Salgsbeløb. Summen af alle værdier i kolonnen % af salg vil altid være 100 %.
Tip!: Sørg for at læse Kontekst i DAX-formler. Det giver en god forståelse af rækkeniveaukontekst og filterkontekst, hvilket er det, vi beskriver her.
Vi kan slette vores beregnede kolonne % af salg, da den ikke kan hjælpe os. I stedet opretter vi en måling, der på korrekt vis beregner vores procent af det samlede salg, uanset eventuelle anvendte filtre eller udsnit.
Kan du huske målingen Samlet salgsbeløb, vi oprettede tidligere, den, der ganske enkelt opsummerer kolonnen Salgsbeløb? Vi brugte det som et argument i vores måling Samlet overskud, og vi vil bruge det igen som argument i vores nye beregnede felt.
Tip!: Oprettelse af eksplicitte målinger som Samlet salgbeløb og Samlet forbrug er ikke kun nyttige i en pivottabel eller rapport, de er også nyttige som argumenter i andre målinger, når du har brug for resultatet som argument. Det gør dine formler mere effektive og nemmere at læse. Dette er god praksis for datamodellering.
Vi opretter en ny måling med følgende formel:
% af samlet salg:=([Samlet salgsbeløb]) / CALCULATE([Samlet salgsbeløb], ALLSELECTED())
Denne formel angiver: Divider resultatet fra Samlet salgsbeløb med den samlede sum fra Salgsbeløb uden andre kolonne- eller rækkefiltre end dem, der er defineret i pivottabellen.
Tip!: Sørg for at læse om funktionerne CALCULATEog ALLSELECTED i DAX-referencen.
Hvis vi nu tilføjer vores nye % af samlet salg til pivottabellen, får vi:
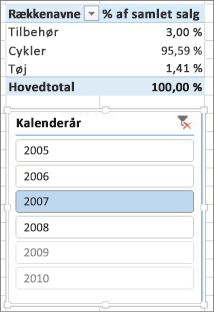
Det ser bedre ud. Nu beregnes vores % af samlet salg for hver produktkategori som en procentdel af samlet salg for året 2007. Hvis vi vælger et andet år eller mere end ét år i udsnitsværktøjet Kalenderår, får vi nye procentdele for vores produktkategorier, men vores hovedtotal er stadig 100 %. Vi kan også tilføje andre udsnitsværktøjer og filtre. Vores måling % af samlet salg vil altid give en procentdel af samlet salg uanset eventuelt anvendte udsnit eller filtre. Med målinger beregnes resultatet altid efter den kontekst, der bestemmes af felterne i KOLONNER og RÆKKER, og af eventuelt anvendte filtre eller udsnit. Dette er styrken ved målinger.
Her er nogle retningslinjer, der kan hjælpe dig, når du beslutter, hvorvidt en beregnet kolonne eller en måling passer til et bestemt beregningsbehov:
Brug beregnede kolonner
-
Hvis du vil have dine nye data vist i RÆKKER, KOLONNER eller i FILTRE i en pivottabel eller på en AKSE, en FORKLARING eller et FELT EFTER i en Power View-visualisering, skal du bruge en beregnet kolonne. Beregnede kolonner kan bruges som et felt i et område på samme måde som almindelige kolonner med data, og hvis de er numeriske, kan de også aggregeres i VÆRDIER.
-
Hvis du ønsker, at dine nye data skal være en fast værdi for rækken. Du har f.eks. en datotabel med en kolonne med datoer, og du vil have en anden kolonne, der kun indeholder månedens nummer. Du kan oprette en beregnet kolonne, der kun beregner månedsnummeret ud fra datoerne i kolonnen Dato. F.eks. =MÅNED('Dato'[Dato]).
-
Hvis du vil føje en tekstværdi for hver række til en tabel, skal du bruge en beregnet kolonne. Felter med tekstværdier kan aldrig aggregeres i VÆRDIER. Eksempelvis giver =FORMAT('Dato'[Dato],"mmmm") os månedens navn for hver dato i kolonnen Dato i tabellen Dato.
Brug målinger
-
Hvis resultatet af beregningen altid vil være afhængigt af de andre felter, du vælger i en pivottabel.
-
Hvis du vil udføre mere komplekse beregninger, som f.eks. at beregne en optælling, der er baseret på et filter, eller beregne et år for år eller varians, skal du bruge et beregnet felt.
-
Hvis du vil holde projektmappens størrelse på et minimum og maksimere dens ydeevne, kan du oprette lige så mange af dine beregninger som målinger som muligt. I mange tilfælde kan alle dine beregninger være målinger, hvilket markant reducerer projektmappens størrelse og gør opdateringen hurtigere.
Husk, at der ikke er noget galt med at oprette beregnede kolonner, som vi gjorde med vores kolonne Overskud, og derefter aggregere dem i en pivottabel eller rapport. Det er faktisk en virkelig god og nem måde at få mere at vide om og oprette dine egne beregninger. Efterhånden som din forståelse af disse to særdeles effektive funktioner i Power Pivot vokser, vil du formentlig lave den mest effektive og nøjagtige datamodel, du overhovedet kan. Forhåbentlig hjælper det, du har lært her. Der er også nogle andre virkelig gode ressourcer derude, hvor du kan finde hjælp. Her er nogle få: Kontekst i DAX-formler, Aggregeringer i Power Pivot og DAX-ressourcecenter. Selv om det er lidt mere avanceret og beregnet til regnskabs- og finansmedarbejdere, er eksemplet Databasemodellering og analyse af overskud og tab med Microsoft Power Pivot i Excel fyldt med gode eksempler på datamodellering og formler.









