
Po migraci dat z Accessu na SQL Server máte k dispozici databázi typu klient-server, která může být místním nebo hybridním cloudovým řešením Azure. Ať tak či onak, je nyní Access prezentační vrstvou a SQL Server je datovou vrstvou. Nyní je dobré si promyslet aspekty řešení, především výkon dotazů, zabezpečení a provozní kontinuitu, abyste mohli řešení databáze zlepšovat a škálovat.
SQL Server a dokumentace Azure se můžou zdát při prvním setkání uživatele aplikace Access těžké. Proto je potřebný průvodce, díky kterému budete mít přehled o tom, co je pro vás důležité. Až prohlídku dokončíte, budete připraveni prozkoumat výhody v databázové technologii do větší hloubky.
V tomto článku:
|
Správa databází |
Dotazy a související |
Datové typy |
Různé |
Nepřerušený provoz disku
Vaše řešení v Accessu budete chtít udržovat, aby běželo s minimálním přerušením, ale vaše možnosti s back-endovou databází aplikace Access jsou omezené. Zálohování databáze Accessu je nezbytné pro ochranu dat, ale vyžaduje, aby uživatelé přešli do režimu offline. Také se můžou vyskytnout neplánované odstávky způsobené upgrady údržby hardware nebo software, výpadky sítě nebo elektřiny, selháním hardwaru, porušením zabezpečení nebo dokonce i kybernetickými útoky. Abyste snížili odstávky a dopad na vaši práci, můžete zálohovat databázi SQL Serveru, zatímco jí používáte. SQL Server navíc nabízí i strategii pro vysokou dostupnost (HA) a zotavení po havárii (DR). Tyto dvě kombinované technologie se označují jako HADR. Další informace najdete v článcích Nepřerušený provoz a obnovení databáze a Nepřerušený provoz disku s SQL Serverem (e-kniha)..
Zálohování při používání
SQL Server používá online zálohovací proces, který se může spustit při běhu databáze. Můžete udělat úplnou zálohu, částečnou zálohu nebo zálohu souborů. Operace zálohování zkopíruje data a transakční protokoly, aby bylo zajištěno dokončení operace obnovení. Obzvláště v místním řešení si uvědomte rozdíly mezi možnostmi jednoduchého a úplného obnovení a jejich vliv na růst transakčního protokolu. Další informace najdete v článku Modely obnovení.
Většina operací zálohování se provádí hned, s výjimkou operací správy souborů a zmenšení databáze. Pokud se naopak pokusíte vytvořit nebo odstranit soubor databáze zatímco probíhá operace zálohování, operace se selže. Další informace najdete v článku Přehled zálohování.
HADR
Nejběžnějšími technikami k dosažení vysoké dostupnosti a nepřerušeného provozu jsou zrcadlení a clustering. SQL Server integruje zrcadlení a clustering s instancemi clusteru s podporami převzetí služeb při selhání Always On a skupinami dostupnosti Always On.
Zrcadlení je řešení kontinuity na úrovni databáze podporující téměř okamžité převzetí služeb při selhání tím, že udržuje pohotovostní režim databáze, úplnou kopii nebo zrcadlovou kopii aktivní databáze na samostatném hardwaru. Může fungovat v synchronním režimu (s vysokou úrovní zabezpečení), kdy se příchozí transakce potvrdí na všech serverech najednou, nebo v asynchronním režimu (s vysokým výkonem), kdy se příchozí transakce potvrdí do aktivní databáze a později v některém předem určeném bodě zkopíruje na zrcadlovou kopii. Zrcadlení je řešením na úrovni databáze a funguje jenom v databázích, které používají úplný model obnovení.
Clustering je řešení na úrovni serveru, které kombinuje servery do jediného úložiště dat, které se jeví uživateli jako jedna instance. Uživatelé se k této instanci připojují a nikdy nemusí vědět, který server v instanci je momentálně aktivní. Pokud některý ze serverů selže nebo je potřeba ho z důvodu údržby převést do režimu offline, z pohledu uživatele se nic nezmění. Každý server v clusteru je monitorován správcem clusteru pomocí prezenčního signálu, který detekuje, když se aktivní server v clusteru přepne do režimu offline, a pokusí se plynule přepnout na další server v clusteru, i když se v čase přepnutí vyskytuje proměnlivé časové zpoždění.
Další informace najdete v článku Instance clusteru s podporou převzetí služeb při selhání Always On a Skupiny dostupnosti Always On: řešení vysoké dostupnosti a zotavení po havárii.
SQL Server Security
I když můžete svoji databázi Accessu chránit pomocí centra zabezpečení a pomocí šifrování databáze, SQL Server má mnohem pokročilejší funkce zabezpečení. Podívejme se na tři možnosti, které pro uživatele Accessu vyniknou. Další informace najdete v článku Zabezpečení SQL Serveru.
Ověřování databáze
Na SQL Serveru jsou čtyři způsoby ověřování databáze, každý z nich můžete zadat v připojovacím řetězci ODBC. Další informace najdete v článku Propojení nebo import dat z databáze Azure SQL Serveru. Každá z těchto metod má svoje výhody.
Integrované ověřování systému Windows Používejte přihlašovací údaje k systému Windows pro ověření uživatele, role zabezpečení a omezení funkcí a dat uživatelům. Můžete využít přihlašovací údaje domény a jednoduše spravovat uživatelská práva ve svojí aplikaci. Volitelně můžete zadat Hlavní názvy služby (SPN). Další informace najdete v článku Volba režimu ověřování.
Ověřování SQL Serveru Uživatelé se musí připojit pomocí přihlašovacích údajů, které jsou nastavené v databázi, tak, že při prvním přístupu k databázi v relaci zadají přihlašovací ID a heslo. Další informace najdete v článku Volba režimu ověřování.
Integrované ověřování Azure Active Directory Připojení k databázi Azure SQL Serveru pomocí Azure Active Directory. Po nakonfigurování ověřování pomocí služby Azure Active Directory není požadováno další přihlašovací jméno ani heslo. Další informace najdete v tématu Připojení k databázi SQL s ověřováním pomocí služby Azure Active Directory.
Ověřování hesel službou Active Directory Připojení pomocí přihlašovacích údajů nastavených v Azure Active Directory zadáním přihlašovacího jména a hesla. Další informace najdete v tématu Připojení k databázi SQL s ověřováním pomocí služby Azure Active Directory.
Tip Pokud chcete přijímat upozornění na neobvyklou databázovou aktivitu, která naznačuje potenciální ohrožení zabezpečení databáze Azure SQL Serveru, používejte detekci hrozeb. Další informace najdete v článku Detekce hrozeb SQL Database.
Zabezpečení aplikací
SQL Server má dvě funkce zabezpečení na úrovni aplikace, které můžete s Accessem využít.
Dynamické maskování dat Skryjte citlivé informace jejich maskováním před uživateli bez oprávnění. Můžete třeba částečně nebo úplně maskovat čísla sociálního pojištění.
 Částečná maska dat |
 Úplná maska dat |
Masku dat můžete definovat několika způsoby a můžete je použít u různých datových typů. Maskování dat je řízeno zásadami na úrovni tabulek a sloupců pro definovanou sadu uživatelů a používá se k dotazování v reálném čase. Další informace najdete v článku Dynamické maskování dat.
Zabezpečení na úrovni řádků Přístup k určitým řádkům databáze s citlivými informacemi můžete řídit na základě uživatelských vlastností pomocí zabezpečení na úrovni řádků. Databázový systém uplatní tato omezení přístupu a tím zajistí spolehlivější a robustnější zabezpečení systému.

Existují dva typy predikátů zabezpečení:
-
Predikát filtru filtruje řádky z dotazu. Filtr je transparentní a koncový uživatel si není vědom žádného filtrování.
-
Predikát bloku znemožňuje neoprávněnou akci a vyvolá výjimku, pokud tato akce nemohla být provedena.
Další informace najdete v článku Zabezpečení na úrovni řádků.
Ochrana dat pomocí šifrování
Zabezpečte data v době nečinnosti, při přenosu a zatímco jsou používána bez ovlivnění výkonu databáze. Další informace najdete v článku Ochrana dat pomocí šifrování.
Šifrování v době nečinnosti Pokud chcete zabezpečit osobní data proti mediálním útokům na fyzickou vrstvu úložiště v režimu offline, používejte šifrování v době nečinnosti, kterému se říká také transparentní šifrování dat (TDE). Znamená to, že vaše data jsou chráněna, pokud jsou fyzická média ukradena nebo nesprávně odstraněna. TDE v reálném čase provádí šifrování a dešifrování databází, záloh a transakčních protokolů bez toho, že by se vyžadovala jakákoliv změna vašich aplikací.
Šifrování při přenosu Pokud chcete chránit data před sledováním a útoky „man-in-the-middle“, můžete šifrovat data přenášená v síti. SQL Server podporuje protokol TLS (Transport Layer Security) 1.2 pro vysoce zabezpečené komunikace. Protokol TDS (Tabular Data Stream) se taky používá k ochraně komunikace v nedůvěryhodných sítích.
Šifrování při používání na straně klienta Pokud chcete chránit osobní údaje v době jejich použití, je pro vás vhodná funkce Always Encrypted. Osobní údaje šifruje a dešifruje ovladač na klientském počítači bez odhalení šifrovacích klíčů databázovému stroji. Výsledkem je, že šifrovaná data budou viditelná jenom lidem, kteří zodpovídají za správu těchto dat, a ne jiným uživatelům s vysokou úrovní oprávnění, kteří by přístup mít neměli. V závislosti na typu vybraného šifrování může funkce Always Encrypted omezovat některé funkce databáze, jako je hledání, seskupení a indexování šifrovaných sloupců.
Zpracování obav z ochrany osobních údajů
Obavy z ochrany osobních údajů jsou tak široce rozšířeny, že Evropská unie definovala právní předpisy prostřednictvím obecného nařízení o ochraně osobních údajů (GDPR). Naštěstí má back-end SQL Serveru vhodné předpoklady, aby reagoval na tyto požadavky. Zamyslete se nad implementací GDPR ve třech krocích.

Krok 1: Vyhodnocení a řízení rizik dodržování předpisů
GDPR vyžaduje, abyste identifikovali a zaznamenali osobní údaje, které máte v tabulkách a souborech. Tyto informace můžou být cokoliv od jména, fotografie, e-mailové adresy, informací o bance, příspěvků na webech sociálních sítí, lékařských údajů až po IP adresy.
Nový nástroj,Zjišťování a klasifikace dat SQL, který je integrovaný do SQL Server Management Studia, vám pomůže najít, klasifikovat, popsat a nahlásit citlivá data, a to tak, že použije dva atributy metadat na sloupce:
-
Popisky Definují citlivost dat.
-
Typy informací Poskytují další úroveň podrobností o typech dat, která jsou ve sloupci uložena.
Dalším mechanismem zjišťování, který můžete použít, je fulltextové vyhledávání, které obsahuje použití predikátů CONTAINS a FREETEXT a funkce vracející hodnotu sady řádků, jako je CONTAINSTABLE a FREETEXTTABLE pro použití s příkazem SELECT. Když používáte fulltextové vyhledávání, můžete v tabulkách hledat slova, kombinace slov nebo varianty slov, například synonyma nebo inflexní formy. Další informace najdete v článku Fulltextové vyhledávání.
Krok 2: Ochrana osobních údajů
GDPR vyžaduje zabezpečení osobních údajů a omezení přístupu k nim. Kromě standardních kroků, které jste povedli ke správě přístupu ke svojí síti a prostředkům, jako je třeba nastavení brány firewall, můžete použít funkce zabezpečení SQL Serveru, které vám pomůžou řídit přístup k datům:
-
Ověřování SQL Serveru ke správě identity uživatelů a ochranu před neoprávněným přístupem.
-
Zabezpečení na úrovni řádků k omezení přístupu k řádkům v tabulce na základě vztahu mezi uživatelem a těmito daty.
-
Dynamické maskování dat k omezení expozice osobních údajů pomocí maskování před uživateli bez oprávnění.
-
Šifrování k zaručení ochrany osobních údajů při přenášení a ukládání a ochrany před ohrožením bezpečnosti, včetně ohrožení na straně serveru.
Další informace najdete v tématu SQL Server Security.
Krok 3: Efektivní odpovědi na požadavky
GDPR vyžaduje, abyste spravovali záznamy o zpracování osobních dat a po vyžádání je poskytli kontrolním úřadům. Pokud se vyskytnou problémy, včetně náhodného uvolnění dat, ovládací prvky ochrany vám umožní rychle reagovat. Data musí být rychle dostupná, když je nahlášení potřebné. Například GDPR vyžaduje, aby bylo porušení osobních údajů nahlášeno kontrolním orgánům „nejpozději do 72 hodin poté, co se o tom dozvíte“.
SQL Server 2017 vám pomáhá s úkolem nahlášení v několika ohledech:
-
Audit SQL Serveru vám pomáhá zajistit, že existují trvalé záznamy o přístupech a aktivitách zpracování databází. Provádí podrobný audit, který sleduje databázové aktivity, což vám pomůže porozumět a identifikovat potenciální ohrožení, podezření na zneužití nebo narušení zabezpečení. Snadno můžete na datech provádět forenzní činnosti.
-
Dočasné tabulky SQL Serveru jsou uživatelské tabulky systémové verze navržené tak, aby zachovaly úplnou historii změn dat. Můžete je použít k snadnému vykazování a analýze v průběhu času.
-
Posouzení ohrožení zabezpečení SQL vám pomáhá zjišťovat problémy se zabezpečením a oprávněními. V případě zjištění problému můžete také přejít k podrobnostem v hlášeních prohledávání databáze a najít akce pro řešení.
Další informace najdete v článcích Vytvoření platformy důvěry (e-kniha) a Cesta k dodržování nařízení GDPR.
Vytvoření snímků databáze
Snímek databáze je statické zobrazení databáze SQL Serveru jen pro čtení v určitém čase. I když můžete zkopírovat soubor databáze Accessu, abyste mohli efektivně vytvořit snímek databáze, Access nemá vestavěnou metodologii jako SQL Server. Pomocí snímku databáze můžete vytvářet sestavy založené na datech v čase vytvoření snímku databáze. Snímek databáze můžete taky použít k zachování historických dat, například jeden pro každé účetní období, které používáte k zavedení sestav na konci období. Doporučujeme následující doporučené postupy:
-
Pojmenování snímku Každý snímek databáze vyžaduje jedinečný název databáze. K názvu pro snazší identifikaci přidejte účel a časový rámec. Pokud chcete například vytvořit snímek databáze AdventureWorks třikrát denně v 6-hodinových intervalech mezi 6:00 a 18:00 na základě 24-hodinového času, pojmenujte je AdventureWorks_snímek_0600, AdventureWorks_snímek_1200 a AdventureWorks_snímek_1800.
-
Omezení počtu snímků Každý snímek databáze bude uložený, dokud nebude výslovně odstraněn. Vzhledem k tomu, že bude každý snímek dál růst, můžete chtít ušetřit místo na disku odstraněním staršího snímku po vytvoření nového snímku. Když třeba vytváříte denní sestavy, ponechte si snímek databáze po dobu 24 hodin a potom ho můžete odstranit a nahradit novým.
-
Připojení ke správnému snímku Abyste mohli použít snímek databáze, musí front-end Accessu vědět správné umístění. Když nahradíte existující snímek novým, budete muset přesměrovat Access na nový snímek. Abyste měli jistotu, že se připojujete ke správnému snímku databáze, přidejte logiku k front-endu Accessu.
Tady je postup vytvoření snímku databáze:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Další informace najdete v článku Snímky databáze (SQL Server).
Řízení souběžnosti
Když se hodně lidí snaží změnit data v databázi najednou, je potřeba mít systém řízení, aby změny provedené jedním člověkem neovlivnily změny jiné osoby. Jmenuje se to řízení souběžnosti a existují dvě základní strategie uzamykání, pesimistická a optimistická. Uzamknutí může uživatelům zabránit v úpravách dat způsobem, který má vliv na ostatní uživatele. Uzamknutí taky pomáhá zajistit integritu databáze, zvlášť u dotazů, které by jinak mohly vést k neočekávaným výsledkům. Ve způsobu implementace těchto strategií řízení souběžnosti v Accessu a na SQL Serveru jsou důležité rozdíly.
V Accessu je výchozí strategií zamykání optimistická a udělí vlastnictví zámku prvnímu člověku, který se pokusí o zápis do záznamu. Druhému uživateli, který se snaží o zápis do stejného záznamu ve stejnou dobu, zobrazí Access dialogové okno Konflikt při zápisu. Konflikt můžete vyřešit tak, že druhý uživatel záznam uloží, zkopíruje do schránky nebo změny zruší.
Pomocí vlastnosti RecordLocks můžete taky změnit strategii řízení souběžnosti. Tato vlastnost má vliv na formuláře, sestavy a dotazy a má tři nastavení:
-
Bez uzamčení Ve formuláři se uživatelé můžou pokusit upravit stejný záznam současně, ale může se zobrazit dialogové okno Konflikt při zápisu. U sestavy nejsou záznamy během zobrazování náhledu nebo tisku sestavy uzamčeny. U dotazu nejsou záznamy během spouštění dotazu uzamčeny. Toto je způsob implementace optimistického uzamčení v Accessu.
-
Všechny záznamy V podkladové tabulce nebo dotazu se uzamknou všechny záznamy, když se formulář otevře ve formulářovém zobrazení nebo v zobrazení Datový list, během zobrazování náhledu nebo tisku sestavy nebo během spouštění dotazu. Uživatelé si během uzamčení můžou záznamy číst.
-
Upravovaný záznam Pro formuláře a dotazy se stránka záznamů uzamkne, jakmile jakýkoliv uživatel začne upravovat libovolné pole v záznamu a zůstane uzamčená, dokud uživatel nepřejde na jiný záznam. Záznam tedy může upravit jenom jeden uživatel současně. Toto je způsob implementace pesimistického uzamčení v Accessu.
Další informace najdete v článku Dialogové okno Konflikt při zápisu a Vlastnost RecordLocks.
Na SQL Serveru funguje řízení souběžnosti tímto způsobem:
-
Pesimistické Když uživatel provede akci, která způsobí použití zámku, ostatní uživatelé nemůžou provádět akce, které by mohly být v konfliktu s uzamčením, dokud je majitel neuvolní. Toto řízení souběžnosti je převážně používané v prostředích, kde je vysoká kolize dat.
-
Optimistické Během optimistického řízení souběžnosti uživatelé nezamykají data, když je čtou. Když uživatel aktualizuje data, systém zkontroluje, jestli data po jeho přečtení nezměnil jiný uživatel. Pokud data aktualizoval jiný uživatel, vyvolá se chyba. Uživatel, který přijal chybu, obvykle vrátí transakci zpět a začne znovu. Toto řízení souběžnosti je převážně používané v prostředích, kde je nízká kolize dat.
Výběrem několika úrovní izolace transakce, které určují úroveň ochrany transakce před úpravami provedenými jinými transakcemi pomocí příkazu SET TRANSACTION, můžete určit typ řízení souběžnosti:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Úroveň izolace |
Popis |
|
Čtení nepotvrzeno |
Transakce jsou izolované jen natolik, aby se zajistilo, že nejsou čtena fyzicky poškozená data. |
|
Čtení potvrzeno |
Transakce mohou číst data, která byla předtím přečtena jinou transakcí bez čekání na dokončení první transakce. |
|
Čtení s možností opakování |
Zámky čtení a zápisu se přidávají k vybraným datům až do konce transakce. Může dojít k fiktivnímu čtení. |
|
Snímek |
Používá verzi řádků k zajištění konzistence čtení na úrovni transakce. |
|
Serializovatelné |
Transakce jsou od sebe zcela oddělené. |
Další informace najdete v článku Příručka zamykáním transakcí a verzováním řádků.
Zvýšení výkonu dotazů
Až budete mít fungující předávací dotaz Accessu, využijte sofistikovaný způsob, jak může SQL Server pracovat efektivněji.
Na rozdíl od databáze aplikace Access poskytuje SQL Server paralelní dotazování k optimalizaci provádění dotazů a operacím s indexem pro počítače s více než jedním procesorem (CPU). Protože SQL Server může provést operaci dotazování nebo indexování paralelně pomocí několika pracovních vláken systému, je možné operaci dokončit rychle a efektivně.
Dotazy jsou důležitou součástí, která zlepšuje celkový výkon databázového řešení. Neplatné dotazy běží neomezeně dlouho, jejich časový limit vyprší a spotřebovávají zdroje, jako jsou procesor, paměť a šířka pásma sítě. Tím se znemožňuje dostupnost kritických obchodních informací. I jeden neplatný dotaz může způsobit vážné problémy s výkonem databáze.
Další informace najdete v článku Rychlejší dotazování s SQL Serverem (e-kniha).
Optimalizace dotazů
Několik nástrojů spolupracuje na tom, aby vám pomohly analyzovat výkon dotazů a vylepšit je: Optimalizátor dotazů, plány provedení a úložiště dotazů.
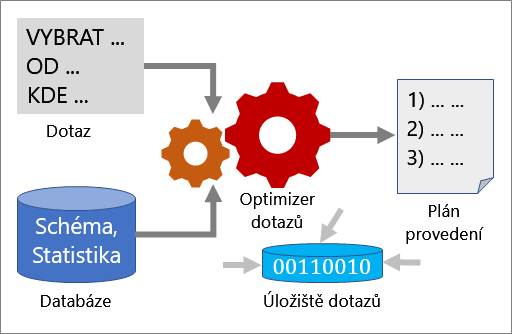
Optimalizátor dotazů
Optimalizátor dotazů je jednou z nejdůležitějších součástí SQL Serveru. Pomocí Optimalizátoru dotazů můžete analyzovat dotaz a určit nejefektivnější způsob, jak získat přístup k požadovaným datům. Vstup pro optimalizátor dotazů se skládá z dotazu, schématu databáze (definice tabulek a indexů) a statistik databáze. Výstupem Optimalizátoru dotazů je plán provedení.
Další informace najdete v článku Optimalizátor dotazů SQL Serveru.
Plán provedení
Plán provedení je definice, která řadí zdrojové tabulky pro přístup a metody používané k extrahování dat z každé tabulky. Optimalizace je proces výběru jednoho z mnoha možných plánů provedení. Každý z možných plánů provedení má přiřazené náklady na množství používaných výpočetních zdrojů a optimalizátor dotazů zvolí ten s nejnižšími předpokládanými náklady.
SQL Server se musí také dynamicky přizpůsobovat měnícím se podmínkám v databázi. Regrese v plánech provedení dotazů můžou mít výrazný dopad na výkon. Některé změny v databázi můžou způsobit, že je plán provedení buď neefektivní nebo neplatný, a to v závislosti na novém stavu databáze. SQL Server rozpozná změny, které zruší platnost plánu provedení, a označí plán jako neplatný.
Nový plán se pak musí znovu zkompilovat pro příští připojení, které dotaz spouští. K podmínkám, které ruší platnost, patří:
-
Změny provedené v tabulce nebo zobrazení, na které odkazuje dotaz (ALTER TABLE a ALTER VIEW).
-
Změny indexů používaných v plánu provedení.
-
Aktualizace statistik používaných v plánu provedení, které jsou vygenerované buď explicitně z příkazu, jako je například UPDATE STATISTICS, nebo automaticky.
Další informace najdete v článku Plány provedení.
Úložiště dotazů
Úložiště dotazů poskytuje přehled o volbě plánu provedení a výkonu. Zjednodušuje řešení potíží s výkonem tím, že vám pomůže rychle najít rozdíly ve výkonu, které jsou způsobeny změnou plánu provedení. V úložišti dotazů jsou shromážděna data telemetrie, například historie dotazů, plány, statistika běhu a statistika čekání. Implementace úložiště dotazů pomocí příkazu ALTER DATABASE:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Další informace najdete v článku Monitorování výkonu pomocí úložiště dotazů.
Automatická oprava plánů
Nejjednodušší způsob, jak zlepšit výkon dotazů, je pravděpodobně díky automatické opravě plánů, což je funkce, která je k dispozici v Azure SQL Database. Jednoduše ji zapnete a necháte ji pracovat. Průběžně provádí monitorování a analýzu plánů provedení, detekuje problematické plány provedení a automaticky opravuje problémy s výkonem. Automatická oprava plánu na pozadí používá strategii ve čtyřech krocích: zjistit, přizpůsobit, ověřit a opakovat.
Další informace najdete v článku Automatické ladění.
Adaptivní zpracování dotazů
Rychlejší dotazy také můžete získat tak, že upgradujete na SQL Server 2017, který obsahuje novou funkci s názvem adaptivní zpracování dotazů. SQL Server upravuje volby plánů dotazů podle vlastností za běhu.
Odhad mohutnosti se blíží počtu řádků zpracovaných u jednotlivých kroků v plánu provedení. Nepřesné odhady mohou mít za následek pomalé odpovědi na dotazy, nepotřebné využití prostředků (paměť, procesor a V/V) a omezenou propustnost a souběžnost. K přizpůsobení vlastností aplikačního zatížení se používají tři techniky:
-
Zpětná vazba udělení paměti v režimu dávek Špatné odhady mohutnosti mohou způsobit, že dotazy budou „odloženy na disk“ nebo zaberou příliš mnoho paměti. SQL Server 2017 upraví nároky na udělení paměti na základě zpětné vazby provedení, odstraní odložení na disku a zlepšuje souběžnost opakujících se dotazů.
-
Adaptivní spojení v režimu dávek Adaptivní spojení za běhu dynamicky vybírá lepší interní typ spojení (spojení nested loop, spojení merge, spojení hash) na základě skutečných vstupních řádků. V důsledku toho může plán při provádění dynamicky přejít na lepší strategii spojení.
-
Prokládané provádění Funkce vracející tabulku s více příkazy byly tradičně při zpracování dotazů považovány za černou skřínku. SQL Server 2017 může odhadnout počty řádků pro zlepšení podřízených operací.
Zátěž můžete automaticky nastavit pro adaptivní zpracování dotazů tak, že povolíte úroveň kompatibility 140 pro tuto databázi:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Další informace najdete v článku Inteligentní zpracování dotazů v databázích SQL.
Způsoby dotazování
Na SQL Serveru existuje několik způsobů dotazování a každý z nich má své výhody. Abyste zvolili ten správný pro vaše řešení v Accessu, zjistěte o nich více informací. Nejlepší způsob, jak vytvořit dotazy TSQL, je jejich interaktivní úprava a testování pomocí editoru Transact-SQL SQL Server Management Studio (SSMS), který má funkci IntelliSense, která vám pomůže vybrat správná klíčová slova a zkontrolovat chyby syntaxe.
Zobrazení
Na SQL Serveru je zobrazení jako virtuální tabulka, ve které data zobrazení pocházejí z jedné nebo více tabulek nebo jiných zobrazení. Zobrazení se ale v dotazech odkazují stejně jako tabulky. Zobrazení mohou skrýt složitost dotazů a chránit data tím, že omezí sadu řádků a sloupců. Tady je příklad jednoduchého zobrazení:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Abyste dosáhli optimálního výkonu a upravili výsledky zobrazení, vytvořte indexované zobrazení, které se v databázi zachová jako tabulka, vyhradí mu úložiště a může byt dotazováno, jako jakákoliv tabulka. Pokud ho chcete používat v Accessu, můžete na něho odkazovat stejně jako na tabulku. Tady je příklad indexovaného zobrazení:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Existují ale omezení. Data nemůžete aktualizovat, pokud je ovlivněna více než jedna základní tabulka nebo zobrazení obsahuje agregační funkce nebo klauzuli DISTINCT. Pokud SQL Server vrátí chybovou zprávu, že neví, který záznam chcete odstranit, je možné, že budete muset v zobrazení přidat aktivační událost pro odstranění. Není možné použít ani klauzuli ORDER BY tak, jak je to možné v dotazu aplikace Access.
Další informace najdete v článcích Zobrazení a Vytváření indexovaných zobrazení.
Uložené procedury
Uložená procedura je skupina jednoho nebo několika příkazů TSQL, které přijímají vstupní parametry, vrací výstupní parametry a označují úspěch nebo neúspěch pomocí hodnoty stavu. Fungují jako zprostředkující vrstva mezi front-end Accessem a back-end SQL Serverem. Uložené procedury mohou být jednoduché jako příkaz SELECT nebo složité jako ostatní programy. Tady je příklad:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Když v Accessu použijete uloženou proceduru, obvykle vrací sadu výsledků zpět do formuláře nebo sestavy. Může ale provádět i jiné akce, které nevracejí výsledky, například příkazy DDL nebo DML. Když používáte předávací dotaz, ujistěte se, že jste správně nastavili vlastnost Vrací záznamy.
Další informace najdete v článku Uložené procedury.
Běžné výrazy tabulky
Běžné výrazy tabulky (CTE) jsou jako dočasná tabulka, která vygeneruje pojmenovanou sadu výsledků. Existuje jenom pro provedení jediného dotazu nebo příkazu DML. CTE je vytvořený ve stejném řádku kódu jako příkaz SELECT nebo DML, který ho používá, zatímco vytvoření a použití dočasné tabulky nebo zobrazení je obvykle proces se dvěma kroky. Tady je příklad:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
CTE má několik výhod, včetně těchto:
-
Vzhledem k tomu, že jsou výrazy CTE přechodné, nemusíte je vytvářet jako trvalé databázové objekty, jako jsou například zobrazení.
-
V dotazu nebo v příkazu DML můžete odkazovat na stejné CTE více než jednou, čímž se váš kód bude snadněji spravovat.
-
K definování kurzoru můžete použít dotazy, které odkazují na CTE.
Další informace najdete v článku WITH common_table_expression.
Funkce definované uživatelem
Funkce definovaná uživatelem (UDF) může provádět dotazy a výpočty a vracet buď skalární hodnoty nebo datové sady výsledků. Jsou podobné funkcím v programovacích jazycích, které akceptují parametry, provádějí akci, jako je například složitý výpočet, a vrátí výsledek této akce jako hodnotu. Tady je příklad:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Funkce UDF mají určitá omezení. Nemůžou například používat určité nedeterministické systémové funkce, provádět příkazy DML nebo DDL nebo provádět dynamické dotazy SQL.
Další informace najdete v článku Funkce definované uživatelem.
Přidání klíčů a indexů
Bez ohledu na to, jaký databázový systém používáte, jdou klíče a indexy ruku v ruce.
Klíče
Na SQL Serveru se ujistěte, že jste vytvořili primární klíče pro každou tabulku a cizí klíče pro každou související tabulku. Ekvivalentní funkce na SQL Serveru k datovému typu Automatické číslo v Accessu je vlastnost IDENTITY, kterou můžete použít k vytvoření klíčových hodnot. Když tuto vlastnost použijete na libovolný číselný sloupec, bude v databázi jen pro čtení a musí být udržována databázovým systémem. Když vložíte záznam do tabulky, která obsahuje sloupec IDENTITY, systém automaticky zvýší hodnotu sloupce IDENTITY o 1 a začne od 1. Tyto hodnoty ale můžete nastavit pomocí argumentů.
Další informace najdete v článku CREATE TABLE, IDENTITY (vlastnost).
Indexy
Jako vždy je výběr indexů vyvážením mezi rychlostí dotazu a cenou aktualizace. V Accessu máte jeden typ indexu, ale na SQL Serveru jich máte dvanáct. Naštěstí můžete využít optimalizátor dotazů, abyste mohli spolehlivě zvolit nejefektivnější index. V Azure SQL můžete používat automatickou správu indexů, funkci automatického ladění, která vám doporučí přidání nebo odebrání indexů. Na rozdíl od Accessu musíte na SQL Serveru vytvořit vlastní indexy cizích klíčů. Pokud chcete zlepšit výkon dotazů, můžete vytvářet indexy v indexovaných zobrazeních. Když upravíte data v základních tabulkách zobrazení, je zvýšená režie nevýhodou indexovaného zobrazení, protože zobrazení musí být také aktualizováno. Další informace najdete v článcích Příručka architektury a návrhu indexů SQL Serveru a Indexy.
Provádění transakcí
Provádění procesu transakcí online (OLTP) je při použití Accessu obtížné, ale relativně snadné s SQL Serverem. Transakce je samostatná jednotka práce, která potvrdí všechny změny dat, pokud byla úspěšná, ale vrátí je zpět, pokud byla neúspěšná. Transakce musí mít čtyři vlastnosti, které se často označují jako ACID:
-
Nedělitelnost (Atomicity) Transakce musí být atomická (nedělitelná) jednotka práce. Buď jsou provedeny všechny změny dat, nebo není provedena žádná.
-
Konzistence (Consistency) Po dokončení musí transakce ponechat všechna data v konzistentním stavu. To znamená, že se použijí všechna pravidla integrity dat.
-
Izolace (Isolation) Změny prováděné souběžnými transakcemi jsou izolovány od aktuální transakce.
-
Stálost (Durability) Po dokončení transakce jsou změny trvalé i v případě selhání systému.
Transakce se používá k zajištění zaručené integrity dat, jako je například hotovostní výběr z bankomatu nebo automatický vklad výplaty. Můžete provádět explicitní transakce, implicitní transakce nebo transakce oboru dávky. Tady jsou dva příklady TSQL:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Další informace najdete v článku Transakce.
Použití omezení a aktivačních událostí
Všechny databáze mají způsoby pro zachování integrity dat.
Omezení
V Accessu se v relaci mezi tabulkami vynucuje referenční integrita pomocí páru cizí klíč – primární klíč, kaskádových aktualizací a odstranění a pravidel ověřování. Další informace najdete v článcích Příručka k relacím mezi tabulkami a Vytvoření ověřovacího pravidla pro ověření dat v poli.
Na SQL Serveru používáte omezení UNIQUE a CHECK, což jsou databázové objekty, které vynucují integritu dat v tabulkách SQL Serveru. Pokud chcete ověřit, že je hodnota platná v jiné tabulce, použijte omezení cizího klíče. Abyste ověřili, že je hodnota v určitém rozsahu, použijte omezení CHECK. Tyto objekty představují první linii obrany a jsou navržené tak, aby fungovaly efektivně. Další informace najdete v článku Jedinečné omezení a kontrolní omezení.
Aktivační události
Access nemá aktivační události databáze. Na SQL Serveru můžete pomocí aktivačních událostí vynutit pravidla pro složitou integritu dat a spustit tuto obchodní logiku na serveru. Aktivační událost databáze je uložená procedura, která se spouští, když dojde ke konkrétní akci v databázi. Aktivační událost je událost jako přidání záznamu do tabulky nebo jeho odstranění, která se aktivuje a následně provede uloženou proceduru. I když se uživatel snaží při pokusu o aktualizaci nebo odstranění dat zajistit referenční integritu databáze, SQL Server má sofistikované sady aktivačních událostí. Například můžete naprogramovat aktivační událost pro hromadné odstraňování záznamů a zajistit integritu dat. Můžete dokonce přidat aktivační události do tabulek a zobrazení.
Další informace najdete v článcích Aktivační události – DML, Aktivační události – DDL a Návrh aktivační události T-SQL.
Použití vypočítaných sloupců
V Accessu vytvoříte počítaný sloupec tak, že ho přidáte do dotazu a vytvoříte výraz, například:
Extended Price: [Quantity] * [Unit Price]
Na SQL Serveru se ekvivalentní funkce označuje jako vypočítaný sloupec, což je virtuální sloupec, který není fyzicky uložený v tabulce, pokud není tento sloupec označen jako PERSISTED. Podobně jako počítaný sloupec používá vypočítaný sloupec data z jiných sloupců ve výrazu. Pokud chcete vytvořit vypočítaný sloupec, přidejte ho do tabulky. Například:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Další informace najdete v článku Určení vypočítaných sloupců v tabulce.
Časová razítka dat
Někdy můžete přidat pole tabulky pro zaznamenání časového razítka při vytvoření záznamu, abyste mohli zaznamenat zadání dat. V Accessu můžete jednoduše vytvořit sloupec kalendářního data s výchozí hodnotou =Now(). K nahrání data nebo času na SQL Serveru použijte datový typ datetime2 s výchozí hodnotou SYSDATETIME().
Poznámka Nespleťte si rowversion s přidáním timestamp do svých dat. Klíčové slovo timestamp je synonymem pro rowversion na SQL Serveru, ale měli byste použít klíčové slovo rowversion. Na SQL Serveru je rowversion datový typ, který zpřístupňuje automaticky vygenerované jedinečné binární čísla v databázi. Obvykle se používá jako mechanismus pro označení verze řádků tabulky. Datový typ rowversion je ale jenom narůstající číslo, nezachovává datum nebo čas a není určený pro časová razítka v řádku.
Další informace najdete v článku rowversion. Další informace o použití rowversion k minimalizaci konfliktů záznamů najdete v článku Migrace Accessové databáze do SQL Serveru.
Správa velkých objektů
V Accessu můžete spravovat nestrukturovaná data, jako jsou soubory, fotky a obrázky, pomocí datového typu Příloha. V terminologii SQL Serveru se nestrukturovaná data označují jako Binární rozsáhlý objekt (BLOB) a je několik způsobů, jak s nimi pracovat:
FILESTREAM Používá datový typ varbinary(max) k ukládání nestrukturovaných dat v souborovém systému namísto databáze. Další informace najdete v článku Přístup k datům FILESTREAM pomocí jazyka Transact-SQL.
FileTable Ukládá objekty blob do zvláštních tabulek s názvem FileTables a zajišťuje kompatibilitu s aplikacemi pro Windows, jako by byly uložené v systému souborů a neprováděly žádné změny v klientských aplikacích. FileTable vyžaduje použití FILESTREAM. Další informace najdete v článku FileTables.
Vzdálené úložiště objektů BLOB (RBS) Ukládá binární rozsáhlé objekty (BLOB) do řešení úložišť komodit místo přímo na serveru. Tím ušetříte prostor a snížíte hardwarové prostředky. Další informace najdete v článku Data binárních rozsáhlých objektů (BLOB)
Práce s hierarchickými daty
I když jsou relační databáze, jako je třeba Access, velmi flexibilní, je práce s hierarchickými vztahy výjimka a často vyžaduje složité příkazy nebo kód SQL. Příklady hierarchických dat zahrnují: organizační strukturu, systém souborů, taxonomii termínů jazyka a grafy odkazů mezi webovými stránkami. SQL Server obsahuje integrovaný datový typ hierarchyid a sadu hierarchických funkcí pro snadné ukládání, dotazování a správu hierarchických dat.
Další informace najdete v článcích Hierarchická data a Tutoriál: Použití datového typu hierarchyid.
Manipulace s textem JSON
JSON (JavaScript Object Notation) je webová služba, která používá čitelný text pro přenos dat jako dvojic atribut – hodnota v asynchronní komunikaci prohlížeč – server. Například:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Access nemá k dispozici žádné integrované způsoby pro správu dat JSON, ale na SQL Serveru můžete plynule ukládat, indexovat, dotazovat a extrahovat data JSON. Text JSON můžete převést a uložit do tabulky nebo data formátovat jako text JSON. Například můžete chtít naformátovat výsledky dotazu jako JSON pro webovou aplikaci nebo přidat datové struktury JSON do řádků a sloupců.
Poznámka JSON není v jazyce VBA podporován. Alternativně můžete v jazyce VBA použít jazyk XML pomocí knihovny MSXML.
Další informace najdete v článku Data JSON na SQL Serveru.
Zdroje informací
Teď je skvělý čas na získání dalších informací o SQL Serveru a Transact SQL (TSQL). Jak jste viděli, Access má spousta funkcí, ale existují i funkce, které v Accessu chybí. Pokud chcete prozkoumat další úroveň, tady je několik studijních materiálů:
|
Materiál |
Popis |
|
Video kurz |
|
|
Tutoriály k SQL Serveru 2017 |
|
|
Praktické učení pro Azure |
|
|
Staňte se odborníkem |
|
|
Hlavní úvodní stránka |
|
|
Informace nápovědy |
|
|
Informace nápovědy |
|
|
Přehled cloudu |
|
|
Vizuální přehled nových funkcí |
|
|
Souhrn funkcí podle verzí |
|
|
Stažení SQL Serveru Express 2017 |
|
|
Stažení ukázkových databází |









